open_flamingo
2.0.1
Kertas | Posting Blog: 1, 2 | Demo
Selamat datang di implementasi open source kami dari DeepMind's Flamingo!
Dalam repositori ini, kami memberikan implementasi Pytorch untuk pelatihan dan mengevaluasi model OpenFlamingo. Jika Anda memiliki pertanyaan, jangan ragu untuk membuka masalah. Kami juga menyambut kontribusi!
Untuk menginstal paket di lingkungan yang ada, jalankan
pip install open-flamingo
Atau untuk menciptakan lingkungan Conda untuk menjalankan OpenFlamingo, jalankan
conda env create -f environment.yml
Untuk menginstal pelatihan atau evaluasi dependensi, jalankan salah satu dari dua perintah pertama. Untuk menginstal semuanya, jalankan perintah ketiga.
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
Ada tiga file requirements.txt :
requirements.txtrequirements-training.txtrequirements-eval.txt Bergantung pada kasing penggunaan Anda, Anda dapat menginstal semua ini dengan pip install -r <requirements-file.txt> . File dasar hanya berisi dependensi yang diperlukan untuk menjalankan model.
Kami menggunakan kait pra-komit untuk menyelaraskan pemformatan dengan cek di repositori.
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
Kemudian setiap kali kita menjalankan Git Commit, cek dijalankan. Jika file diformat ulang oleh kait, jalankan git add untuk file yang Anda ganti dan git commit lagi
OpenFlamingo adalah model bahasa multimodal yang dapat digunakan untuk berbagai tugas. Ini dilatih pada dataset multimodal besar (misalnya multimodal C4) dan dapat digunakan untuk menghasilkan teks yang dikondisikan pada gambar/teks yang diselingi. Misalnya, OpenFlamingo dapat digunakan untuk menghasilkan keterangan untuk suatu gambar, atau untuk menghasilkan pertanyaan yang diberikan gambar dan bagian teks. Manfaat dari pendekatan ini adalah bahwa kami dapat dengan cepat beradaptasi dengan tugas-tugas baru menggunakan pembelajaran dalam konteks.
OpenFlamingo menggabungkan encoder visi pretrained dan model bahasa menggunakan lapisan perhatian silang. Arsitektur model ditunjukkan di bawah ini.
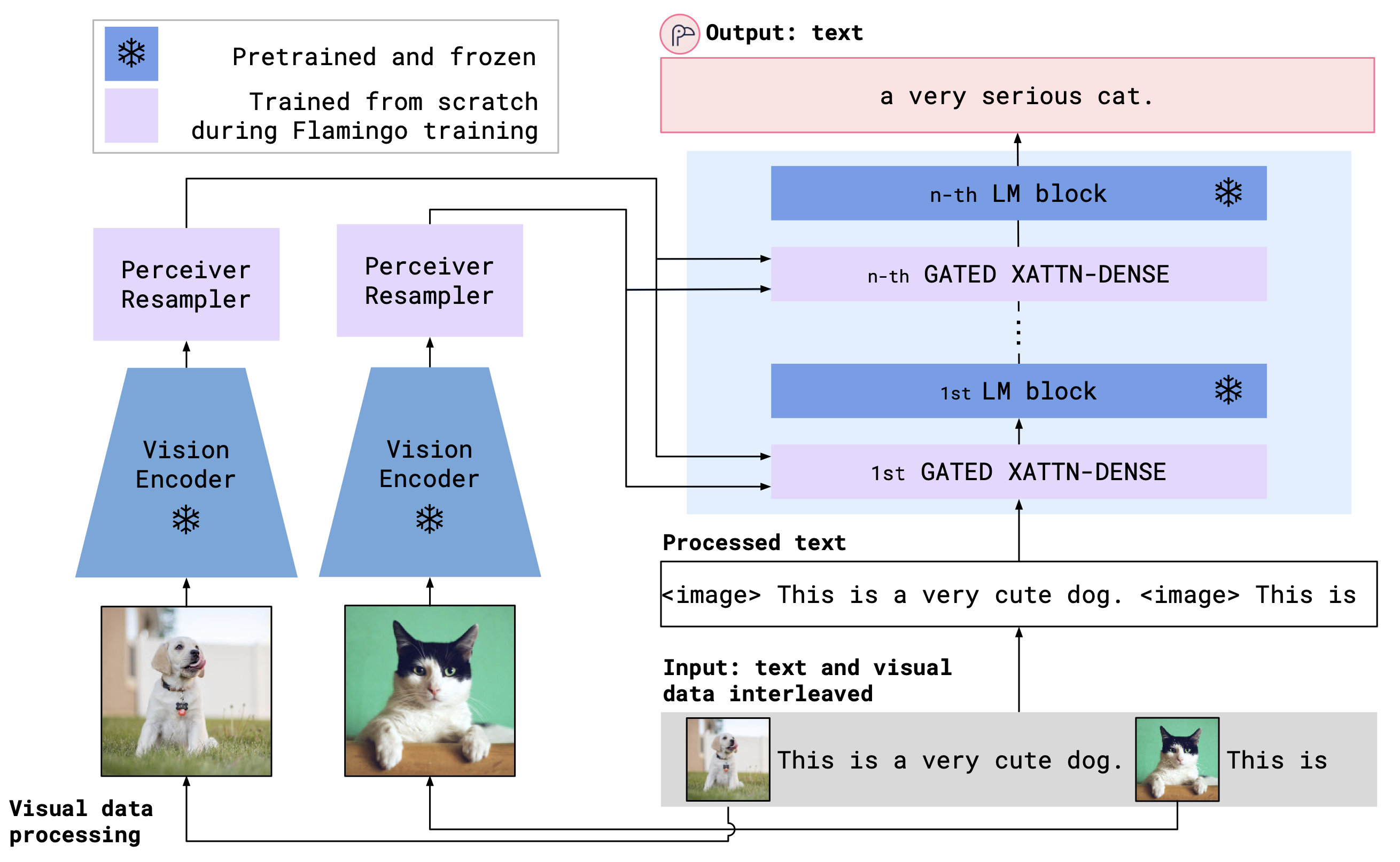 Kredit: Flamingo
Kredit: Flamingo
Kami mendukung encoder penglihatan pretrained dari paket Openclip, yang mencakup model pretrained Openai. Kami juga mendukung model bahasa pretrained dari paket transformers , seperti MPT, Redpajama, Llama, Opt, GPT-NEO, GPT-J, dan model Pythia.
