open_flamingo
2.0.1
Papier | Articles de blog: 1, 2 | Démo
Bienvenue à notre mise en œuvre open source du Flamingo de DeepMind!
Dans ce référentiel, nous fournissons une implémentation Pytorch pour la formation et l'évaluation des modèles OpenFlamingo. Si vous avez des questions, n'hésitez pas à ouvrir un problème. Nous accueillons également les contributions!
Pour installer le package dans un environnement existant, exécutez
pip install open-flamingo
ou pour créer un environnement conda pour exécuter Openflamingo, exécutez
conda env create -f environment.yml
Pour installer une formation ou évaluer les dépendances, exécutez l'une des deux premières commandes. Pour tout installer, exécutez la troisième commande.
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
Il y a trois fichiers requirements.txt :
requirements.txtrequirements-training.txtrequirements-eval.txt Selon votre cas d'utilisation, vous pouvez installer n'importe lequel avec pip install -r <requirements-file.txt> . Le fichier de base ne contient que les dépendances nécessaires pour exécuter le modèle.
Nous utilisons des crochets pré-comités pour aligner le formatage avec les vérifications du référentiel.
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
Ensuite, chaque fois que nous exécutons Git Commit, les chèques sont effectués. Si les fichiers sont reformatés par les crochets, exécutez git add pour vos fichiers modifiés et git commit à nouveau
OpenFlamingo est un modèle de langage multimodal qui peut être utilisé pour une variété de tâches. Il est formé sur un grand ensemble de données multimodal (par exemple, C4 multimodal) et peut être utilisé pour générer du texte conditionné sur des images / texte entrelacés. Par exemple, OpenFlamingo peut être utilisé pour générer une légende pour une image, ou pour générer une question compte tenu d'une image et d'un passage de texte. L'avantage de cette approche est que nous sommes en mesure de nous adapter rapidement aux nouvelles tâches en utilisant l'apprentissage en contexte.
OpenFlamingo combine un encodeur de vision pré-étendu et un modèle de langue utilisant des couches d'attention. L'architecture du modèle est illustrée ci-dessous.
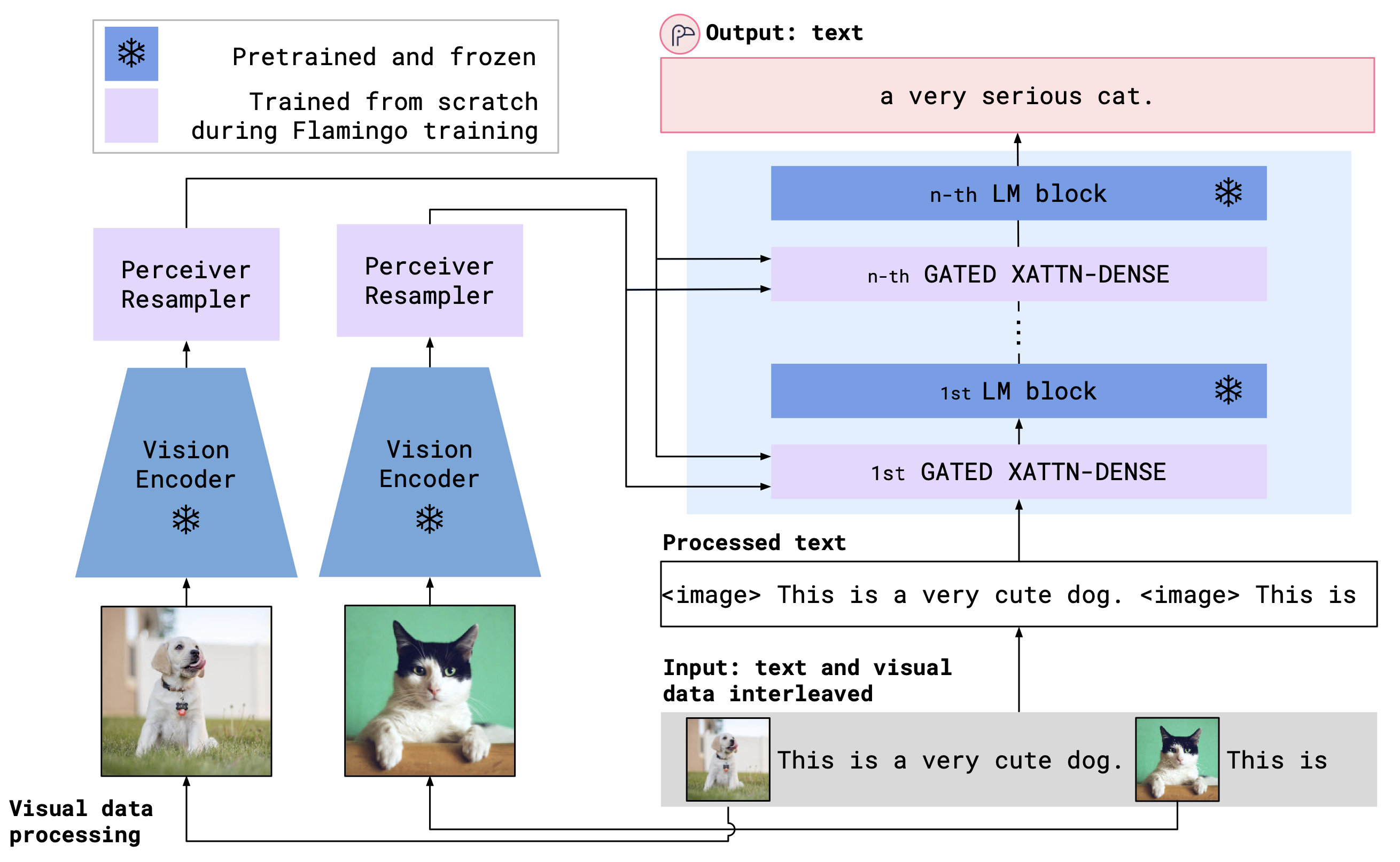 Crédit: Flamingo
Crédit: Flamingo
Nous soutenons les encodeurs de vision pré-étendus du package d'OpenClip, qui comprend des modèles pré-entraînés d'Openai. Nous soutenons également les modèles de langage pré-élaboré du package transformers , tels que MPT, Redpajama, Llama, Opt, GPT-Neo, GPT-J et Pythia.
