open_flamingo
2.0.1
Papel | Publicaciones de blog: 1, 2 | Manifestación
¡Bienvenido a nuestra implementación de código abierto de Deepmind's Flamingo!
En este repositorio, proporcionamos una implementación de Pytorch para capacitar y evaluar modelos OpenFlamingo. Si tiene alguna pregunta, no dude en abrir un problema. ¡También damos la bienvenida a las contribuciones!
Para instalar el paquete en un entorno existente, ejecute
pip install open-flamingo
o para crear un entorno de condición para ejecutar OpenFlamingo, ejecute
conda env create -f environment.yml
Para instalar dependencias de capacitación o evaluación, ejecute uno de los dos primeros comandos. Para instalar todo, ejecute el tercer comando.
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
Hay tres requirements.txt .
requirements.txtrequirements-training.txtrequirements-eval.txt Dependiendo de su caso de uso, puede instalar cualquiera de estos con pip install -r <requirements-file.txt> . El archivo base contiene solo las dependencias necesarias para ejecutar el modelo.
Utilizamos ganchos previos al comercio para alinear el formato con las verificaciones en el repositorio.
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
Luego, cada vez que ejecutamos Git Commit, se ejecutan los cheques. Si los archivos son reformateados por los ganchos, ejecute git add para sus archivos cambiados y git commit Nuevamente
OpenFlamingo es un modelo de lenguaje multimodal que puede usarse para una variedad de tareas. Está entrenado en un gran conjunto de datos multimodal (por ejemplo, multimodal C4) y puede usarse para generar texto condicionado en imágenes/texto intercalados. Por ejemplo, OpenFlamingo se puede usar para generar un título para una imagen, o para generar una pregunta dada una imagen y un pasaje de texto. El beneficio de este enfoque es que podemos adaptarnos rápidamente a nuevas tareas utilizando el aprendizaje en contexto.
OpenFlamingo combina un codificador de visión previa a la aparición y un modelo de lenguaje que utiliza capas de atención cruzada. La arquitectura del modelo se muestra a continuación.
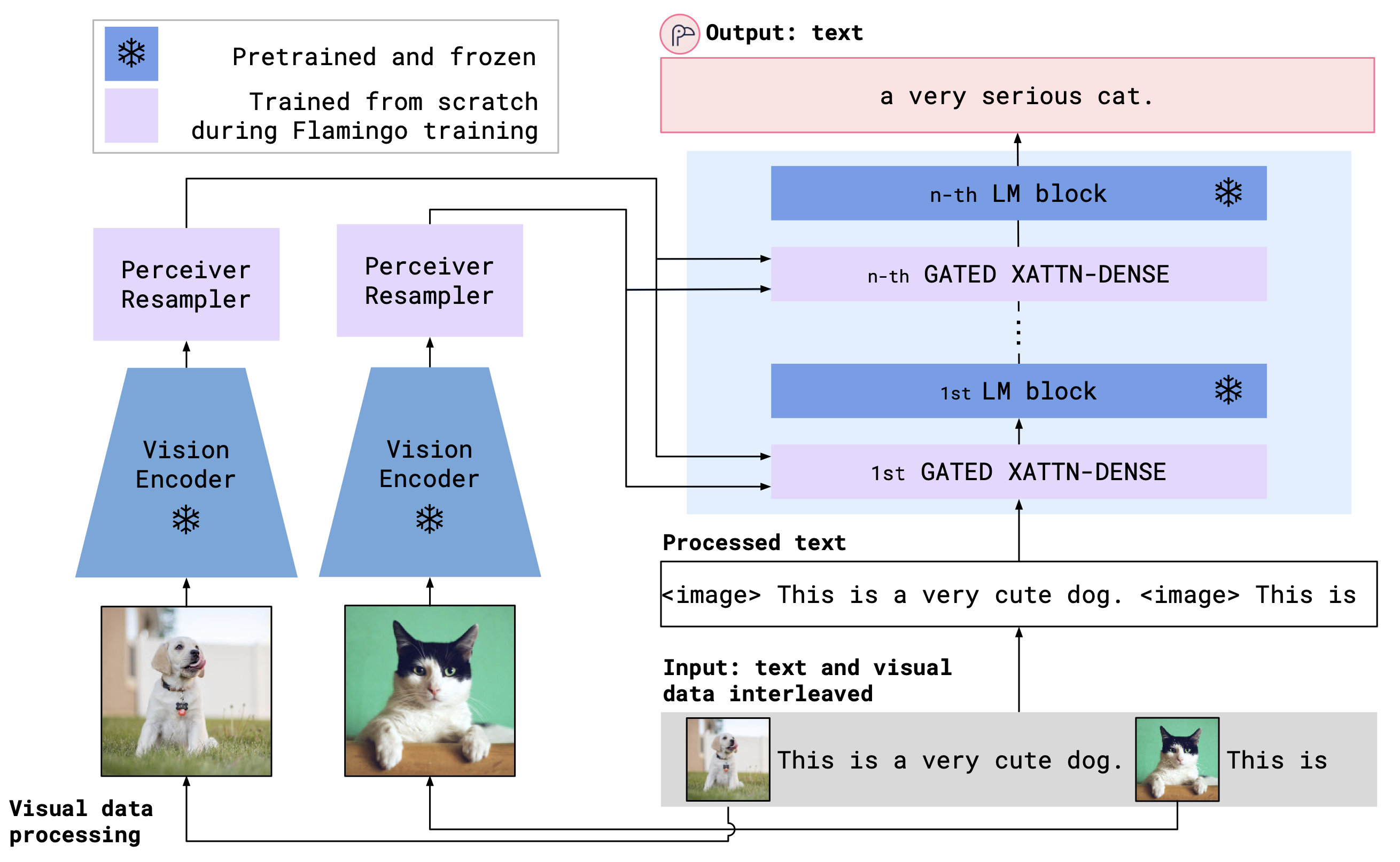 Crédito: Flamingo
Crédito: Flamingo
Apoyamos a los codificadores de visión previos al paquete OpenClip, que incluye los modelos previos a la pretrada de OpenAI. También apoyamos modelos de lenguaje previos al paquete transformers , como MPT, Redpajama, Llama, Opt, GPT-Neo, GPT-J y Pythia Models.
