LLM finetune vuln detection
1.0.0
Авторы: Юн-Хван Ли, Джеймс Флора, Шиджи Чжао и Юнхан Цяо
Этот проект повторяет и опирается на исследование Shestov et al. (2024) , стремясь проверить и расширить свои выводы. Первоначальное исследование было сосредоточено на тонкой настройке больших языковых моделей (LLMS) для обнаружения уязвимости кода. В подходе использовалась LoRA (адаптация с низкой оценкой), методику, которая включает в себя добавление адаптеров в слоях для точной настройки. В ходе этого процесса исходные параметры модели заморожены , и только адаптеры обучаются, что делает процесс обучения более рентабельным.
Ключевым инновацией нашей работы является включение нашей индивидуальной адаптации QLoRA , которая сначала определяет LLM до 4-битного поплавка , что значительно сокращает ее размер. Например, модель 13B-WizardCoder , первоначально около 26 ГБ и обычно требующая более 30 ГБ VRAM, уменьшается примерно до 7 ГБ после квантования. После квантования техника LoRA применяется для точной настройки.
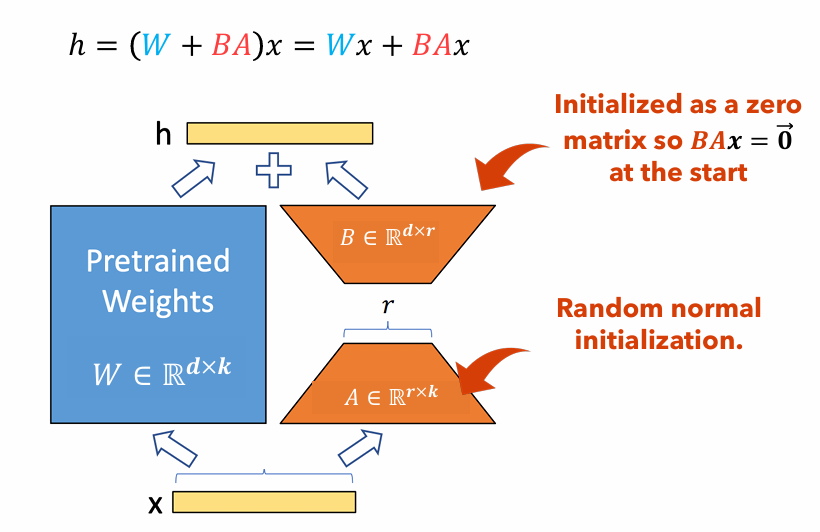
Рисунок 1 : Иллюстрация адаптера LORA
На рисунке 1 показано, как адаптеры LORA могут быть значительно меньше, чем исходные размеры параметров. Количество параметров для
Например, рассмотрим слой в LLM с матрицей веса
$ W in mathbb {r}^{1000 times 100} $ Полем Количество параметров для$ W $ является$ 1000 раз 100 = 100 000 $ Полем Если мы установим звание Лоры на$ r = 5 $ , размер адаптеров Lora только$ 1000 Times 5 + 100 Times 5 = 5500 $ Полем Это означает, что размер адаптера составляет около 5% от исходной матрицы веса$ W $ , который значительно управляется для обучения в качестве оригинальной матрицы веса$ W $ остается замороженным на этапе тренировок.
В этом проекте мы варьировали dataset , sequence length и the use of focal loss ; измерил полученные изменения в производительности по сравнению с одной Лорой. Отчет для этого проекта: pdf
Этот документ содержит подробные инструкции по воспроизведению нашего исследовательского проекта. Он включает в себя шаги для настройки необходимой среды, внесения необходимых изменений кода, запуска модели в высокопроизводительных вычислительных (HPC) кластере и представление результатов.
pip install -r requirements.txtGPTBigCodeConfig в пакете Transformers, расположенном по адресу your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py : class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )srun -p dgxh -time = 2-00: 00: 00 -c 2 --gres = gpu: 2 -mem = 20g -pty bash
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| Набор данных | Длина последовательности | Большая функция | ROC AUC | F1 Оценка | Графический процессор | Время обучения (HR) | |
|---|---|---|---|---|---|---|---|
| Qlora | X₁ без p₃ | 512 | игнорировать | 0,53 | 0,65 | Тесла Т4 | 8.2 |
| X₁ без p₃ | 512 | включать | 0,56 | 0,66 | NVIDIA A100 X2 | 3.4 | |
| X₁ без p₃ | 256 | игнорировать | 0,51 | 0,63 | Тесла Т4 | 2.9 | |
| X₁ с p₃ | 512 | игнорировать | 0,68 | 0,14 | RTX 4080 | 22.1 | |
| X₁ с p₃ | 512 | включать | 0,72 | 0,17 | NVIDIA A100 X2 | 20.4 | |
| X₁ с p₃ | 256 | игнорировать | 0,70 | 0,14 | NVIDIA A100 X2 | 18.3 | |
| Лора | X₁ без p₃ | 2048 | включать | 0,69 | 0,71 | Nvidia v100 x8 | |
| X₁ с p₃ | 2048 | включать | 0,86 | 0,27 | Nvidia v100 x8 |
В этой статье мы воссоздаем выводы Shestov et al . в котором мы определяем LLM, WizardCoder, для обнаружения уязвимости кода. В то время как оригинальные авторы используют Lora для этого, мы используем Qlora для сокращения общего размера модели и способны обучать такую модель на графическом процессоре потребительского уровня. Несмотря на это, мы видим значительную деградацию в показателях производительности, хотя ясно, что модель все еще делает какое -то обучение . Кроме того, мы проводим эксперименты по длине последовательности гиперпараметра и включаем большую функцию . Мы можем сделать вывод, что включение больших функций является строгим положительным для обучения модели, но данные о длине последовательности неубедительны из -за сбивающего за собой эксперимента с гораздо более высокими результатами, чем остальные.
[1] Shestov, A., Levichev, R., Mussabayev, R., Maslov E., Cheshkov, A. & Zadorozhny, P. (2024). Создание больших языковых моделей для обнаружения уязвимости . Arxiv Preprint arxiv: 2401.17010. Получено с https://arxiv.org/abs/2401.17010.
[2] Hu, EJ, Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S. & Chen, W. (2021). LORA: Низкая адаптация крупных языковых моделей. Arxiv Preprint arxiv: 2106.09685. Получено с https://arxiv.org/abs/2106.09685.
[3] Dettmers, T., Pagnoni, A., Holtzman, A. & Zettlemoyer, L. (2023). Qlora: Эффективное создание квантовых LLMS. Arxiv Preprint arxiv: 2305.14314. Получено с https://arxiv.org/abs/2305.14314.