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)Jusqu'à présent, nous avons formé les modèles Openflamingo suivants.
| # Params | Modèle de langue | Encodeur de vision | Intervalle xattn * | Cidre de coco 4 | Précision VQav2 à 4 tirs | Poids |
|---|---|---|---|---|---|---|
| 3B | Anas-Awadalla / MPT-1b-redpajama-200b | Openai Clip Vit-L / 14 | 1 | 77.3 | 45.8 | Lien |
| 3B | Anas-Awadalla / MPT-1B-REDPAJAMA-200B-DOLLY | Openai Clip Vit-L / 14 | 1 | 82.7 | 45.7 | Lien |
| 4B | ensemblecomputer / redpajama-incite-bas-3b-v1 | Openai Clip Vit-L / 14 | 2 | 81.8 | 49.0 | Lien |
| 4B | ensemblecomputer / redpajama-incite-instruct-3b-v1 | Openai Clip Vit-L / 14 | 2 | 85.8 | 49.0 | Lien |
| 9b | Anas-Awadalla / MPT-7B | Openai Clip Vit-L / 14 | 4 | 89.0 | 54.8 | Lien |
* L'intervalle XATTN fait référence à l'argument --cross_attn_every_n_layers .
Remarque: Dans le cadre de notre version V2, nous avons obsolète un précédent point de contrôle basé sur LLAMA. Cependant, vous pouvez continuer à utiliser notre ancien point de contrôle à l'aide de la nouvelle base de code.
Pour instancier un modèle OpenFlamingo avec l'un de nos poids libérés, initialisez le modèle comme ci-dessus et utilisez le code suivant.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )Vous trouverez ci-dessous un exemple de génération de texte conditionné sur des images / texte entrelacés. Essayons en particulier le sous-titrage de l'image à quelques coups.
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) Nous fournissons des scripts de formation dans open_flamingo/train . Nous fournissons un exemple de script Slurm dans open_flamingo/scripts/run_train.py , ainsi que l'exemple de commande suivante:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
Remarque: Le code de modélisation de la base et de l'instruction MPT-1B n'accepte pas les labels KWARG ou calcule la perte de transropy directe directement dans forward() , comme prévu par notre base de code. Nous suggérons d'utiliser une version modifiée des modèles MPT-1B trouvés ici et ici.
Pour plus de détails, consultez notre formation de formation.
Un exemple de script d'évaluation est sur open_flamingo/scripts/run_eval.sh . Veuillez consulter notre lecture d'évaluation pour plus de détails.
Pour exécuter des évaluations sur OKVQA, vous devrez exécuter la commande suivante:
import nltk
nltk.download('wordnet')
OpenFlamingo est développé par:
Anas Awadalla *, Irena Gao *, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Schmidt.
L'équipe provient principalement de l'Université de Washington, Stanford, AI2, UCSB et Google.
Ce code est basé sur l'implémentation de Flamingo de Lucidrains et la rémunération Flamingo-min de David Hansmair. Merci d'avoir rendu votre code public! Nous remercions également l'équipe OpenClip car nous utilisons leur code de chargement de données et nous nous inspirons de leur conception de bibliothèque.
Nous tenons également à remercier Jean-Baptiste Alayrac et Antoine Mich pour leurs conseils, Rohan Taori, Nicholas Schiefer, Deep Ganguli, Thomas Liao, Tatsunori Hashimoto et Nicholas Carlini pour leur aide à évaluer ces modèles de sécurité.
Si vous avez trouvé ce référentiel utile, veuillez envisager de citer:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


