LLM finetune vuln detection
1.0.0
ผู้แต่ง: Yong-Hwan Lee, James Flora, Shijie Zhao และ Yunhan Qiao
โครงการนี้จำลองและสร้างจากการศึกษาโดย Shestov และคณะ (2024) โดยมีจุดประสงค์เพื่อตรวจสอบและขยายการค้นพบของพวกเขา การวิจัยดั้งเดิมมุ่งเน้นไปที่การปรับแต่งแบบจำลองภาษาขนาดใหญ่ (LLMs) สำหรับการตรวจจับความเสี่ยงรหัส วิธีการที่ใช้ LoRA (การปรับระดับต่ำ) ซึ่งเป็นเทคนิคที่เกี่ยวข้องกับการเพิ่มอะแดปเตอร์ภายในเลเยอร์สำหรับการปรับแต่ง ในระหว่างกระบวนการนี้พารามิเตอร์โมเดลดั้งเดิมจะถูก แช่แข็ง และมีเพียงอะแดปเตอร์เท่านั้นที่ได้รับการฝึกอบรมทำให้กระบวนการฝึกอบรมคุ้มค่ามากขึ้น
นวัตกรรมที่สำคัญของงานของเราคือการรวมตัวกันของการปรับตัวที่กำหนดเองของ QLoRA ซึ่งเป็นครั้งแรกที่ปริมาณ LLM เป็น ลอย 4 บิต ลดขนาดลงอย่างมาก ตัวอย่างเช่น โมเดล 13B-Wizardcoder ซึ่งเดิมมีประมาณ 26 GB และโดยทั่วไปจะต้องใช้ VRAM มากกว่า 30 GB จะลดลงเหลือประมาณ 7 GB หลังจากการวัดปริมาณ หลังจากการหาปริมาณเทคนิค LoRA ถูกนำไปใช้สำหรับการปรับแต่ง
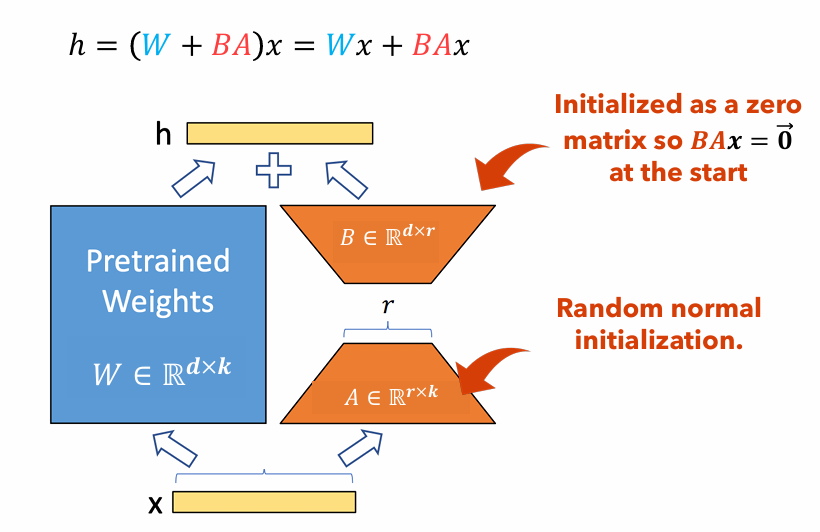
รูปที่ 1 : ภาพประกอบอะแดปเตอร์ Lora
รูปที่ 1 แสดงให้เห็นว่าอะแดปเตอร์ LORA สามารถเล็กกว่าขนาดพารามิเตอร์ดั้งเดิมได้อย่างไร จำนวนพารามิเตอร์สำหรับ
ตัวอย่างเช่นพิจารณาเลเยอร์ใน LLM ที่มีเมทริกซ์น้ำหนัก
$ w in mathbb {r}^{1,000 times 100} $ - จำนวนพารามิเตอร์สำหรับ$ w $ เป็น$ 1,000 times 100 = 100,000 $ - ถ้าเราตั้งค่า Lora ให้เป็น$ r = 5 $ ขนาดของอะแดปเตอร์ LORA เท่านั้น$ 1,000 Times 5 + 100 Times 5 = 5,500 $ - ซึ่งหมายความว่าขนาดอะแดปเตอร์อยู่ที่ประมาณ 5% ของเมทริกซ์น้ำหนักดั้งเดิม$ w $ ซึ่งสามารถจัดการได้อย่างมีนัยสำคัญสำหรับการฝึกอบรมเป็นเมทริกซ์น้ำหนักดั้งเดิม$ w $ ยังคงแช่แข็งในระหว่างขั้นตอนการฝึกอบรม
ในโครงการนี้เราเปลี่ยนแปลง dataset sequence length และ the use of focal loss วัดการเปลี่ยนแปลงประสิทธิภาพที่เกิดขึ้นเมื่อเทียบกับ LORA เพียงอย่างเดียว รายงานสำหรับโครงการนี้: PDF
เอกสารนี้ให้คำแนะนำโดยละเอียดสำหรับการทำซ้ำโครงการวิจัยของเรา มันมีขั้นตอนสำหรับการตั้งค่าสภาพแวดล้อมที่จำเป็นการเปลี่ยนแปลงรหัสที่จำเป็นการเรียกใช้โมเดลบนคลัสเตอร์การคำนวณประสิทธิภาพสูง (HPC) และนำเสนอผลลัพธ์
pip install -r requirements.txtGPTBigCodeConfig ในแพ็คเกจ Transformers ที่อยู่ที่ your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py : class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )SRUN -P DGXH -เวลา = 2-00: 00: 00 -C 2 -GRES = GPU: 2 -MEM = 20G -BASH
