LLM finetune vuln detection
1.0.0
著者: Yong-Hwan Lee、James Flora、Shijie Zhao、Yunhan Qiao
このプロジェクトは、Shestovらによる研究を再現し、構築します。 (2024) 、調査結果を検証し、拡張することを目指しています。元の研究は、コードの脆弱性検出のための大規模な言語モデル(LLMS)の微調整に焦点を当てていました。このアプローチは、 LoRA (低ランク適応)を利用しました。これは、微調整のためにレイヤー内にアダプターを追加することを含む手法です。このプロセス中、元のモデルパラメーターは凍結され、アダプターのみがトレーニングされ、トレーニングプロセスがより費用対効果が高くなります。
私たちの仕事の重要な革新は、 QLoRAのカスタム適応を組み込むことです。これは、最初にLLMを4ビットフロートに量子化し、そのサイズを大幅に削減します。たとえば、元々は26 GBで、通常は30 GBを超えるVRAMを必要とする13B-WizardCoderモデルは、量子化後約7 GBに減少します。量子化に続いて、 LoRA技術は微調整に適用されます。
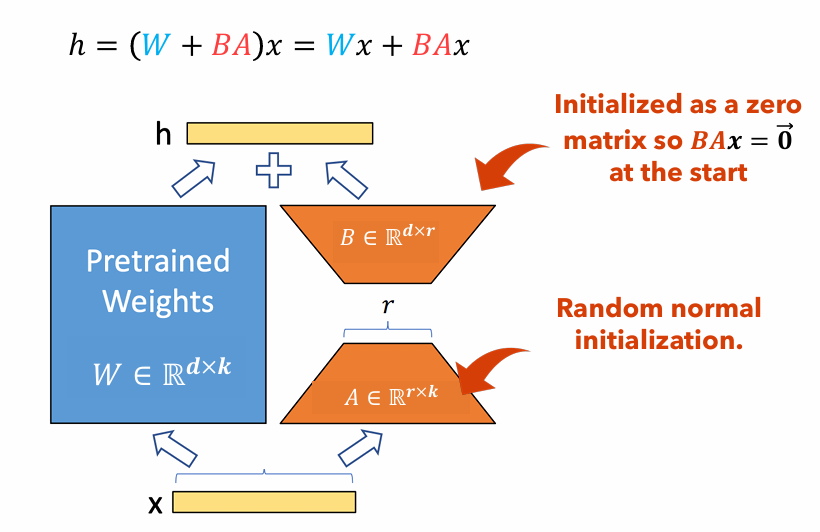
図1 :LORAアダプターイラスト
図1は、ロラアダプターが元のパラメーターサイズよりも大幅に小さくなる方法を示しています。のパラメーターの数
たとえば、重量マトリックスを備えたLLMのレイヤーを検討してください
$ w in mathbb {r}^{1000 times 100} $ 。のパラメーターの数$ w $ は$ 1000 Times 100 = 100,000 $ 。ロラのランクを設定した場合$ r = 5 $ 、Loraアダプターのサイズのみです$ 1000 times 5 + 100 times 5 = 5,500 $ 。これは、アダプターサイズが元の重量マトリックスの約5%であることを意味します$ w $ 、元の重量マトリックスとしてトレーニングには大幅に管理しやすい$ w $ トレーニングフェーズ中は凍結されたままです。
このプロジェクトでは、 dataset 、 sequence length 、およびthe use of focal lossを変化させました。 LORAのみと比較して、結果のパフォーマンスの変化を測定しました。このプロジェクトのレポート:PDF
このドキュメントは、研究プロジェクトを複製するための詳細な指示を提供します。これには、必要な環境を設定し、必要なコードの変更を加え、高性能コンピューティング(HPC)クラスターでモデルを実行し、結果を提示するための手順が含まれています。
pip install -r requirements.txtyour_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.pyにあるトランスパッケージのGPTBigCodeConfigクラスに追加します: class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.pyのディレクトリパスを変更します sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )srun -p dgxh -time = 2-00:00:00:00 -c 2 -gres = gpu:2 - mem = 20g -pty bash
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| データセット | シーケンス長 | 大きな関数 | ROC AUC | F1スコア | GPU | トレーニング時間(HR) | |
|---|---|---|---|---|---|---|---|
| qlora | x₁p₃なし | 512 | 無視する | 0.53 | 0.65 | テスラT4 | 8.2 |
| x₁p₃なし | 512 | 含む | 0.56 | 0.66 | nvidia a100 x2 | 3.4 | |
| x₁p₃なし | 256 | 無視する | 0.51 | 0.63 | テスラT4 | 2.9 | |
| x₁とp₃ | 512 | 無視する | 0.68 | 0.14 | RTX 4080 | 22.1 | |
| x₁とp₃ | 512 | 含む | 0.72 | 0.17 | nvidia a100 x2 | 20.4 | |
| x₁とp₃ | 256 | 無視する | 0.70 | 0.14 | nvidia a100 x2 | 18.3 | |
| ロラ | x₁p₃なし | 2048 | 含む | 0.69 | 0.71 | Nvidia V100 X8 | |
| x₁とp₃ | 2048 | 含む | 0.86 | 0.27 | Nvidia V100 X8 |
この論文では、 Shestovらの調査結果を再作成します。コードの脆弱性検出のために、LLMであるWizardCoderをFINTUNEで獲得します。元の著者はLORAを使用してそうしますが、Qloraを使用して全体的なモデルサイズを削減し、消費者グレードGPUでそのようなモデルをトレーニングできます。それにもかかわらず、モデルがまだ何らかの学習を行っていることは明らかですが、パフォーマンスメトリックに大きな劣化が見られます。さらに、ハイパーパラメータシーケンス長で実験を実行し、大きな機能を含みます。大規模な機能を含めることはモデルの学習能力にとって厳格なプラスであると結論付けることができますが、シーケンスの長さに関する証拠は、他の結果よりもはるかに高い結果をもたらす不可解な実験のために決定的ではありません。
[1] Shestov、A.、Levichev、R.、Mussabayev、R.、Maslov、E.、Cheshkov、A。、&Zadorozhny、P。(2024)。脆弱性検出のための大規模な言語モデルの微調整。 arxiv preprint arxiv:2401.17010。 https://arxiv.org/abs/2401.17010から取得。
[2] Hu、EJ、Shen、Y.、Wallis、P.、Allen-Zhu、Z.、Li、Y.、Wang、S。、&Chen、W。(2021)。 LORA:大規模な言語モデルの低ランク適応。 Arxiv Preprint arxiv:2106.09685。 https://arxiv.org/abs/2106.09685から取得。
[3] Dettmers、T.、Pagnoni、A.、Holtzman、A。、&Zettlemoyer、L。(2023)。 Qlora:量子化されたLLMの効率的な微調整。 arxiv preprint arxiv:2305.14314。 https://arxiv.org/abs/2305.14314から取得。


