LLM finetune vuln detection
1.0.0
Autoren: Yong-Hwan Lee, James Flora, Shijie Zhao und Yunhan Qiao
Dieses Projekt repliziert und baut auf der Studie von Shestov et al. (2024) , um ihre Ergebnisse zu validieren und zu erweitern. Die ursprüngliche Forschung konzentrierte sich auf Feinabstimmungsmodelle (LLMs) zur Erkennung von Code-Schwachstellen. Der Ansatz verwendete LoRA (Anpassung mit niedriger Rang), eine Technik, bei der Adapter in Schichten zur Feinabstimmung hinzugefügt werden. Während dieses Prozesses sind die ursprünglichen Modellparameter eingefroren und nur die Adapter werden geschult, wodurch der Trainingsprozess kostengünstiger wird.
Eine wichtige Innovation unserer Arbeit ist die Einbeziehung unserer benutzerdefinierten Anpassung von QLoRA , die das LLM zuerst in einen 4-Bit-Schwimmer quantifiziert und seine Größe erheblich verringert. Zum Beispiel wird das 13B-WizardCoder-Modell , das ursprünglich rund 26 GB und in der Regel mehr als 30 GB VRAM erfordert, nach der Quantisierung auf ungefähr 7 GB reduziert. Nach der Quantisierung wird die LoRA Technik zur Feinabstimmung angewendet.
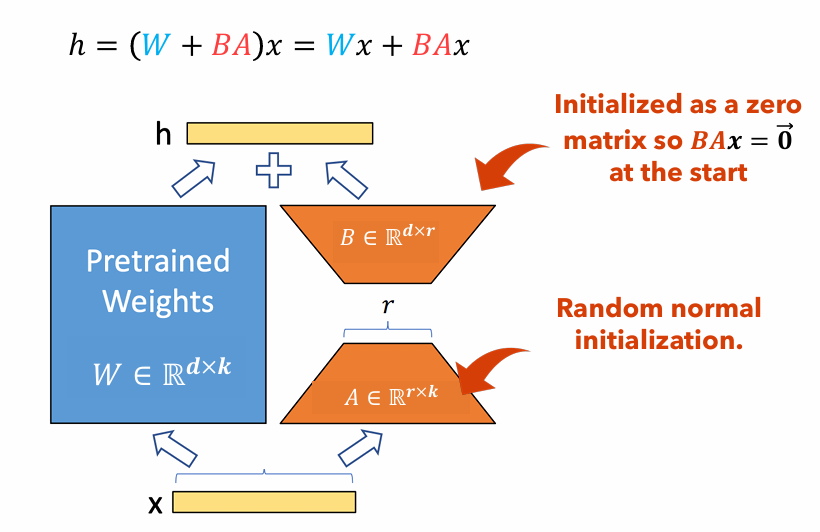
Abbildung 1 : Lora -Adapter -Abbildung
Abbildung 1 zeigt, wie LORA -Adapter erheblich kleiner sein können als die ursprünglichen Parametergrößen. Die Anzahl der Parameter für die
Betrachten Sie beispielsweise eine Schicht in einem LLM mit einer Gewichtsmatrix
$ W in mathbb {r}^{1000 Times 100} $ . Die Anzahl der Parameter für$ W $ Ist$ 1000 mal 100 = 100.000 $ . Wenn wir den Lora -Rang aufstellen$ R = 5 $ Die Größe der Lora -Adapter ist nur$ 1000 Times 5 + 100 Times 5 = 5.500 $ . Dies bedeutet, dass die Adaptergröße etwa 5% der ursprünglichen Gewichtsmatrix beträgt$ W $ , was für das Training als ursprüngliche Gewichtsmatrix erheblich überschaubar ist$ W $ bleibt während der Trainingsphase eingefroren.
In diesem Projekt haben wir den dataset , sequence length und the use of focal loss variiert. gemessen die resultierenden Leistungsänderungen im Vergleich zu Lora allein. Der Bericht für dieses Projekt: PDF
Dieses Dokument enthält detaillierte Anweisungen zur Replikation unseres Forschungsprojekts. Es enthält Schritte zum Einrichten der erforderlichen Umgebung, zum Erfordernis der erforderlichen Codeänderungen, zum Ausführen des Modells in einem HPC-Cluster (High-Performance Computing) und der Präsentation der Ergebnisse.
pip install -r requirements.txtGPTBigCodeConfig Klasse in dem Transformers-Paket unter your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py : class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )srun -p dgxh -Zeit = 2-00: 00: 00 -c 2 -GRES = GPU: 2 -MEM = 20G - -PTY BASH
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| Datensatz | Sequenzlänge | Große Funktion | ROC AUC | F1 -Punktzahl | GPU | Trainingszeit (HR) | |
|---|---|---|---|---|---|---|---|
| Qlora | X₁ ohne p₃ | 512 | ignorieren | 0,53 | 0,65 | Tesla T4 | 8.2 |
| X₁ ohne p₃ | 512 | enthalten | 0,56 | 0,66 | Nvidia A100 x2 | 3.4 | |
| X₁ ohne p₃ | 256 | ignorieren | 0,51 | 0,63 | Tesla T4 | 2.9 | |
| X₁ mit P₃ | 512 | ignorieren | 0,68 | 0,14 | RTX 4080 | 22.1 | |
| X₁ mit P₃ | 512 | enthalten | 0,72 | 0,17 | Nvidia A100 x2 | 20.4 | |
| X₁ mit P₃ | 256 | ignorieren | 0,70 | 0,14 | Nvidia A100 x2 | 18.3 | |
| Lora | X₁ ohne p₃ | 2048 | enthalten | 0,69 | 0,71 | Nvidia v100 x8 | |
| X₁ mit P₃ | 2048 | enthalten | 0,86 | 0,27 | Nvidia v100 x8 |
In diesem Artikel erstellen wir die Ergebnisse von Shestov et al . in dem wir die LLM, Assistentcoder, für die Erkennung von Code -Sicherheitsanfälligkeit finanzieren. Während die ursprünglichen Autoren LORA dazu verwenden, verwenden wir Qlora, um die Gesamtmodellgröße zu senken, und können ein solches Modell für eine GPU der Verbraucherqualität trainieren. Trotzdem sehen wir einen signifikanten Abbau der Leistungsmetriken, obwohl es klar ist, dass das Modell immer noch lernt . Darüber hinaus führen wir Experimente mit der Hyperparameter -Sequenzlänge durch und umfassen große Funktionen . Wir können zu dem Schluss kommen, dass die Einbeziehung großer Funktionen ein streng positiv für die Lernfähigkeiten des Modells ist, aber die Beweise für die Sequenzlänge sind aufgrund eines verblüffenden Experiments mit viel höheren Ergebnissen als die anderen nicht schlüssig.
[1] Shestov, A., Levichev, R., Mussabayev, R., Maslov, E., Cheshkov, A. & Zadorozny, P. (2024). Finetuning Großsprachenmodelle für die Erkennung von Schwachstellen . ARXIV Preprint Arxiv: 2401.17010. Abgerufen von https://arxiv.org/abs/2401.17010.
[2] Hu, EJ, Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S. & Chen, W. (2021). LORA: Low-Rang-Anpassung großer Sprachmodelle. Arxiv Preprint Arxiv: 2106.09685. Abgerufen von https://arxiv.org/abs/2106.09685.
[3] Dettmers, T., Pagnoni, A., Holtzman, A. & Zettlemoyer, L. (2023). Qlora: Effiziente Finetuning von quantisierten LLMs. Arxiv Preprint Arxiv: 2305.14314. Abgerufen von https://arxiv.org/abs/2305.14314.


