LLM finetune vuln detection
1.0.0
Penulis: Yong-hwan Lee, James Flora, Shijie Zhao, dan Yunhan Qiao
Proyek ini mereplikasi dan dibangun di atas penelitian oleh Shestov et al. (2024) , bertujuan untuk memvalidasi dan memperluas temuan mereka. Penelitian asli berfokus pada penyempurnaan model bahasa besar (LLM) untuk deteksi kerentanan kode. Pendekatan ini menggunakan LoRA (adaptasi rendah), sebuah teknik yang melibatkan penambahan adaptor dalam lapisan untuk penyempurnaan. Selama proses ini, parameter model asli dibekukan , dan hanya adaptor yang dilatih, membuat proses pelatihan lebih hemat biaya.
Inovasi utama dari pekerjaan kami adalah penggabungan adaptasi khusus kami dari QLoRA , yang pertama kali mengukur LLM ke float 4-bit , secara signifikan mengurangi ukurannya. Sebagai contoh, model 13B-wizardCoder , awalnya sekitar 26 GB dan biasanya membutuhkan lebih dari 30 GB VRAM, dikurangi menjadi sekitar 7 GB setelah kuantisasi. Mengikuti kuantisasi, teknik LoRA diterapkan untuk fine-tuning.
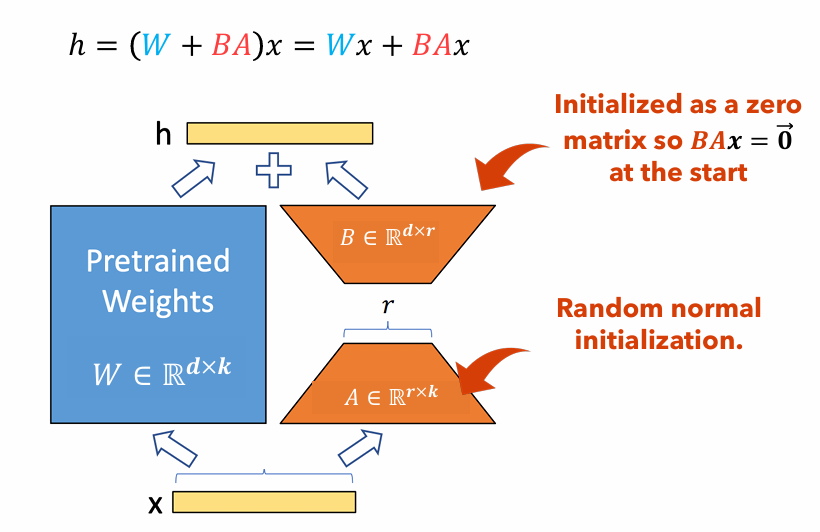
Gambar 1 : Ilustrasi Adaptor Lora
Gambar 1 menggambarkan bagaimana adaptor LORA dapat secara signifikan lebih kecil dari ukuran parameter asli. Jumlah parameter untuk
Misalnya, pertimbangkan lapisan dalam LLM dengan matriks berat
$ W di mathbb {r}^{1000 kali 100} $ . Jumlah parameter untuk$ W $ adalah$ 1000 kali 100 = 100.000 $ . Jika kami menetapkan peringkat Lora$ r = 5 $ , ukuran adaptor lora hanya$ 1000 kali 5 + 100 kali 5 = 5.500 $ . Ini berarti ukuran adaptor sekitar 5% dari matriks berat asli$ W $ , yang secara signifikan dapat dikelola untuk pelatihan sebagai matriks berat asli$ W $ tetap membeku selama fase pelatihan.
Dalam proyek ini, kami memvariasikan dataset , sequence length , dan the use of focal loss ; mengukur perubahan kinerja yang dihasilkan dibandingkan dengan LORA saja. Laporan untuk proyek ini: PDF
Dokumen ini memberikan instruksi terperinci untuk mereplikasi proyek penelitian kami. Ini mencakup langkah-langkah untuk menyiapkan lingkungan yang diperlukan, membuat perubahan kode yang diperlukan, menjalankan model pada cluster komputasi kinerja tinggi (HPC), dan menyajikan hasilnya.
pip install -r requirements.txtGPTBigCodeConfig di paket Transformers yang terletak di your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py :: class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )srun -p dgxh -waktu = 2-00: 00: 00 -c 2 --gres = gpu: 2 --mem = 20g --pty bash
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| Dataset | Panjang urutan | Fungsi besar | ROC AUC | Skor F1 | GPU | Waktu Pelatihan (SDM) | |
|---|---|---|---|---|---|---|---|
| Qlora | X₁ tanpa p₃ | 512 | mengabaikan | 0,53 | 0.65 | Tesla T4 | 8.2 |
| X₁ tanpa p₃ | 512 | termasuk | 0,56 | 0.66 | NVIDIA A100 X2 | 3.4 | |
| X₁ tanpa p₃ | 256 | mengabaikan | 0,51 | 0.63 | Tesla T4 | 2.9 | |
| X₁ dengan p₃ | 512 | mengabaikan | 0.68 | 0.14 | RTX 4080 | 22.1 | |
| X₁ dengan p₃ | 512 | termasuk | 0.72 | 0.17 | NVIDIA A100 X2 | 20.4 | |
| X₁ dengan p₃ | 256 | mengabaikan | 0,70 | 0.14 | NVIDIA A100 X2 | 18.3 | |
| Lora | X₁ tanpa p₃ | 2048 | termasuk | 0.69 | 0.71 | NVIDIA V100 X8 | |
| X₁ dengan p₃ | 2048 | termasuk | 0.86 | 0.27 | NVIDIA V100 X8 |
Dalam makalah ini, kami menciptakan kembali temuan Shestov et al . di mana kita finetune the llm, wizardcoder, untuk deteksi kerentanan kode. Sementara penulis asli menggunakan Lora untuk melakukannya, kami menggunakan qlora untuk mengurangi ukuran model keseluruhan dan mampu melatih model seperti itu pada GPU kelas konsumen. Meskipun demikian, kami melihat degradasi yang signifikan dalam metrik kinerja meskipun jelas bahwa model ini masih melakukan semacam pembelajaran . Lebih lanjut, kami melakukan eksperimen pada panjang urutan hyperparameters dan termasuk fungsi besar . Kami dapat menyimpulkan bahwa memasukkan fungsi besar adalah positif yang ketat untuk kemampuan belajar model, tetapi bukti tentang panjang urutan tidak meyakinkan karena percobaan yang membingungkan dengan hasil yang jauh lebih tinggi daripada yang lain.
[1] Shestov, A., Levichev, R., Mussabayev, R., Maslov, E., Cheshkov, A., & Zadorozhny, P. (2024). Finetuning model bahasa besar untuk deteksi kerentanan . ARXIV Preprint ARXIV: 2401.17010. Diperoleh dari https://arxiv.org/abs/2401.17010.
[2] Hu, EJ, Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., & Chen, W. (2021). Lora: Adaptasi rendah model bahasa besar. ARXIV Preprint ARXIV: 2106.09685. Diperoleh dari https://arxiv.org/abs/2106.09685.
[3] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). Qlora: Finetuning yang efisien dari LLMS terkuantisasi. ARXIV Preprint ARXIV: 2305.14314. Diperoleh dari https://arxiv.org/abs/2305.14314.


