open_flamingo
2.0.1
論文|ブログ投稿:1、2 |デモ
Deepmind's Flamingoのオープンソースの実装へようこそ!
このリポジトリでは、OpenFlamingoモデルをトレーニングおよび評価するためのPytorch実装を提供します。ご質問がある場合は、お気軽に問題を開いてください。貢献も歓迎します!
既存の環境にパッケージをインストールするには、実行します
pip install open-flamingo
または、OpenFlamingoを実行するためのコンドラ環境を作成するには、実行してください
conda env create -f environment.yml
トレーニングまたは評価依存関係をインストールするには、最初の2つのコマンドのいずれかを実行します。すべてをインストールするには、3番目のコマンドを実行します。
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
3つのrequirements.txtがあります。txtファイル:
requirements.txtrequirements-training.txtrequirements-eval.txtユースケースに応じて、 pip install -r <requirements-file.txt>にこれらのいずれかをインストールできます。ベースファイルには、モデルの実行に必要な依存関係のみが含まれます。
事前コミットフックを使用して、リポジトリのチェックとフォーマットを調整します。
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
その後、Git Commitを実行するたびに、チェックが実行されます。ファイルがフックによって再フォーマットされている場合は、変更されたファイルのためにgit addを実行し、再びgit commit
OpenFlamingoは、さまざまなタスクに使用できるマルチモーダル言語モデルです。大規模なマルチモーダルデータセット(マルチモーダルC4など)でトレーニングされており、インターリーブ画像/テキストに条件付けられたテキストを生成するために使用できます。たとえば、OpenFlamingoを使用して、画像のキャプションを生成したり、画像とテキストパッセージを与えられた質問を生成したりできます。このアプローチの利点は、コンテキスト学習を使用して新しいタスクに迅速に適応できることです。
OpenFlamingoは、Cross Anternest Layersを使用して、前処理されたビジョンエンコーダーと言語モデルを組み合わせています。モデルアーキテクチャを以下に示します。
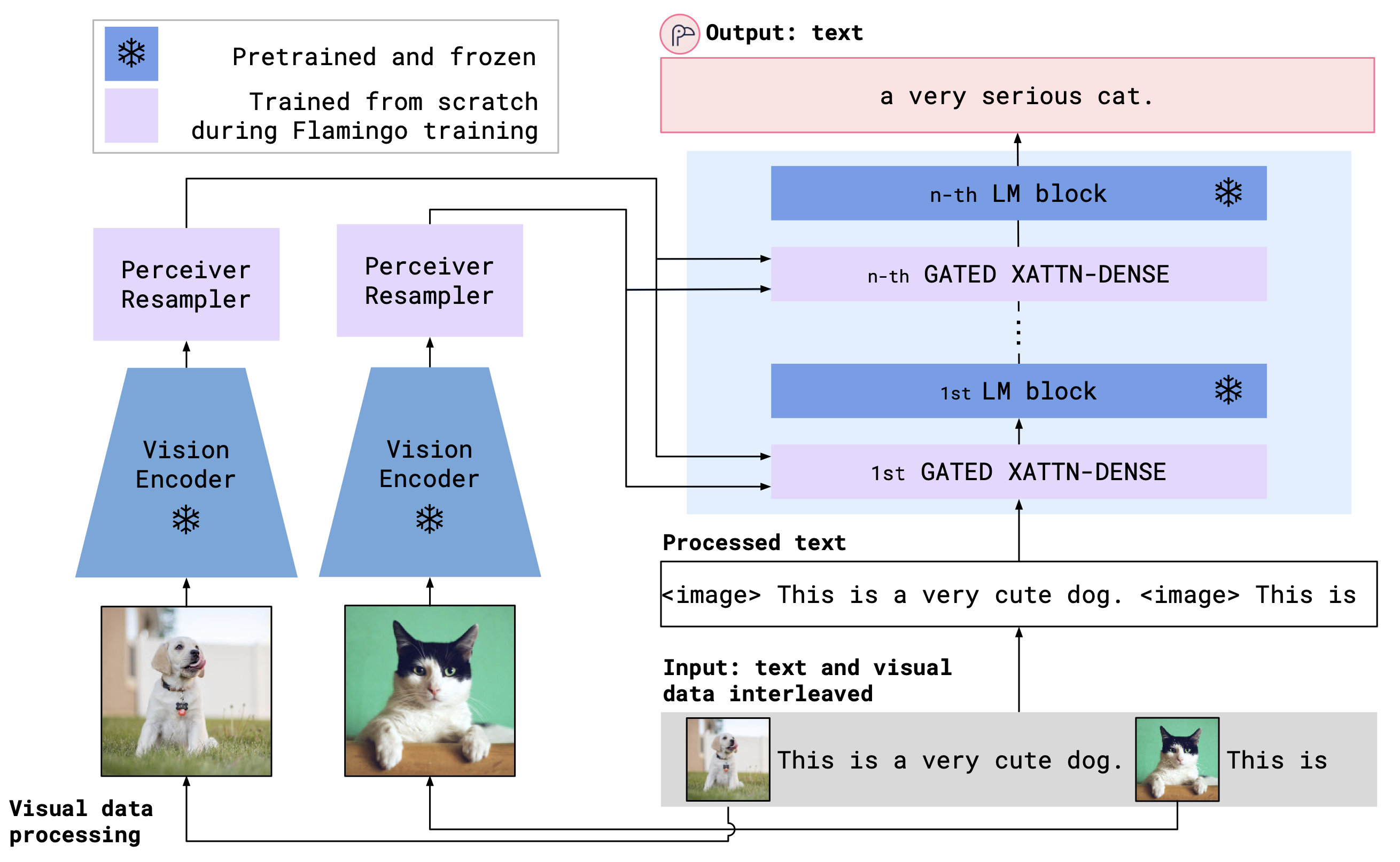 クレジット:フラミンゴ
クレジット:フラミンゴ
OpenAIの前提条件モデルを含むOpenCLipパッケージから、前処理されたビジョンエンコーダーをサポートしています。また、MPT、Redpajama、Llama、Opt、GPT-Neo、GPT-J、Pythiaモデルなど、 transformersパッケージからの前提条件の言語モデルもサポートしています。
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)これまでのところ、次のOpenFlamingoモデルをトレーニングしています。
| #params | 言語モデル | ビジョンエンコーダー | xattn interval* | ココ4ショットサイダー | VQAV2 4ショット精度 | ウェイト |
|---|---|---|---|---|---|---|
| 3b | Anas-Awadalla/MPT-1B-Redpajama-200b | Openai Clip Vit-L/14 | 1 | 77.3 | 45.8 | リンク |
| 3b | Anas-Awadalla/MPT-1B-Redpajama-200b-Dolly | Openai Clip Vit-L/14 | 1 | 82.7 | 45.7 | リンク |
