open_flamingo
2.0.1
종이 | 블로그 게시물 : 1, 2 | 데모
DeepMind 's Flamingo의 오픈 소스 구현에 오신 것을 환영합니다!
이 저장소에서는 OpenFlamingo 모델 교육 및 평가를위한 Pytorch 구현을 제공합니다. 궁금한 점이 있으시면 언제든지 문제를 열어주십시오. 우리는 또한 기여를 환영합니다!
기존 환경에 패키지를 설치하려면 실행하십시오
pip install open-flamingo
또는 OpenFlamingo를 실행하기위한 콘다 환경을 만들려면
conda env create -f environment.yml
교육 또는 평가 종속성을 설치하려면 처음 두 명령 중 하나를 실행하십시오. 모든 것을 설치하려면 세 번째 명령을 실행하십시오.
pip install open-flamingo[training]
pip install open-flamingo[eval]
pip install open-flamingo[all]
세 가지 requirements.txt 있습니다 .txt 파일 :
requirements.txtrequirements-training.txtrequirements-eval.txt 유스 케이스에 따라 pip install -r <requirements-file.txt> 사용하여 해당 중 하나를 설치할 수 있습니다. 기본 파일에는 모델 실행에 필요한 종속성 만 포함되어 있습니다.
우리는 사전 커밋 후크를 사용하여 저장소의 확인과 서식을 정렬합니다.
pip install pre-commit
brew install pre-commit
pre-commit --version
pre-commit install
그런 다음 GIT 커밋을 실행할 때마다 수표가 실행됩니다. 후크에 의해 파일이 재구성되면 변경된 파일과 git commit 에 대해 git add 실행하십시오.
OpenFlamingo는 다양한 작업에 사용할 수있는 멀티 모달 언어 모델입니다. 대형 멀티 모달 데이터 세트 (예 : 멀티 모달 C4)에 대해 교육을 받고 인터리브 이미지/텍스트에 조절 된 텍스트를 생성하는 데 사용할 수 있습니다. 예를 들어, OpenFlamingo는 이미지에 대한 캡션을 생성하거나 이미지와 텍스트 구절이 주어진 질문을 생성하는 데 사용될 수 있습니다. 이 접근법의 이점은 텍스트 내 학습을 사용하여 새로운 작업에 빠르게 적응할 수 있다는 것입니다.
