open_flamingo
2.0.1
กระดาษ | บล็อกโพสต์: 1, 2 | การสาธิต
ยินดีต้อนรับสู่การใช้งาน Flamingo ของ DeepMind ของ DeepMind!
ในที่เก็บนี้เราให้การใช้งาน Pytorch สำหรับการฝึกอบรมและประเมินโมเดล OpenFlamingo หากคุณมีคำถามใด ๆ โปรดเปิดปัญหา นอกจากนี้เรายังยินดีต้อนรับผลงาน!
ในการติดตั้งแพ็คเกจในสภาพแวดล้อมที่มีอยู่ให้เรียกใช้
pip install open-flamingo
หรือเพื่อสร้างสภาพแวดล้อม conda สำหรับการใช้ OpenFlamingo ให้เรียกใช้
conda env create -f environment.yml
ในการติดตั้งการฝึกอบรมหรือการพึ่งพาการประเมินให้เรียกใช้หนึ่งในสองคำสั่งแรก หากต้องการติดตั้งทุกอย่างให้เรียกใช้คำสั่งที่สาม
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
มีสามไฟล์ requirements.txt . txt:
requirements.txtrequirements-training.txtrequirements-eval.txt ขึ้นอยู่กับกรณีการใช้งานของคุณคุณสามารถติดตั้งสิ่งเหล่านี้ได้ด้วย pip install -r <requirements-file.txt> ไฟล์ฐานมีเฉพาะการพึ่งพาที่จำเป็นสำหรับการเรียกใช้โมเดล
เราใช้ตะขอล่วงหน้าเพื่อจัดรูปแบบกับการตรวจสอบในที่เก็บ
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
จากนั้นทุกครั้งที่เราเรียกใช้ Git Commit การตรวจสอบจะทำงาน หากไฟล์ถูกฟอร์แมตด้วยตะขอให้เรียกใช้ git add สำหรับไฟล์ที่เปลี่ยนแปลงของคุณและ git commit อีกครั้ง
OpenFlamingo เป็นรูปแบบภาษาหลายรูปแบบที่สามารถใช้สำหรับงานที่หลากหลาย ได้รับการฝึกฝนในชุดข้อมูลหลายรูปแบบขนาดใหญ่ (เช่น Multimodal C4) และสามารถใช้ในการสร้างข้อความที่มีเงื่อนไขบนภาพ/ข้อความ interleaved ตัวอย่างเช่น OpenFlamingo สามารถใช้เพื่อสร้างคำบรรยายภาพสำหรับภาพหรือสร้างคำถามที่ได้รับภาพและข้อความ ประโยชน์ของวิธีการนี้คือเราสามารถปรับตัวเข้ากับงานใหม่อย่างรวดเร็วโดยใช้การเรียนรู้ในบริบท
