LLM finetune vuln detection
1.0.0
المؤلفون: يونغ هوان لي ، جيمس فلورا ، شيجي تشاو ، ويونهان تشياو
هذا المشروع يكرر ويعتمد على الدراسة التي أجراها شستوف وآخرون. (2024) ، بهدف التحقق من صحة وتوسيع نتائجهم. ركز البحث الأصلي على صياغة نماذج اللغة الكبيرة (LLMS) للكشف عن ثغرة الكود. استخدم النهج LoRA (التكيف منخفض الرتبة) ، وهي تقنية تتضمن إضافة محولات داخل طبقات للضبط. خلال هذه العملية ، يتم تجميد معلمات النموذج الأصلي ، ويتم تدريب المحولات فقط ، مما يجعل عملية التدريب أكثر فعالية من حيث التكلفة.
أحد الابتكار الرئيسي لعملنا هو دمج تكيفنا المخصص لـ QLoRA ، والذي يقوم أولاً بتكميات LLM إلى تعويم 4 بت ، مما يقلل بشكل كبير من حجمه. على سبيل المثال ، يتم تقليل طراز 13B-WizardCoder ، الذي يبلغ حوالي 26 جيجابايت ، ويتطلب عادةً أكثر من 30 جيجابايت من VRAM ، إلى حوالي 7 جيجابايت بعد القياس الكمي. بعد القياس الكمي ، يتم تطبيق تقنية LoRA للضبط.
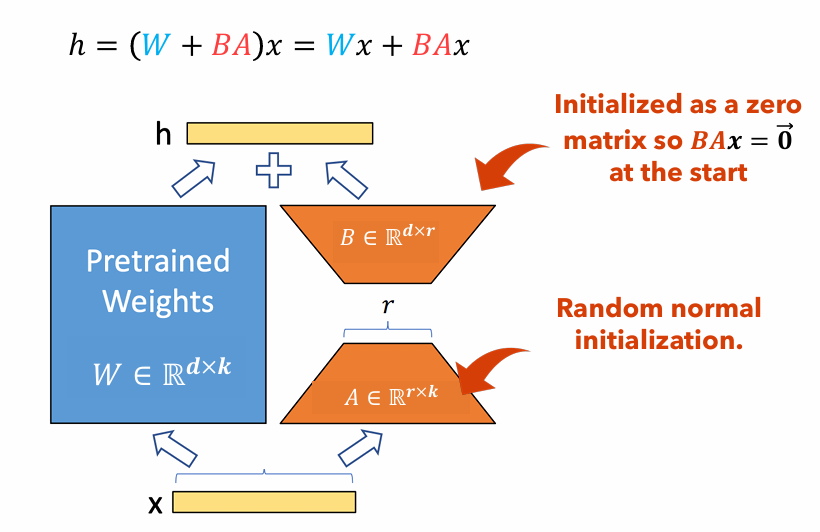
الشكل 1 : توضيح محول لورا
يوضح الشكل 1 كيف يمكن أن تكون محولات LORA أصغر بكثير من أحجام المعلمات الأصلية. عدد المعلمات ل
على سبيل المثال ، فكر في طبقة في LLM مع مصفوفة الوزن
$ w in mathbb {r}^{1000 times 100} $ . عدد المعلمات ل$ w $ يكون1000 دولار مرات 100 = 100،000 دولار . إذا قمنا بتعيين رتبة لورا$ r = 5 $ ، حجم محولات Lora هو فقط1000 دولار مرات 5 + 100 مرات 5 = 5500 دولار . هذا يعني أن حجم المحول هو حوالي 5 ٪ من مصفوفة الوزن الأصلية$ w $ ، وهو أمر يمكن التحكم فيه بشكل كبير للتدريب كمصفوفة للوزن الأصلي$ w $ لا يزال متجمدًا خلال مرحلة التدريب.
