open_flamingo
2.0.1
Бумага | Сообщения в блоге: 1, 2 | Демо
Добро пожаловать в нашу реализацию с открытым исходным кодом DeepMind's Flamingo!
В этом репозитории мы предоставляем реализацию Pytorch для обучения и оценки моделей OpenFlamingo. Если у вас есть какие -либо вопросы, пожалуйста, не стесняйтесь открыть проблему. Мы также приветствуем взносы!
Чтобы установить пакет в существующей среде, запустите
pip install open-flamingo
или для создания среды Conda для запуска OpenFlamingo, запустите
conda env create -f environment.yml
Чтобы установить обучение или оценить зависимости, запустите одну из первых двух команд. Чтобы все установить, запустите третью команду.
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
Есть три файла requirements.txt :
requirements.txtrequirements-training.txtrequirements-eval.txt В зависимости от вашего варианта использования вы можете установить любое из них с помощью pip install -r <requirements-file.txt> . Базовый файл содержит только зависимости, необходимые для запуска модели.
Мы используем предварительные крючки, чтобы согласовать форматирование с проверками в репозитории.
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
Затем каждый раз, когда мы запускаем GIT Commit, чеки запускаются. Если файлы переформатированы крючками, запустите git add для ваших измененных файлов и git commit
OpenFlamingo - это мультимодальная языковая модель, которую можно использовать для различных задач. Он обучен большому мультимодальному набору данных (например, мультимодальный C4) и может использоваться для создания текста, обусловленного на переоцененных изображениях/текста. Например, OpenFlamingo может использоваться для создания заголовка для изображения или для создания вопроса с учетом изображения и текстового отрывка. Преимущество этого подхода заключается в том, что мы можем быстро адаптироваться к новым задачам, используя встроенное обучение.
OpenFlamingo сочетает в себе кодер видения и модель языка с использованием слоев кросса. Архитектура модели показана ниже.
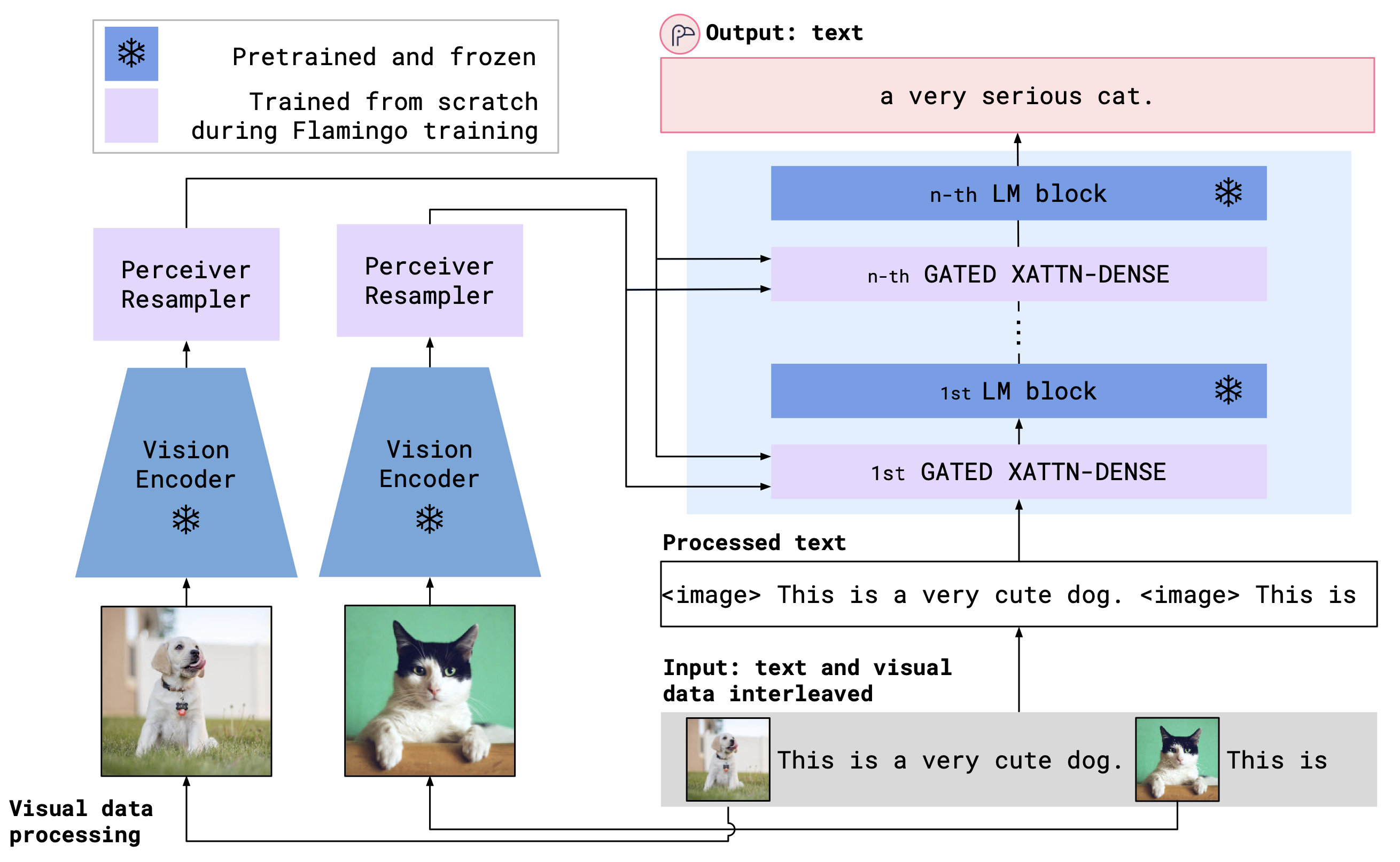 Кредит: Фламинго
Кредит: Фламинго
Мы поддерживаем предварительные кодеры зрения из пакета OpenClip, который включает в себя предварительные модели OpenAI. Мы также поддерживаем предварительные языковые модели из пакета transformers , таких как MPT, Redpajama, Llama, Opt, GPT-Neo, GPT-J и Pythia Models.