OpenFlamingo รวมตัวเข้ารหัสวิสัยทัศน์ที่ผ่านการฝึกฝนไว้และแบบจำลองภาษาโดยใช้เลเยอร์ความสนใจข้าม สถาปัตยกรรมโมเดลแสดงด้านล่าง
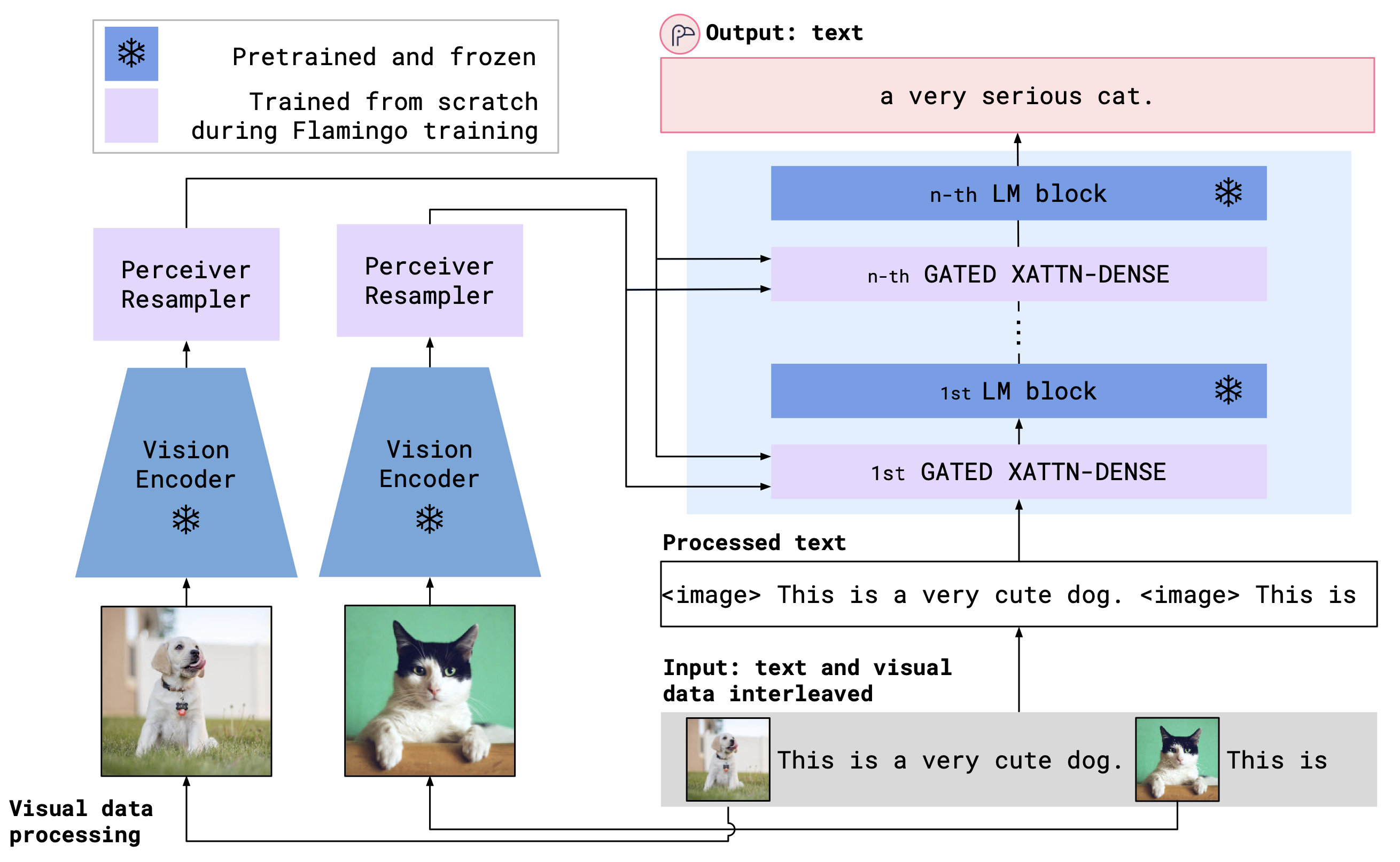 เครดิต: ฟลามิงโก
เครดิต: ฟลามิงโก
เราสนับสนุนการเข้ารหัสวิสัยทัศน์ที่ผ่านการฝึกฝนจากแพ็คเกจ OpenClip ซึ่งรวมถึงโมเดลที่ผ่านการฝึกฝนของ OpenAI นอกจากนี้เรายังสนับสนุนโมเดลภาษาที่ผ่านการฝึกอบรมจากแพ็คเกจ transformers เช่น MPT, Redpajama, Llama, OPT, GPT-NEO, GPT-J และ Pythia
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)เราได้ฝึกอบรมโมเดล OpenFlamingo ต่อไปนี้
| # params | รูปแบบภาษา | ตัวเข้ารหัสวิสัยทัศน์ | ช่วงเวลา Xattn* | ไซเดอร์ Coco 4-shot | ความแม่นยำของ VQAV2 4-shot | น้ำหนัก |
|---|---|---|---|---|---|---|
| 3B | Anas-Awadalla/MPT-1B-REDPAJAMA-200B | Openai Clip Vit-L/14 | 1 | 77.3 | 45.8 | การเชื่อมโยง |
| 3B | Anas-Awadalla/MPT-1B-REDPAJAMA-200B-DOLLY | Openai Clip Vit-L/14 | 1 | 82.7 | 45.7 | การเชื่อมโยง |
| 4B | Computer/Redpajama-incite-base-3b-v1 | Openai Clip Vit-L/14 | 2 | 81.8 | 49.0 | การเชื่อมโยง |
| 4B | Computer/Redpajama-incite-Instruct-3B-V1 | Openai Clip Vit-L/14 | 2 | 85.8 | 49.0 | การเชื่อมโยง |
| 9b | Anas-Awadalla/MPT-7B | Openai Clip Vit-L/14 | 4 | 89.0 | 54.8 | การเชื่อมโยง |
* ช่วงเวลา XATTN หมายถึงอาร์กิวเมนต์ --cross_attn_every_n_layers
หมายเหตุ: ในฐานะส่วนหนึ่งของการเปิดตัว V2 ของเราเราได้เลิกด่านตรวจสอบก่อนหน้านี้ อย่างไรก็ตามคุณสามารถใช้จุดตรวจสอบรุ่นเก่าของเราต่อไปโดยใช้ CodeBase ใหม่
ในการสร้างอินสแตนซ์โมเดล OpenFlamingo ด้วยหนึ่งในน้ำหนักที่ปล่อยออกมาของเราให้เริ่มต้นโมเดลดังกล่าวข้างต้นและใช้รหัสต่อไปนี้
