LLM finetune vuln detection
1.0.0
作者: Yong-Hwan Lee,James Flora,Shijie Zhao和Yunhan Qiao
該項目複製並基於Shestov等人的研究。 (2024) ,旨在驗證和擴展其發現。最初的研究集中於微調大語言模型(LLMS)進行代碼脆弱性檢測。該方法利用LoRA (低級適應),該技術涉及在層中添加適配器進行微調。在此過程中,原始模型參數被冷凍,並且只有適配器經過訓練,從而使培訓過程更具成本效益。
我們作品的關鍵創新是我們對QLoRA的自定義改編的結合,該Qlora首先將LLM量化為4位浮子,從而大大降低了其尺寸。例如,量化後,最初約為26 GB且通常需要30 GB的VRAM ,通常需要30 GB的VRAM,在量化後約7 GB 。量化後,將LoRA技術應用於微調。
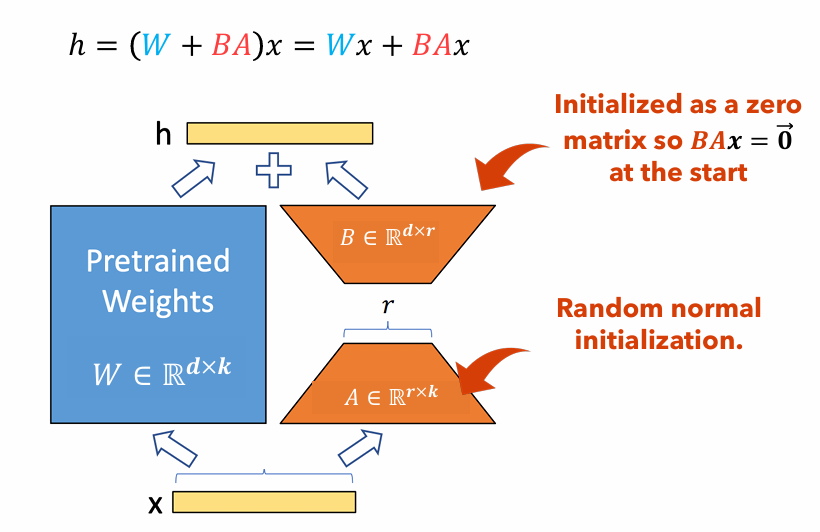
圖1 :洛拉適配器插圖
圖1說明了Lora適配器如何顯著小於原始參數尺寸。參數數量的數量
例如,考慮具有重量矩陣的LLM中的一層
$ w in mathbb {r}^{1000 times 100} $ 。參數數量的數量$ W $ 是$ 1000 times 100 = 100,000 $ 。如果我們將洛拉等級設置為$ r = 5 $ ,洛拉適配器的大小只是$ 1000 times 5 + 100 times 5 = 5,500 $ 。這意味著適配器的大小約為原始重量矩陣的5%$ W $ ,作為原始重量矩陣,這對於培訓非常易於管理$ W $ 在訓練階段保持冷凍。
在這個項目中,我們改變了dataset , sequence length和the use of focal loss ;與單獨的洛拉相比,測量了所得的性能變化。該項目的報告:PDF
該文檔提供了複製我們的研究項目的詳細說明。它包括用於設置必要環境,進行必要的代碼更改,在高性能計算(HPC)群集上運行模型的步驟,並顯示結果。
pip install -r requirements.txtGPTBigCodeConfig your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py中添加以下函數。 class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )SRUN -P DGXH-時間= 2-00:00:00 -c 2 -ggres = gpu:2 -mem = 20G -pty bash
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| 數據集 | 序列長度 | 大功能 | roc auc | F1得分 | GPU | 訓練時間(HR) | |
|---|---|---|---|---|---|---|---|
| Qlora | x₁沒有p₃ | 512 | 忽略 | 0.53 | 0.65 | 特斯拉T4 | 8.2 |
| x₁沒有p₃ | 512 | 包括 | 0.56 | 0.66 | NVIDIA A100 X2 | 3.4 | |
| x₁沒有p₃ | 256 | 忽略 | 0.51 | 0.63 | 特斯拉T4 | 2.9 | |
| x₁與p₃ | 512 | 忽略 | 0.68 | 0.14 | RTX 4080 | 22.1 | |
| x₁與p₃ | 512 | 包括 | 0.72 | 0.17 | NVIDIA A100 X2 | 20.4 | |
| x₁與p₃ | 256 | 忽略 | 0.70 | 0.14 | NVIDIA A100 X2 | 18.3 | |
| 洛拉 | x₁沒有p₃ | 2048 | 包括 | 0.69 | 0.71 | NVIDIA V100 X8 | |
| x₁與p₃ | 2048 | 包括 | 0.86 | 0.27 | NVIDIA V100 X8 |
在本文中,我們重新創建了Shestov等人的發現。在其中,我們對LLM(WizardCoder)進行了代碼漏洞檢測。儘管原始作者使用洛拉(Lora)來做到這一點,但我們採用Qlora來減少整體型號的大小,並能夠在消費級GPU上訓練這種型號。儘管如此,我們看到性能指標的大幅下降,儘管顯然該模型仍在進行某種學習。此外,我們對超參數序列長度進行實驗,並包括較大的功能。我們能夠得出結論,包括大型功能對模型的學習能力是一個嚴格的陽性,但是由於令人困惑的實驗,序列長度的證據尚無定論,其結果比其餘的要高得多。
[1] Shestov,A.,Levichev,R.,Mussabayev,R.,Maslov,E.,Cheshkov,A。 ,&Zadorozhny,P。 (2024)。為脆弱性檢測提供大型語言模型。 ARXIV預印型ARXIV:2401.17010。取自https://arxiv.org/abs/2401.17010。
[2] Hu,EJ,Shen,Y.,Wallis,P.,Allen-Zhu,Z.,Li,Y.,Wang,S。 ,&Chen,W。 (2021)。 LORA:大型語言模型的低級改編。 ARXIV預印ARXIV:2106.09685。取自https://arxiv.org/abs/2106.09685。
[3] Dettmers,T.,Pagnoni,A.,Holtzman,A。 ,&Zettlemoyer,L。 (2023)。 QLORA:量化LLM的有效固定。 ARXIV預印型ARXIV:2305.14314。取自https://arxiv.org/abs/2305.14314。


