LLM finetune vuln detection
1.0.0
Autores: Yong-Hwan Lee, James Flora, Shijie Zhao e Yuns Qiao
Este projeto se replica e se baseia no estudo de Shestov et al. (2024) , com o objetivo de validar e estender suas descobertas. A pesquisa original se concentrou em grandes modelos de idiomas (LLMS) para detecção de vulnerabilidades de código. A abordagem utilizou LoRA (adaptação de baixo rank), uma técnica que envolve a adição de adaptadores dentro de camadas para ajuste fino. Durante esse processo, os parâmetros originais do modelo são congelados e apenas os adaptadores são treinados, tornando o processo de treinamento mais econômico.
Uma inovação importante do nosso trabalho é a incorporação de nossa adaptação personalizada da QLoRA , que primeiro quantiza o LLM a um bóia de 4 bits , reduzindo significativamente seu tamanho. Por exemplo, o modelo 13B-WizardCoder , originalmente em torno de 26 GB e geralmente exigindo mais de 30 GB de VRAM, é reduzido para aproximadamente 7 GB após a quantização. Após a quantização, a técnica LoRA é aplicada para ajuste fino.
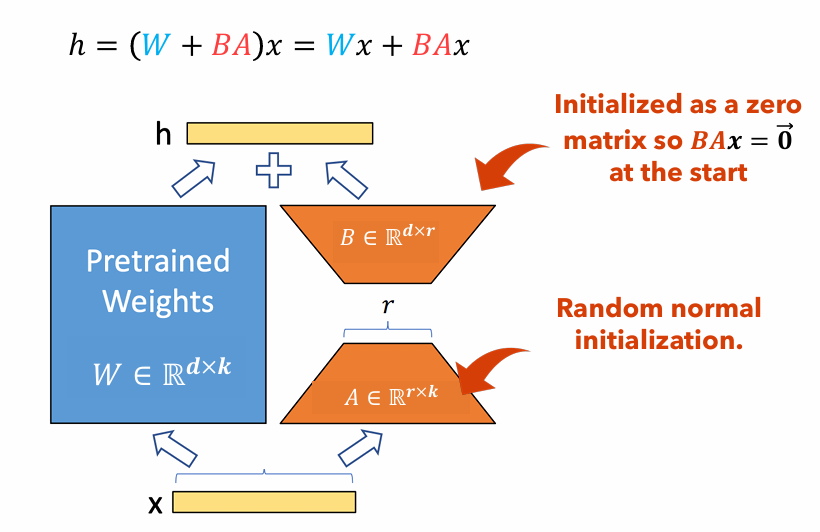
Figura 1 : Ilustração do adaptador Lora
A Figura 1 ilustra como os adaptadores LORA podem ser significativamente menores que os tamanhos de parâmetros originais. O número de parâmetros para o
Por exemplo, considere uma camada em um LLM com uma matriz de peso
$ W in mathbb {r}^{1000 times 100} $ . O número de parâmetros para$ W $ é$ 1000 Times 100 = 100.000 $ . Se definirmos a classificação da Lora para$ r = 5 $ , o tamanho dos adaptadores Lora é apenas$ 1000 vezes 5 + 100 vezes 5 = 5.500 $ . Isso significa que o tamanho do adaptador é de cerca de 5% da matriz de peso original$ W $ , o que é significativamente gerenciável para o treinamento como a matriz de peso original$ W $ permanece congelado durante a fase de treinamento.
Neste projeto, variamos o dataset , sequence length e the use of focal loss ; mediu as mudanças de desempenho resultantes em comparação apenas com Lora. O relatório para este projeto: PDF
Este documento fornece instruções detalhadas para replicar nosso projeto de pesquisa. Ele inclui etapas para configurar o ambiente necessário, fazer alterações de código necessárias, executar o modelo em um cluster de computação de alto desempenho (HPC) e apresentar os resultados.
pip install -r requirements.txtGPTBigCodeConfig no pacote Transformers localizado em your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py : class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )srun -p dgxh -time = 2-00: 00: 00 -c 2 --gres = gpu: 2 - -mem = 20g --pty Bash
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| Conjunto de dados | Comprimento da sequência | Grande função | Roc auc | Pontuação F1 | GPU | Tempo de treinamento (RH) | |
|---|---|---|---|---|---|---|---|
| Qlora | X₁ sem p₃ | 512 | ignorar | 0,53 | 0,65 | Tesla T4 | 8.2 |
| X₁ sem p₃ | 512 | incluir | 0,56 | 0,66 | Nvidia A100 x2 | 3.4 | |
| X₁ sem p₃ | 256 | ignorar | 0,51 | 0,63 | Tesla T4 | 2.9 | |
| X₁ com p₃ | 512 | ignorar | 0,68 | 0,14 | RTX 4080 | 22.1 | |
| X₁ com p₃ | 512 | incluir | 0,72 | 0,17 | Nvidia A100 x2 | 20.4 | |
| X₁ com p₃ | 256 | ignorar | 0,70 | 0,14 | Nvidia A100 x2 | 18.3 | |
| Lora | X₁ sem p₃ | 2048 | incluir | 0,69 | 0,71 | Nvidia v100 x8 | |
| X₁ com p₃ | 2048 | incluir | 0,86 | 0,27 | Nvidia v100 x8 |
Neste artigo, recriamos os achados de Shestov et al . em que finalizamos o LLM, WizardCoder, para detecção de vulnerabilidade de código. Enquanto os autores originais usam Lora para fazer isso, empregamos a Qlora para reduzir o tamanho geral do modelo e conseguir treinar esse modelo em uma GPU de nível de consumo. Apesar disso, vemos uma degradação significativa nas métricas de desempenho, embora fique claro que o modelo ainda está aprendendo . Além disso, realizamos experimentação no comprimento da sequência dos hiperparâmetros e incluímos grandes funções . Somos capazes de concluir que a inclusão de grandes funções é um positivo rigoroso para os recursos de aprendizado do modelo, mas a evidência sobre o comprimento da sequência é inconclusiva devido a um experimento desconcertante com resultados muito mais altos que o restante.
[1] Shestov, A., Levichev, R., Mussabayev, R., Maslov, E., Cheshkov, A., & Zadorozhny, P. (2024). Finetuning Grandes modelos de idiomas para detecção de vulnerabilidades . Arxiv pré -impressão arxiv: 2401.17010. Recuperado em https://arxiv.org/abs/2401.17010.
[2] Hu, Ej, Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., & Chen, W. (2021). Lora: adaptação de baixo rank de grandes modelos de linguagem. ARXIV ARXIV ARXIV: 2106.09685. Recuperado em https://arxiv.org/abs/2106.09685.
[3] Dettmers, T., Pagnoni, A., Holtzman, A. e Zettlemoyer, L. (2023). Qlora: Finetuning eficiente de LLMs quantizados. Arxiv pré -impressão Arxiv: 2305.14314. Recuperado em https://arxiv.org/abs/2305.14314.


