LLM finetune vuln detection
1.0.0
Auteurs: Yong-Hwan Lee, James Flora, Shijie Zhao et Yunhan Qiao
Ce projet reproduit et s'appuie sur l'étude par Shestov et al. (2024) , visant à valider et à étendre leurs résultats. La recherche originale s'est concentrée sur les modèles de grande langue (LLM) pour la détection de vulnérabilité du code. L'approche a utilisé LoRA (adaptation de faible rang), une technique qui implique d'ajouter des adaptateurs dans les couches pour un réglage fin. Au cours de ce processus, les paramètres du modèle d'origine sont gelés et seuls les adaptateurs sont formés, ce qui rend le processus de formation plus rentable.
Une innovation clé de notre travail est l'incorporation de notre adaptation personnalisée de QLoRA , qui quantise d'abord le LLM à un flotteur 4 bits , réduisant considérablement sa taille. Par exemple, le modèle 13b-wizardcoder , à l'origine environ 26 Go et nécessitant généralement plus de 30 Go de VRAM, est réduit à environ 7 Go après la quantification. Après la quantification, la technique LoRA est appliquée à un réglage fin.
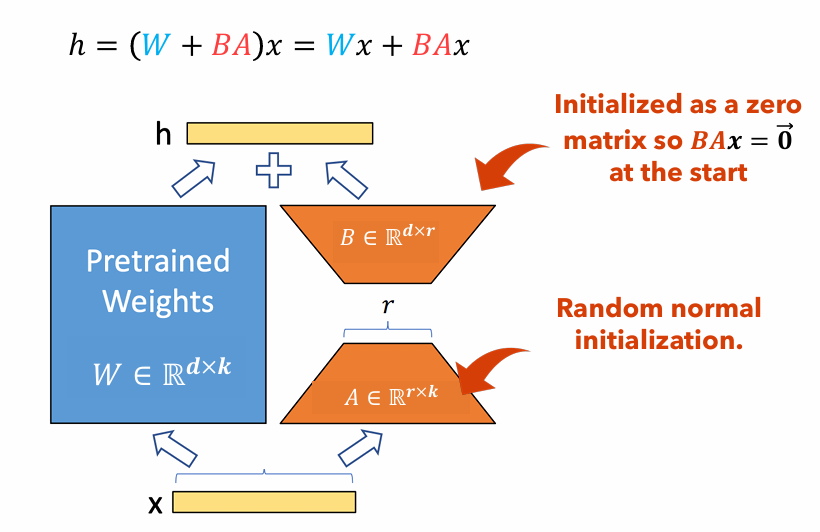
Figure 1 : illustration de l'adaptateur LORA
La figure 1 illustre comment les adaptateurs LORA peuvent être considérablement plus petits que les tailles de paramètres d'origine. Le nombre de paramètres pour le
Par exemple, considérez une couche dans un LLM avec une matrice de poids
$ W in mathbb {r} ^ {1000 fois 100} $ . Le nombre de paramètres pour$ W $ est1000 $ fois 100 = 100 000 $ . Si nous définissons le rang de Lora à$ r = 5 $ , la taille des adaptateurs LORA est uniquement1000 $ fois 5 + 100 fois 5 = 5 500 $ . Cela signifie que la taille de l'adaptateur est d'environ 5% de la matrice de poids d'origine$ W $ , qui est considérablement gérable pour la formation comme la matrice de poids d'origine$ W $ Reste gelé pendant la phase d'entraînement.
Dans ce projet, nous avons varié l' dataset , sequence length et the use of focal loss ; mesuré les changements de performance résultants par rapport à Lora seuls. Le rapport de ce projet: PDF
Ce document fournit des instructions détaillées pour reproduire notre projet de recherche. Il comprend des étapes pour configurer l'environnement nécessaire, effectuer des modifications de code requises, exécuter le modèle sur un cluster informatique haute performance (HPC) et présenter les résultats.
pip install -r requirements.txtGPTBigCodeConfig dans le package Transformers situé sur your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py : class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )srun -p dgxh - time = 2-00: 00: 00 -c 2 --gres = gpu: 2 --mem = 20g - pty bash
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| Ensemble de données | Longueur de séquence | Grande fonction | Roc AUC | Score F1 | GPU | Temps de formation (RH) | |
|---|---|---|---|---|---|---|---|
| Qlora | X₁ sans p₃ | 512 | ignorer | 0,53 | 0,65 | Tesla T4 | 8.2 |
| X₁ sans p₃ | 512 | inclure | 0,56 | 0,66 | Nvidia a100 x2 | 3.4 | |
| X₁ sans p₃ | 256 | ignorer | 0,51 | 0,63 | Tesla T4 | 2.9 | |
| X₁ avec p₃ | 512 | ignorer | 0,68 | 0,14 | RTX 4080 | 22.1 | |
| X₁ avec p₃ | 512 | inclure | 0,72 | 0,17 | Nvidia a100 x2 | 20.4 | |
| X₁ avec p₃ | 256 | ignorer | 0,70 | 0,14 | Nvidia a100 x2 | 18.3 | |
| Lora | X₁ sans p₃ | 2048 | inclure | 0,69 | 0,71 | Nvidia v100 x8 | |
| X₁ avec p₃ | 2048 | inclure | 0,86 | 0,27 | Nvidia v100 x8 |
Dans cet article, nous recréons les résultats de Shestov et al . dans lequel nous Finetune le LLM, WizardCoder, pour la détection de vulnérabilité du code. Alors que les auteurs d'origine utilisent LORA pour le faire, nous utilisons Qlora pour réduire la taille globale du modèle et pouvons former un tel modèle sur un GPU de base. Malgré cela, nous constatons une dégradation significative des mesures de performance, bien qu'il soit clair que le modèle fait toujours une sorte d' apprentissage . De plus, nous effectuons l'expérimentation sur la longueur de séquence des hyperparamètres et incluons une grande fonction . Nous sommes en mesure de conclure que l'inclusion de grandes fonctions est un strict positif pour les capacités d'apprentissage du modèle, mais les preuves de la longueur de séquence ne sont pas concluantes en raison d'une expérience déroutante avec des résultats beaucoup plus élevés que les autres.
[1] Shestov, A., Levichev, R., Mussabayev, R., Maslov, E., Cheshkov, A., et Zadorozhny, P. (2024). Fintuning de grands modèles de langue pour la détection de vulnérabilité . ARXIV PRÉALLAGE ARXIV: 2401.17010. Extrait de https://arxiv.org/abs/2401.17010.
[2] Hu, EJ, Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., et Chen, W. (2021). LORA: Adaptation de faible rang des modèles de grands langues. ARXIV PRÉALLAGE ARXIV: 2106.09685. Extrait de https://arxiv.org/abs/2106.09685.
[3] Dettmers, T., Pagnoni, A., Holtzman, A., et Zettlemoyer, L. (2023). QLORA: Finetuning efficace des LLM quantifiés. ARXIV PRÉALLAGE ARXIV: 2305.14314. Extrait de https://arxiv.org/abs/2305.14314.