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)До сих пор мы обучили следующие модели OpenFlamingo.
| # Params | Языковая модель | Vision Encoder | Интервал Xattn* | Коко 4-выстрел сидр | VQAV2 4-выстрел Точность | Вес |
|---|---|---|---|---|---|---|
| 3B | Anas-Awadalla/MPT-1B-Redpajama-200b | Openai Clip Vit-L/14 | 1 | 77.3 | 45,8 | Связь |
| 3B | Anas-Awadalla/MPT-1B-Redpajama-200b-Dolly | Openai Clip Vit-L/14 | 1 | 82,7 | 45,7 | Связь |
| 4B | Вместе computer/redpajama-incite-base-3b-v1 | Openai Clip Vit-L/14 | 2 | 81.8 | 49,0 | Связь |
| 4B | Вместе computer/redpajama-incite-instruct-3b-v1 | Openai Clip Vit-L/14 | 2 | 85,8 | 49,0 | Связь |
| 9B | Anas-Awadalla/MPT-7B | Openai Clip Vit-L/14 | 4 | 89,0 | 54,8 | Связь |
* Интервал Xattn относится к аргументу --cross_attn_every_n_layers .
Примечание. В рамках нашего релиза V2 мы установили предыдущую контрольную точку на основе ламы. Тем не менее, вы можете продолжать использовать нашу старую контрольную точку, используя новую кодовую базу.
Чтобы создать экземпляр модели OpenFlamingo с одним из наших выпущенных весов, инициализируйте модель, как указано выше, и используйте следующий код.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )Ниже приведен пример генерации текста, обусловленного на переоцененных изображениях/текста. В частности, давайте попробуем несколько выстрелов.
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) Мы предоставляем тренировочные сценарии в open_flamingo/train . Мы приводим пример Slurm Script в open_flamingo/scripts/run_train.py , а также следующую команду:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
ПРИМЕЧАНИЕ. Код базы и инструкта MPT-1B и инструктирование не принимает labels Kwarg или вычисляйте потерю поперечной энтропии непосредственно внутри forward() , как и ожидалось нашей кодовой базой. Мы предлагаем использовать модифицированную версию моделей MPT-1B, найденную здесь и здесь.
Для получения более подробной информации см. Наше обучение.
Примером сценария оценки является open_flamingo/scripts/run_eval.sh . Пожалуйста, смотрите нашу оценку Readme для получения более подробной информации.
Чтобы запустить оценки на OKVQA, вам нужно будет запустить следующую команду:
import nltk
nltk.download('wordnet')
OpenFlamingo разработан:
Анас Авадалла*, Ирена Гао*, Джошуа Гарднер, Джек Хессель, Юсуф Ханафи, Ванронг Чжу, Каляни Марат, Йонатан Биттон, Самир Гадра, Шиора Сагава, Джена Джитнев, Симон Корнблит, Пангэй Ко, Габриэль Илхарка, Миттер -Ворт.
Команда в основном из Университета Вашингтона, Стэнфорда, AI2, UCSB и Google.
Этот код основан на реализации Flamingo Lucidrains и репо фламинго-мини. Спасибо, что обнародовали ваш код! Мы также благодарим команду OpenClip, поскольку мы используем их код загрузки данных и черпаем вдохновение в дизайне библиотеки.
Мы также хотели бы поблагодарить Жана-Батиста Алайрака и Антуана Миха за их совет, Рохан Таори, Николас Шифер, Глубокий Гангули, Томас Ляо, Татсунори Хашимото и Николас Карлини, чтобы оценить риски безопасности нашего освобождения и для стабильности, предоставляя нам ресурсы для приготовления этих моделей.
Если вы нашли этот репозиторий полезным, пожалуйста, рассмотрите возможность ссылаться на:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