OpenFlamingo는 교차주의 레이어를 사용하여 사전 예정된 비전 인코더와 언어 모델을 결합합니다. 모델 아키텍처는 다음과 같습니다.
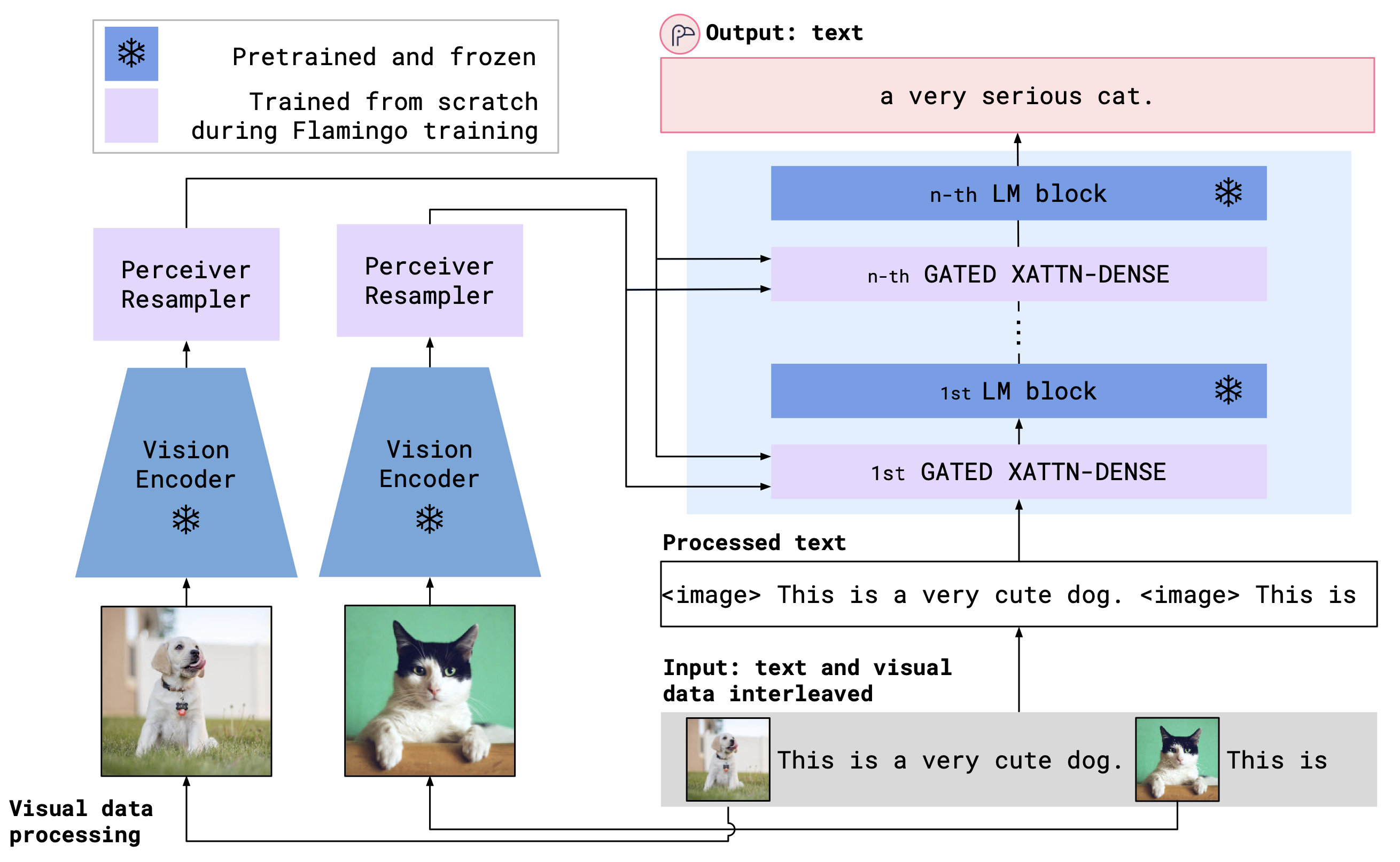 신용 : Flamingo
신용 : Flamingo
OpenAi의 사전 상영 된 모델을 포함하는 OpenClip 패키지의 사전 처리 된 비전 인코더를 지원합니다. 우리는 또한 MPT, Redpajama, Llama, Opt, GPT-Neo, GPT-J 및 Pythia 모델과 같은 transformers 패키지의 사전 위험 모델을 지원합니다.
from open_flamingo import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
tokenizer_path = "anas-awadalla/mpt-1b-redpajama-200b" ,
cross_attn_every_n_layers = 1 ,
cache_dir = "PATH/TO/CACHE/DIR" # Defaults to ~/.cache
)우리는 지금까지 다음과 같은 OpenFlamingo 모델을 교육했습니다.
| # 매개 변수 | 언어 모델 | 비전 인코더 | xattn 간격* | 코코 4 샷 사이다 | VQAV2 4 샷 정확도 | 무게 |
|---|---|---|---|---|---|---|
| 3B | Anas-awadalla/MPT-1B-Redpajama-200b | Openai Clip vit-l/14 | 1 | 77.3 | 45.8 | 링크 |
| 3B | Anas-awadalla/MPT-1B-Redpajama-200b-dolly | Openai Clip vit-l/14 | 1 | 82.7 | 45.7 | 링크 |
| 4B | Computer/Redpajama-incite-base-3b-v1 | Openai Clip vit-l/14 | 2 | 81.8 | 49.0 | 링크 |
| 4B | Computer/Redpajama-Incite-Instruct-3B-V1 | Openai Clip vit-l/14 | 2 | 85.8 | 49.0 | 링크 |
| 9b | Anas-awadalla/mpt-7b | Openai Clip vit-l/14 | 4 | 89.0 | 54.8 | 링크 |
* xattn 간격은 --cross_attn_every_n_layers 인수를 나타냅니다.