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)Hemos entrenado los siguientes modelos OpenFlamingo hasta ahora.
| # parámetros | Modelo | Codificador de visión | Intervalo Xattn* | Sidra de 4-shot de coco | Vqav2 4-shot precisión | Pesas |
|---|---|---|---|---|---|---|
| 3B | ANAS-AWADALLA/MPT-1B-REDPAJAMA-200B | OpenAi Clip Vit-L/14 | 1 | 77.3 | 45.8 | Enlace |
| 3B | ANAS-AWADALLA/MPT-1B-REDPAJAMA-200B-DOLLY | OpenAi Clip Vit-L/14 | 1 | 82.7 | 45.7 | Enlace |
| 4b | JUNSCOMPUTER/REDPAJAMA-INCITE-BASE-3B-V1 | OpenAi Clip Vit-L/14 | 2 | 81.8 | 49.0 | Enlace |
| 4b | juntas computer/redpajama-incite-instructo-3b-v1 | OpenAi Clip Vit-L/14 | 2 | 85.8 | 49.0 | Enlace |
| 9B | ANAS-AWADALLA/MPT-7B | OpenAi Clip Vit-L/14 | 4 | 89.0 | 54.8 | Enlace |
* El intervalo Xattn se refiere al argumento --cross_attn_every_n_layers .
Nota: Como parte de nuestro lanzamiento de V2, hemos desaprobado un punto de control anterior basado en llamas. Sin embargo, puede continuar utilizando nuestro punto de control anterior utilizando la nueva base de código.
Para instanciar un modelo OpenFlamingo con uno de nuestros pesos liberados, inicialice el modelo como se indicó anteriormente y use el siguiente código.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )A continuación se muestra un ejemplo de texto de generación de texto condicionado en imágenes/texto entrelazados. En particular, intentemos un subtítulos de imágenes de pocos disparos.
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) Proporcionamos scripts de capacitación en open_flamingo/train . Proporcionamos un script de slurm de ejemplo en open_flamingo/scripts/run_train.py , así como el siguiente comando de ejemplo:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
NOTA: La base MPT-1B e instructa el código de modelado no acepta las labels KWARG o calculan la pérdida de entropía cruzada directamente dentro de forward() , como se esperaba por nuestra base de código. Sugerimos usar una versión modificada de los modelos MPT-1B que se encuentran aquí y aquí.
Para más detalles, consulte nuestro Readme de capacitación.
Un script de evaluación de ejemplo es en open_flamingo/scripts/run_eval.sh . Consulte nuestro Readme de evaluación para obtener más detalles.
Para ejecutar evaluaciones en OKVQA, deberá ejecutar el siguiente comando:
import nltk
nltk.download('wordnet')
OpenFlamingo es desarrollado por:
Anas awadalla*, Irena Gao*, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblit Schmidt.
El equipo es principalmente de la Universidad de Washington, Stanford, AI2, UCSB y Google.
Este código se basa en la implementación de flamencos de Lucidrains y el repositorio Flamingo-Mini de David Hansmair. ¡Gracias por hacer público su código! También agradecemos al equipo de OpenClip mientras usamos su código de carga de datos e inspiramos en el diseño de su biblioteca.
También nos gustaría agradecer a Jean-Baptiste Alayrac y Antoine Miech por su consejo, Rohan Taori, Nicholas Schiefer, Ganguli Deep, Thomas Liao, Tatsunori Hashimoto y Nicholas Carlini por su ayuda con la evaluación de los riesgos de seguridad de nuestra liberación y la AI para proporcionarnos recursos de los modelos de entrenamiento.
Si encontró útil este repositorio, considere citar:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