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| ชุดข้อมูล | ความยาวลำดับ | ฟังก์ชั่นขนาดใหญ่ | ROC AUC | คะแนน F1 | GPU | เวลาฝึกอบรม (HR) | |
|---|---|---|---|---|---|---|---|
| Qlora | x₁ไม่มีp₃ | 512 | ไม่สนใจ | 0.53 | 0.65 | Tesla T4 | 8.2 |
| x₁ไม่มีp₃ | 512 | รวม | 0.56 | 0.66 | Nvidia A100 x2 | 3.4 | |
| x₁ไม่มีp₃ | 256 | ไม่สนใจ | 0.51 | 0.63 | Tesla T4 | 2.9 | |
| x₁กับp₃ | 512 | ไม่สนใจ | 0.68 | 0.14 | RTX 4080 | 22.1 | |
| x₁กับp₃ | 512 | รวม | 0.72 | 0.17 | Nvidia A100 x2 | 20.4 | |
| x₁กับp₃ | 256 | ไม่สนใจ | 0.70 | 0.14 | Nvidia A100 x2 | 18.3 | |
| Lora | x₁ไม่มีp₃ | 2048 | รวม | 0.69 | 0.71 | NVIDIA V100 X8 | |
| x₁กับp₃ | 2048 | รวม | 0.86 | 0.27 | NVIDIA V100 X8 |
ในบทความนี้เราสร้างผลการวิจัยของ Shestov และคณะ ซึ่งเราได้รับการแก้ไข LLM, WizardCoder, สำหรับการตรวจจับความเสี่ยงรหัส ในขณะที่ผู้เขียนดั้งเดิมใช้ LORA เพื่อทำเช่นนั้นเราใช้ Qlora เพื่อลดขนาดโมเดลโดยรวมและสามารถฝึกอบรมแบบจำลองดังกล่าวบน GPU เกรดผู้บริโภค อย่างไรก็ตามเรื่องนี้เราเห็นความเสื่อมโทรมอย่างมีนัยสำคัญในการวัดประสิทธิภาพแม้ว่าจะเป็นที่ชัดเจนว่าโมเดลยังคงทำการ เรียนรู้ บางอย่าง นอกจากนี้เราทำการทดลองเกี่ยวกับ ความยาวลำดับของ พารามิเตอร์ hyperparameters และ รวมถึงฟังก์ชั่นขนาดใหญ่ เราสามารถสรุปได้ว่าการรวมฟังก์ชั่นขนาดใหญ่เป็นบวกที่เข้มงวดสำหรับความสามารถในการเรียนรู้ของโมเดล แต่หลักฐานเกี่ยวกับความยาวลำดับนั้นไม่สามารถสรุปได้เนื่องจากการทดลองที่ทำให้งงงันที่มีผลลัพธ์ที่สูงกว่าส่วนที่เหลือ
[1] Shestov, A. , Levichev, R. , Mussabayev, R. , Maslov, E. , Cheshkov, A. , & Zadorozhny, P. (2024) Finetuning แบบจำลองภาษาขนาดใหญ่สำหรับการตรวจจับช่องโหว่ arxiv preprint arxiv: 2401.17010 สืบค้นจาก https://arxiv.org/abs/2401.17010
[2] Hu, Ej, Shen, Y. , Wallis, P. , Allen-Zhu, Z. , Li, Y. , Wang, S. , & Chen, W. (2021) LORA: การปรับระดับต่ำของแบบจำลองภาษาขนาดใหญ่ arxiv preprint arxiv: 2106.09685 สืบค้นจาก https://arxiv.org/abs/2106.09685
[3] Dettmers, T. , Pagnoni, A. , Holtzman, A. , & Zettlemoyer, L. (2023) Qlora: การเพิ่มประสิทธิภาพอย่างมีประสิทธิภาพของ LLMs เชิงปริมาณ arxiv preprint arxiv: 2305.14314 สืบค้นจาก https://arxiv.org/abs/2305.14314