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )ด้านล่างเป็นตัวอย่างของการสร้างข้อความที่มีเงื่อนไขบนภาพ/ข้อความ interleaved โดยเฉพาะอย่างยิ่งลองคำบรรยายภาพสองสามภาพ
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) เราให้บริการสคริปต์การฝึกอบรมใน open_flamingo/train เราให้ตัวอย่างสคริปต์ slurm ใน open_flamingo/scripts/run_train.py รวมถึงคำสั่งตัวอย่างต่อไปนี้:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
หมายเหตุ: ฐาน MPT-1B และโค้ดการสร้างแบบจำลองไม่ยอมรับ labels KWARG หรือคำนวณการสูญเสียข้าม-เอนโทรปีโดยตรงภายใน forward() ตามที่คาดไว้โดย codebase ของเรา เราขอแนะนำให้ใช้รุ่น MPT-1B ที่แก้ไขแล้วที่นี่และที่นี่
สำหรับรายละเอียดเพิ่มเติมดู readme การฝึกอบรมของเรา
ตัวอย่างสคริปต์การประเมินผลอยู่ที่ open_flamingo/scripts/run_eval.sh โปรดดูรายละเอียดเพิ่มเติมเกี่ยวกับการประเมินผลของเรา
ในการเรียกใช้การประเมินผลบน OKVQA คุณจะต้องเรียกใช้คำสั่งต่อไปนี้:
import nltk
nltk.download('wordnet')
OpenFlamingo ได้รับการพัฒนาโดย:
Anas Awadalla*, Irena Gao*, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith ชมิดท์
ทีมงานส่วนใหญ่มาจากมหาวิทยาลัยวอชิงตันสแตนฟอร์ด, AI2, UCSB และ Google
รหัสนี้ขึ้นอยู่กับการใช้งาน Flamingo ของ Lucidrains และ Flamingo-Mini Repo ของ David Hansmair ขอบคุณที่ทำให้รหัสของคุณเป็นสาธารณะ! นอกจากนี้เรายังขอขอบคุณทีม OpenClip ในขณะที่เราใช้รหัสการโหลดข้อมูลของพวกเขาและรับแรงบันดาลใจจากการออกแบบห้องสมุดของพวกเขา
นอกจากนี้เรายังขอขอบคุณ Jean-Baptiste Alayrac และ Antoine Miech สำหรับคำแนะนำของพวกเขา Rohan Taori, Nicholas Schiefer, Deep Ganguli, Thomas Liao, Tatsunori Hashimoto และ Nicholas Carlini
หากคุณพบว่าที่เก็บนี้มีประโยชน์โปรดพิจารณาอ้าง:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