| 4b | Copinescomputer/RedPajama-Incite-Base-3B-V1 | Openai Clip Vit-L/14 | 2 | 81.8 | 49.0 | リンク |
| 4b | CointedComputer/RedPajama-Incite-Instruct-3B-V1 | Openai Clip Vit-L/14 | 2 | 85.8 | 49.0 | リンク |
| 9b | Anas-Awadalla/MPT-7B | Openai Clip Vit-L/14 | 4 | 89.0 | 54.8 | リンク |
* Xattn間隔とは、 --cross_attn_every_n_layers引数を指します。
注:V2リリースの一環として、以前のLlamaベースのチェックポイントを非難しました。ただし、新しいコードベースを使用して古いチェックポイントを引き続き使用できます。
リリースされた重みの1つを使用してOpenFlamingoモデルをインスタンス化するには、上記のようにモデルを初期化し、次のコードを使用します。
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )以下は、インターリーブ画像/テキストに条件付けられたテキストを生成する例です。特に、少数のショット画像キャプションを試してみましょう。
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ]))open_flamingo/trainでトレーニングスクリプトを提供します。 open_flamingo/scripts/run_train.pyでSlurmスクリプトの例と、次の例コマンドを提供します。
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
注:MPT-1Bベースおよび指示モデリングコードは、コードベースで予想されるように、 forward()内に直接クロピアロピー損失を直接計算するlabelsを受け入れません。こことここにあるMPT-1Bモデルの変更されたバージョンを使用することをお勧めします。
詳細については、トレーニングREADMEをご覧ください。
例の評価スクリプトはopen_flamingo/scripts/run_eval.shにあります。詳細については、評価readmeをご覧ください。
OKVQAで評価を実行するには、次のコマンドを実行する必要があります。
import nltk
nltk.download('wordnet')
OpenFlamingoは次のように開発されています。
Anas Awadalla*、Irena Gao*、Joshua Gardner、Jack Hessel、Yusuf Hanafy、Wanrong Zhu、Kalyani Marathe、Yonatan Bitton、Samir Gadre、Shiori Sagawa、Jenia Jitsev、Simon Kornblith、Panルートヴィヒ・シュミット。
チームは主にワシントン大学、スタンフォード大学、AI2、UCSB、およびGoogleから来ています。
このコードは、LucidrainsのFlamingo実装とDavid HansmairのFlamingo-Mini Repoに基づいています。コードを公開していただきありがとうございます!また、データ読み込みコードを使用し、ライブラリデザインからインスピレーションを得ているため、OpenCLipチームに感謝します。
また、Jean-Baptiste AlayracとAntoine Miechのアドバイスについても感謝したいと思います。彼らのアドバイス、Rohan Taori、Nicholas Schiefer、Deep Ganguli、Thomas Liao、Tatsunori Hashimoto、およびNicholas Carliniは、リリースの安全性のリスクを評価し、これらのモデルの安全性を高めるための安定性を確保するための支援を受けています。
このリポジトリが便利だと思った場合は、引用を検討してください。
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