참고 : V2 릴리스의 일부로 이전 LLAMA 기반 체크 포인트를 사용하지 않았습니다. 그러나 새 코드베이스를 사용하여 오래된 체크 포인트를 계속 사용할 수 있습니다.
출시 된 가중치 중 하나로 OpenFlamingo 모델을 인스턴스화하려면 위와 같이 모델을 초기화하고 다음 코드를 사용하십시오.
# grab model checkpoint from huggingface hub
from huggingface_hub import hf_hub_download
import torch
checkpoint_path = hf_hub_download ( "openflamingo/OpenFlamingo-3B-vitl-mpt1b" , "checkpoint.pt" )
model . load_state_dict ( torch . load ( checkpoint_path ), strict = False )아래는 인터리브 이미지/텍스트에 조절 된 텍스트를 생성하는 예입니다. 특히, 몇 가지 샷 이미지 캡션을 시도해 봅시다.
from PIL import Image
import requests
import torch
"""
Step 1: Load images
"""
demo_image_one = Image . open (
requests . get (
"http://images.cocodataset.org/val2017/000000039769.jpg" , stream = True
). raw
)
demo_image_two = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028137.jpg" ,
stream = True
). raw
)
query_image = Image . open (
requests . get (
"http://images.cocodataset.org/test-stuff2017/000000028352.jpg" ,
stream = True
). raw
)
"""
Step 2: Preprocessing images
Details: For OpenFlamingo, we expect the image to be a torch tensor of shape
batch_size x num_media x num_frames x channels x height x width.
In this case batch_size = 1, num_media = 3, num_frames = 1,
channels = 3, height = 224, width = 224.
"""
vision_x = [ image_processor ( demo_image_one ). unsqueeze ( 0 ), image_processor ( demo_image_two ). unsqueeze ( 0 ), image_processor ( query_image ). unsqueeze ( 0 )]
vision_x = torch . cat ( vision_x , dim = 0 )
vision_x = vision_x . unsqueeze ( 1 ). unsqueeze ( 0 )
"""
Step 3: Preprocessing text
Details: In the text we expect an <image> special token to indicate where an image is.
We also expect an <|endofchunk|> special token to indicate the end of the text
portion associated with an image.
"""
tokenizer . padding_side = "left" # For generation padding tokens should be on the left
lang_x = tokenizer (
[ "<image>An image of two cats.<|endofchunk|><image>An image of a bathroom sink.<|endofchunk|><image>An image of" ],
return_tensors = "pt" ,
)
"""
Step 4: Generate text
"""
generated_text = model . generate (
vision_x = vision_x ,
lang_x = lang_x [ "input_ids" ],
attention_mask = lang_x [ "attention_mask" ],
max_new_tokens = 20 ,
num_beams = 3 ,
)
print ( "Generated text: " , tokenizer . decode ( generated_text [ 0 ])) open_flamingo/train 에서 교육 스크립트를 제공합니다. open_flamingo/scripts/run_train.py 의 Slurm 스크립트 예제와 다음 예제 명령을 제공합니다.
torchrun --nnodes=1 --nproc_per_node=4 open_flamingo/train/train.py
--lm_path anas-awadalla/mpt-1b-redpajama-200b
--tokenizer_path anas-awadalla/mpt-1b-redpajama-200b
--cross_attn_every_n_layers 1
--dataset_resampled
--batch_size_mmc4 32
--batch_size_laion 64
--train_num_samples_mmc4 125000
--train_num_samples_laion 250000
--loss_multiplier_laion 0.2
--workers=4
--run_name OpenFlamingo-3B-vitl-mpt1b
--num_epochs 480
--warmup_steps 1875
--mmc4_textsim_threshold 0.24
--laion_shards "/path/to/shards/shard-{0000..0999}.tar"
--mmc4_shards "/path/to/shards/shard-{0000..0999}.tar"
--report_to_wandb
참고 : MPT-1B 기반 및 지시 모델링 코드는 코드베이스에서 예상 한대로 forward() 내에서 직접 크로스 엔트로피 손실 labels 허용하지 않습니다. 여기에서 발견 된 MPT-1B 모델의 수정 된 버전을 사용하는 것이 좋습니다.
