LLM finetune vuln detection
1.0.0
Autores: Yong-Hwan Lee, James Flora, Shijie Zhao y Yunhan Qiao
Este proyecto replica y se basa en el estudio de Shestov et al. (2024) , con el objetivo de validar y extender sus hallazgos. La investigación original se centró en ajustar los modelos de idiomas grandes (LLM) para la detección de vulnerabilidades de código. El enfoque utilizó LoRA (adaptación de bajo rango), una técnica que implica agregar adaptadores dentro de las capas para ajustar. Durante este proceso, los parámetros del modelo original están congelados , y solo los adaptadores están capacitados, lo que hace que el proceso de capacitación sea más rentable.
Una innovación clave de nuestro trabajo es la incorporación de nuestra adaptación personalizada de QLoRA , que primero cuantifica el LLM a un flotador de 4 bits , reduciendo significativamente su tamaño. Por ejemplo, el modelo 13B-WizardCoder , originalmente alrededor de 26 GB y generalmente requiere más de 30 GB de VRAM, se reduce a aproximadamente 7 GB después de la cuantización. Después de la cuantización, la técnica LoRA se aplica para el ajuste fino.
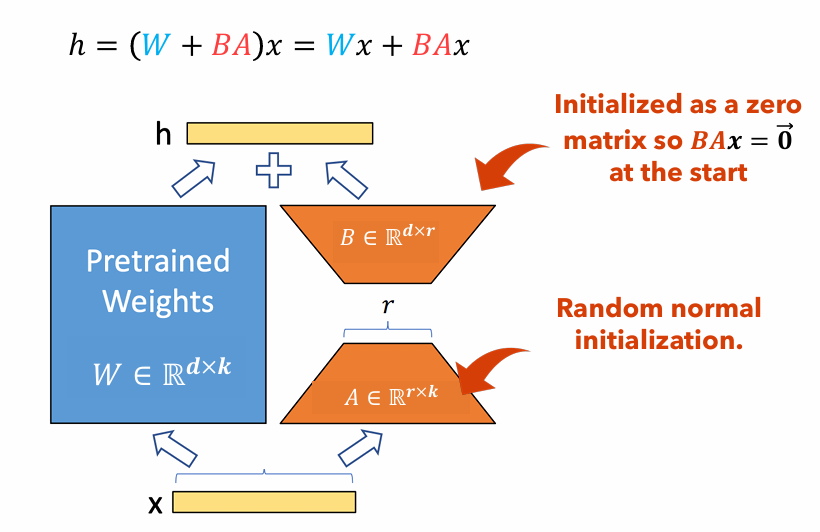
Figura 1 : Ilustración del adaptador de Lora
La Figura 1 ilustra cómo los adaptadores Lora pueden ser significativamente más pequeños que los tamaños de parámetros originales. El número de parámetros para el
Por ejemplo, considere una capa en un LLM con una matriz de peso
$ W in mathbb {r}^{1000 Times 100} $ . El número de parámetros para$ W $ es$ 1000 veces 100 = 100,000 $ . Si establecemos el rango de Lora en$ r = 5 $ , el tamaño de los adaptadores de Lora es solo$ 1000 veces 5 + 100 veces 5 = 5,500 $ . Esto significa que el tamaño del adaptador es alrededor del 5% de la matriz de peso original$ W $ , que es significativamente manejable para la capacitación como la matriz de peso original$ W $ permanece congelado durante la fase de entrenamiento.
En este proyecto, variamos el dataset , sequence length y the use of focal loss ; midió los cambios de rendimiento resultantes en comparación con Lora solo. El informe para este proyecto: PDF
Este documento proporciona instrucciones detalladas para replicar nuestro proyecto de investigación. Incluye pasos para configurar el entorno necesario, hacer cambios de código requeridos, ejecutar el modelo en un clúster informático de alto rendimiento (HPC) y presentar los resultados.
pip install -r requirements.txtGPTBigCodeConfig en el paquete Transformers ubicado en your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py : class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )srun -p dgxh -tiempo = 2-00: 00: 00 -c 2 --grres = gpu: 2 -mem = 20g --pty Bash
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| Conjunto de datos | Longitud de secuencia | Gran función | AUC ROC | Puntaje F1 | GPU | Tiempo de entrenamiento (RRHH) | |
|---|---|---|---|---|---|---|---|
| Qlora | X₁ sin p₃ | 512 | ignorar | 0.53 | 0.65 | Tesla T4 | 8.2 |
| X₁ sin p₃ | 512 | incluir | 0.56 | 0.66 | Nvidia A100 x2 | 3.4 | |
| X₁ sin p₃ | 256 | ignorar | 0.51 | 0.63 | Tesla T4 | 2.9 | |
| X₁ con p₃ | 512 | ignorar | 0.68 | 0.14 | RTX 4080 | 22.1 | |
| X₁ con p₃ | 512 | incluir | 0.72 | 0.17 | Nvidia A100 x2 | 20.4 | |
| X₁ con p₃ | 256 | ignorar | 0.70 | 0.14 | Nvidia A100 x2 | 18.3 | |
| Lora | X₁ sin p₃ | 2048 | incluir | 0.69 | 0.71 | Nvidia v100 x8 | |
| X₁ con p₃ | 2048 | incluir | 0.86 | 0.27 | Nvidia v100 x8 |
En este artículo, recreamos los hallazgos de Shestov et al . en el que finetamos el LLM, WizardCoder, para la detección de vulnerabilidad del código. Si bien los autores originales usan Lora para hacerlo, empleamos Qlora para reducir el tamaño general del modelo y podemos entrenar dicho modelo en una GPU de grado de consumo. A pesar de esto, vemos una degradación significativa en las métricas de rendimiento, aunque está claro que el modelo todavía está haciendo algún tipo de aprendizaje . Además, realizamos la experimentación en la longitud de la secuencia de hiperparámetros e incluimos una gran función . Podemos concluir que incluir funciones grandes es un positivo estricto para las capacidades de aprendizaje del modelo, pero la evidencia sobre la longitud de la secuencia no es concluyente debido a un experimento desconcertante con resultados mucho más altos que el resto.
[1] Shestov, A., Levichev, R., Mussabayev, R., Maslov, E., Cheshkov, A. y Zadorozhny, P. (2024). Finecir modelos de lenguaje grande para la detección de vulnerabilidad . Preimpresión ARXIV ARXIV: 2401.17010. Recuperado de https://arxiv.org/abs/2401.17010.
[2] Hu, EJ, Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S. y Chen, W. (2021). Lora: adaptación de bajo rango de modelos de idiomas grandes. Preimpresión ARXIV ARXIV: 2106.09685. Recuperado de https://arxiv.org/abs/2106.09685.
[3] Dettmers, T., Pagnoni, A., Holtzman, A. y Zettlemoyer, L. (2023). Qlora: Fineting eficiente de LLM cuantificados. Prepódico ARXIV ARXIV: 2305.14314. Recuperado de https://arxiv.org/abs/2305.14314.