في هذا المشروع ، قمنا بتنوع dataset sequence length the use of focal loss ؛ قياس التغييرات الأداء الناتجة مقارنة مع لورا وحدها. تقرير هذا المشروع: PDF
يوفر هذا المستند إرشادات مفصلة لتكرار مشروع البحث الخاص بنا. ويتضمن خطوات لإعداد البيئة اللازمة ، وإجراء تغييرات في التعليمات البرمجية المطلوبة ، وتشغيل النموذج على مجموعة الحوسبة عالية الأداء (HPC) ، وتقديم النتائج.
pip install -r requirements.txtGPTBigCodeConfig في حزمة Transformers الموجودة في your_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )Srun -P DGXH -Time = 2-00: 00: 00 -C 2 -GRES = GPU: 2 -MEM = 20G -PTY BASH
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| مجموعة البيانات | طول التسلسل | وظيفة كبيرة | ROC AUC | درجة F1 | GPU | وقت التدريب (HR) | |
|---|---|---|---|---|---|---|---|
| qlora | x₁ بدون p₃ | 512 | يتجاهل | 0.53 | 0.65 | تسلا T4 | 8.2 |
| x₁ بدون p₃ | 512 | يشمل | 0.56 | 0.66 | Nvidia A100 x2 | 3.4 | |
| x₁ بدون p₃ | 256 | يتجاهل | 0.51 | 0.63 | تسلا T4 | 2.9 | |
| x₁ مع p₃ | 512 | يتجاهل | 0.68 | 0.14 | RTX 4080 | 22.1 | |
| x₁ مع p₃ | 512 | يشمل | 0.72 | 0.17 | Nvidia A100 x2 | 20.4 | |
| x₁ مع p₃ | 256 | يتجاهل | 0.70 | 0.14 | Nvidia A100 x2 | 18.3 | |
| لورا | x₁ بدون p₃ | 2048 | يشمل | 0.69 | 0.71 | NVIDIA V100 x8 | |
| x₁ مع p₃ | 2048 | يشمل | 0.86 | 0.27 | NVIDIA V100 x8 |
في هذه الورقة ، نعيد إنشاء نتائج Shestov et al . حيث نقوم بتأليف LLM ، WizardCoder ، للكشف عن قابلية الضعف. في حين أن المؤلفين الأصليين يستخدمون Lora للقيام بذلك ، فإننا نستخدم Qlora لخفض حجم النموذج العام ونكون قادرين على تدريب مثل هذا النموذج على وحدة معالجة الرسومات على مستوى المستهلك. على الرغم من ذلك ، فإننا نرى تدهورًا كبيرًا في مقاييس الأداء على الرغم من أنه من الواضح أن النموذج لا يزال يفعل نوعًا من التعلم . علاوة على ذلك ، نقوم بإجراء تجريب على طول تسلسل HyperParameters ونشمل وظيفة كبيرة . نحن قادرون على استنتاج أن تضمين الوظائف الكبيرة يعد إيجابيًا صارمًا لقدرات التعلم للنموذج ، ولكن الأدلة على طول التسلسل غير حاسم بسبب تجربة محيرة مع نتائج أعلى بكثير من الباقي.
[1] شستوف ، أ. نماذج لغة كبيرة لاكتشاف الضعف . Arxiv preprint Arxiv: 2401.17010. تم الاسترجاع من https://arxiv.org/abs/2401.17010.
[2] Hu ، EJ ، Shen ، Y. ، Wallis ، P. ، Allen-Zhu ، Z. ، Li ، Y. ، Wang ، S. ، & Chen ، W. (2021). لورا: التكيف منخفض الرتبة لنماذج اللغة الكبيرة. Arxiv preprint Arxiv: 2106.09685. تم الاسترجاع من https://arxiv.org/abs/2106.09685.
[3] Dettmers ، T. ، Pagnoni ، A. ، Holtzman ، A. ، & Zettlemoyer ، L. (2023). qlora: فني فعال من LLMs الكمية. Arxiv preprint Arxiv: 2305.14314. تم الاسترجاع من https://arxiv.org/abs/2305.14314.