자세한 내용은 교육 readme를 참조하십시오.
예제 평가 스크립트는 open_flamingo/scripts/run_eval.sh 에 있습니다. 자세한 내용은 Evaluation ReadMe를 참조하십시오.
OKVQA에 대한 평가를 실행하려면 다음 명령을 실행해야합니다.
import nltk
nltk.download('wordnet')
OpenFlamingo는 다음과 같이 개발했습니다.
Anas Awadalla*, Irena Gao*, Joshua Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco 슈미트.
이 팀은 주로 워싱턴 대학교, 스탠포드, AI2, UCSB 및 Google 출신입니다.
이 코드는 Lucidrains의 Flamingo 구현과 David Hansmair의 Flamingo-Mini Repo를 기반으로합니다. 코드를 공개 해 주셔서 감사합니다! 또한 데이터로드 코드를 사용하고 라이브러리 디자인에서 영감을 얻으려면 OpenClip 팀에 감사드립니다.
우리는 또한 Jean-Baptiste Alayrac과 Antoine Miech에게 그들의 조언에 대해 감사하고, Rohan Taori, Nicholas Schiefer, Deep Ganguli, Thomas Liao, Tatsunori Hashimoto 및 Nicholas Carlini가 우리의 석방의 안전 위험을 평가하는 데 도움을 주었고, 이러한 모델을 구성 할 수있는 AI를위한 안정성 AI를 제공하고 싶습니다.
이 저장소가 유용하다고 생각되면 다음을 고려하십시오.
@article{awadalla2023openflamingo,
title={OpenFlamingo: An Open-Source Framework for Training Large Autoregressive Vision-Language Models},
author={Anas Awadalla and Irena Gao and Josh Gardner and Jack Hessel and Yusuf Hanafy and Wanrong Zhu and Kalyani Marathe and Yonatan Bitton and Samir Gadre and Shiori Sagawa and Jenia Jitsev and Simon Kornblith and Pang Wei Koh and Gabriel Ilharco and Mitchell Wortsman and Ludwig Schmidt},
journal={arXiv preprint arXiv:2308.01390},
year={2023}
}
@software{anas_awadalla_2023_7733589,
author = {Awadalla, Anas and Gao, Irena and Gardner, Joshua and Hessel, Jack and Hanafy, Yusuf and Zhu, Wanrong and Marathe, Kalyani and Bitton, Yonatan and Gadre, Samir and Jitsev, Jenia and Kornblith, Simon and Koh, Pang Wei and Ilharco, Gabriel and Wortsman, Mitchell and Schmidt, Ludwig},
title = {OpenFlamingo},
month = mar,
year = 2023,
publisher = {Zenodo},
version = {v0.1.1},
doi = {10.5281/zenodo.7733589},
url = {https://doi.org/10.5281/zenodo.7733589}
}
@article{Alayrac2022FlamingoAV,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author={Jean-Baptiste Alayrac and Jeff Donahue and Pauline Luc and Antoine Miech and Iain Barr and Yana Hasson and Karel Lenc and Arthur Mensch and Katie Millican and Malcolm Reynolds and Roman Ring and Eliza Rutherford and Serkan Cabi and Tengda Han and Zhitao Gong and Sina Samangooei and Marianne Monteiro and Jacob Menick and Sebastian Borgeaud and Andy Brock and Aida Nematzadeh and Sahand Sharifzadeh and Mikolaj Binkowski and Ricardo Barreira and Oriol Vinyals and Andrew Zisserman and Karen Simonyan},
journal={ArXiv},
year={2022},
volume={abs/2204.14198}
}