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)Kami telah melatih model OpenFlamingo berikut sejauh ini.
| # params | Model Bahasa | Encoder Visi | Interval xattn* | COCO 4-shot sari | VQAV2 4-shot Accuracy | Bobot |
|---|---|---|---|---|---|---|
| 3b | ANAS-AWADALLA/MPT-1B-REDPAJAMA-200B | Klip OpenAI VIT-L/14 | 1 | 77.3 | 45.8 | Link |
| 3b | ANAS-AWADALLA/MPT-1B-REDPAJAMA-200B-DOLLY | Klip OpenAI VIT-L/14 | 1 | 82.7 | 45.7 | Link |
| 4b | Bersama Computer/Redpajama-Incite-Base-3B-V1 | Klip OpenAI VIT-L/14 | 2 | 81.8 | 49.0 | Link |
| 4b | Bersama Computer/Redpajama-Insite-Instruct-3B-V1 | Klip OpenAI VIT-L/14 | 2 | 85.8 | 49.0 | Link |
| 9b | Anas-Awadalla/MPT-7B | Klip OpenAI VIT-L/14 | 4 | 89.0 | 54.8 | Link |
* Interval xattn mengacu pada argumen --cross_attn_every_n_layers .
Catatan: Sebagai bagian dari rilis V2 kami, kami telah mencela pos pemeriksaan berbasis Llama sebelumnya. Namun, Anda dapat terus menggunakan pos pemeriksaan lama kami menggunakan basis kode baru.
Untuk instantiate model OpenFlamingo dengan salah satu bobot kami yang dirilis, inisialisasi model seperti di atas dan gunakan kode berikut.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )Di bawah ini adalah contoh menghasilkan teks yang dikondisikan pada gambar/teks yang diselingi. Secara khusus, mari kita coba captioning gambar beberapa shot.
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) Kami menyediakan skrip pelatihan di open_flamingo/train . Kami memberikan contoh skrip slurm di open_flamingo/scripts/run_train.py , serta perintah contoh berikut:
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
Catatan: Basis MPT-1B dan kode pemodelan instruksi tidak menerima labels kwarg atau menghitung kehilangan entropi silang langsung di forward() , seperti yang diharapkan oleh basis kode kami. Kami menyarankan menggunakan versi modifikasi dari model MPT-1B yang ditemukan di sini dan di sini.
Untuk detail lebih lanjut, lihat readme pelatihan kami.
Contoh skrip evaluasi ada di open_flamingo/scripts/run_eval.sh . Silakan lihat readme evaluasi kami untuk detail lebih lanjut.
Untuk menjalankan evaluasi di OKVQA, Anda harus menjalankan perintah berikut:
import nltk
nltk.download('wordnet')
OpenFlamingo dikembangkan oleh:
Anas Awadalla*, Irena Gao*, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabri Libel Om
Tim ini terutama dari University of Washington, Stanford, AI2, UCSB, dan Google.
Kode ini didasarkan pada implementasi Flamingo Lucidrains dan repo Flamingo-Mini David Hansmair. Terima kasih telah membuat kode Anda publik! Kami juga berterima kasih kepada tim OpenClip karena kami menggunakan kode pemuatan data mereka dan mengambil inspirasi dari desain perpustakaan mereka.
Kami juga ingin mengucapkan terima kasih kepada Jean-Baptiste Alayrac dan Antoine Miech atas nasihat mereka, Rohan Taori, Nicholas Schiefer, Deep Ganguli, Thomas Liao, Tatsunori Hashimoto, dan Nicholas Carlini atas bantuan mereka dengan menilai risiko keselamatan ini, dan untuk stabilitas AI untuk kami untuk menilai risiko pengaman ini, dan untuk stabilitas AI untuk kami untuk menilai risiko ini.
Jika Anda menemukan repositori ini bermanfaat, harap pertimbangkan mengutip:
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


