open_flamingo
2.0.1
ورقة | منشورات المدونة: 1 ، 2 | العرض التوضيحي
مرحبًا بك في تنفيذ المصدر المفتوح لـ DeepMind's Flamingo!
في هذا المستودع ، نقدم تطبيق Pytorch للتدريب وتقييم نماذج OpenFlamingo. إذا كان لديك أي أسئلة ، فلا تتردد في فتح مشكلة. نرحب أيضًا بالمساهمات!
لتثبيت الحزمة في بيئة موجودة ، قم بتشغيل
pip install open-flamingo
أو لإنشاء بيئة كوندا لتشغيل OpenFlamingo ، تشغيل
conda env create -f environment.yml
لتثبيت التدريب أو التبعيات EVAL ، قم بتشغيل أحد الأوامر الأولين. لتثبيت كل شيء ، قم بتشغيل الأمر الثالث.
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
هناك ثلاث requirements.txt . ملفات txt:
requirements.txtrequirements-training.txtrequirements-eval.txt اعتمادًا على حالة الاستخدام الخاصة بك ، يمكنك تثبيت أي من هذه مع pip install -r <requirements-file.txt> . يحتوي الملف الأساسي على التبعيات اللازمة فقط لتشغيل النموذج.
نحن نستخدم السنانير قبل الالتزام لمحاذاة التنسيق مع الشيكات في المستودع.
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
ثم في كل مرة نقوم بتشغيل GIT التزام ، يتم تشغيل الشيكات. إذا تم إعادة تنسيق الملفات بواسطة السنانير ، فقم بتشغيل git add للملفات التي تم تغييرها و git commit
OpenFlamingo هو نموذج لغة متعددة الوسائط يمكن استخدامه لمجموعة متنوعة من المهام. يتم تدريبه على مجموعة بيانات متعددة الوسائط كبيرة (مثل C4 متعددة الوسائط) ويمكن استخدامها لإنشاء نص مشروط على الصور/النص المتشابكة. على سبيل المثال ، يمكن استخدام OpenFlamingo لإنشاء تعليق لصورة ، أو لإنشاء سؤال أعطى صورة وممر نص. تتمثل فائدة هذا النهج في أننا قادرون على التكيف بسرعة مع المهام الجديدة باستخدام التعلم داخل السياق.
يجمع OpenFlamingo بين تشفير رؤية مسبق ونموذج لغة باستخدام طبقات الانتباه المتقاطعة. يظهر بنية النموذج أدناه.
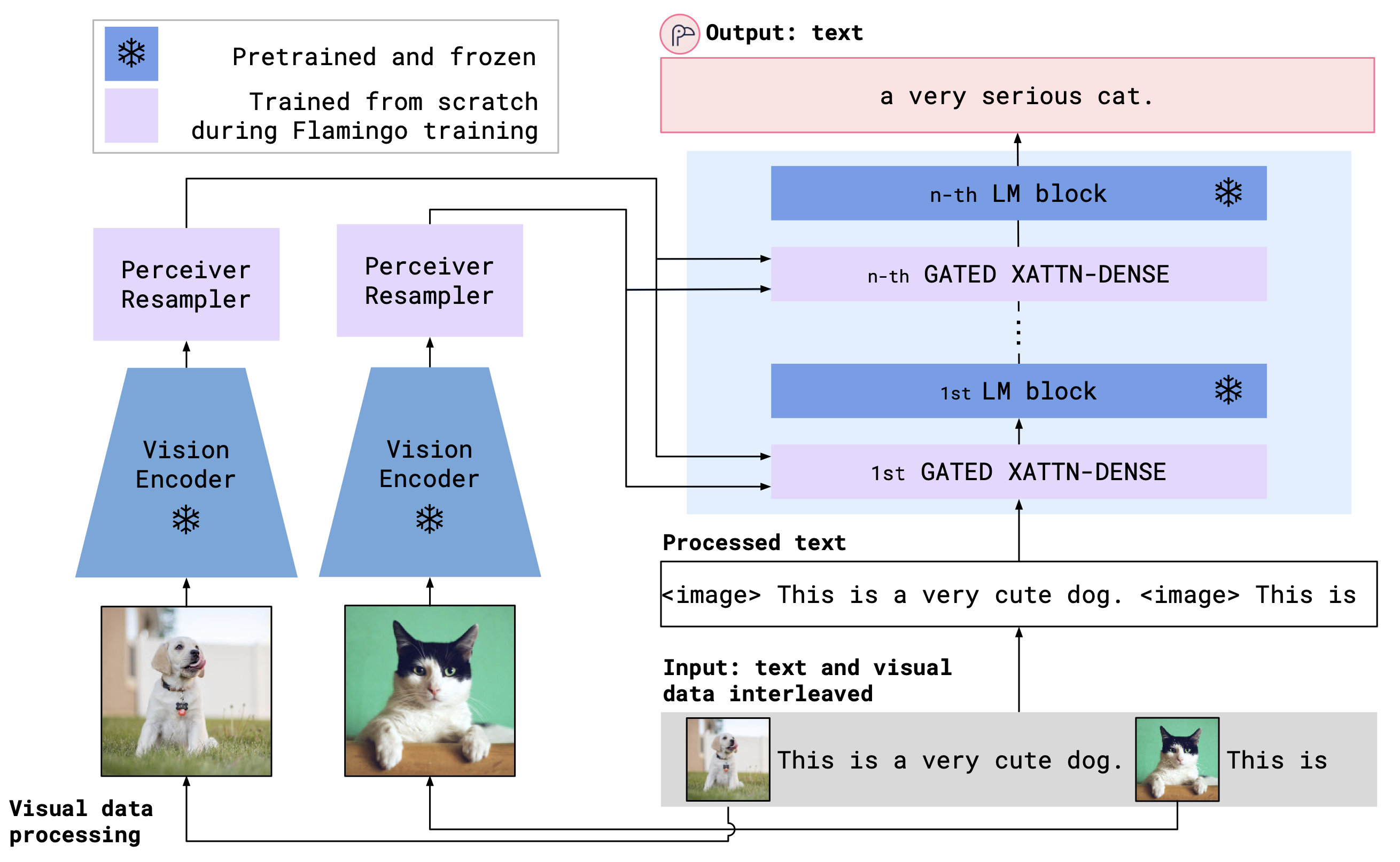 الائتمان: فلامنغو
الائتمان: فلامنغو
نحن ندعم ترميزات الرؤية المسبقة من حزمة OpenClip ، والتي تشمل نماذج Openai المسبقة. نحن ندعم أيضًا نماذج اللغة المسبقة من حزمة transformers ، مثل MPT و Redpajama و Llama و OPT و GPT-NEO و GPT-J و Pythia.
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)لقد قمنا بتدريب نماذج OpenFlamingo التالية حتى الآن.
| # params | نموذج اللغة | تشفير الرؤية | فاصل Xattn* | Coco 4-Shot Cider | دقة VQAV2 4-Shot | الأوزان |
|---|---|---|---|---|---|---|
| 3 ب | Anas-Awadalla/MPT-1B-Redpajama-200b | Openai Clip Vit-L/14 | 1 | 77.3 | 45.8 | وصلة |
| 3 ب | Anas-Awadalla/MPT-1B-Redpajama-200b-Dolly | Openai Clip Vit-L/14 | 1 | 82.7 | 45.7 | وصلة |
| 4 ب | معا computer/redpajama-incite-base-3b-v1 | Openai Clip Vit-L/14 | 2 | 81.8 | 49.0 | وصلة |
| 4 ب | معا computer/redpajama-incite-instruct-3b-v1 | Openai Clip Vit-L/14 | 2 | 85.8 | 49.0 | وصلة |
| 9 ب | Anas-Awadalla/MPT-7B | Openai Clip Vit-L/14 | 4 | 89.0 | 54.8 | وصلة |
* يشير فاصل Xattn إلى الوسيطة --cross_attn_every_n_layers
ملاحظة: كجزء من إصدار V2 الخاص بنا ، قمنا بإهمال نقطة تفتيش سابقة قائمة على Llama. ومع ذلك ، يمكنك الاستمرار في استخدام نقطة التفتيش القديمة الخاصة بنا باستخدام قاعدة الكود الجديدة.
لإنشاء إنشاء نموذج OpenFlamingo مع أحد أوزاننا المنصوص عليها ، قم بتهيئة النموذج على النحو الوارد أعلاه واستخدم الكود التالي.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )فيما يلي مثال على إنشاء نص مشروط على الصور/النص المتشابكة. على وجه الخصوص ، دعنا نحاول تسميات تسميات قليلة لطلاقة.
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) نحن نقدم البرامج النصية التدريبية في open_flamingo/train . نحن نقدم مثالًا على Slurm Script في open_flamingo/scripts/run_train.py ، بالإضافة إلى الأمر التالي:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
ملاحظة: لا تقبل قاعدة MPT-1B ورمز النمذجة الإرشاد labels KWARG أو حساب فقدان الإدخال المتقاطع مباشرة داخل forward() ، كما هو متوقع بواسطة قاعدة الكود الخاصة بنا. نقترح استخدام نسخة معدلة من نماذج MPT-1B الموجودة هنا وهنا.
لمزيد من التفاصيل ، راجع تدريبنا ReadMe.
يوجد مثال على برنامج التقييم في open_flamingo/scripts/run_eval.sh . يرجى الاطلاع على تقييمنا ReadMe لمزيد من التفاصيل.
لتشغيل التقييمات على OKVQA ، ستحتاج إلى تشغيل الأمر التالي:
import nltk
nltk.download('wordnet')
تم تطوير OpenFlamingo بواسطة:
Anas Awadalla*، Irena Gao*، Joshua Gardner ، Jack Hessel ، Yusuf Hanafy ، Wanrong Zhu ، Kalyani Marathe ، Yonatan Bitton ، Samir Gadre ، Shiori Sagawa ، Jenia Jitsev ، Simon Kornblith ، Pang Wei Koh ، Gabriel Ilhco.
ينتمي الفريق في المقام الأول من جامعة واشنطن وستانفورد و AI2 و UCSB و Google.
يعتمد هذا الرمز على تطبيق Flamingo لـ LucidRains و David Hansmair's Flamingo-Mini Repo. شكرا لك على جعل رمزك علني! نشكر أيضًا فريق OpenClip ونحن نستخدم رمز تحميل البيانات الخاص بهم ونستلهم من تصميم المكتبات.
نود أيضًا أن نشكر جان بابتيست ألايراك وأنطوان ميتش على نصيحتهما ، روهان تاوري ، ونيكولاس شيفر ، وديب جانجولي ، وتوماس لياو ، وتاتسونوري هاشموتو ، ونيكولاس كارلين لمساعدتهم في تقييم مخاطر السلامة لإصدارنا ، إلى الاستقرار AI لتوفير الموارد لتجهيز هذه النماذج.
إذا وجدت هذا المستودع مفيدًا ، فيرجى التفكير في:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


