LLM finetune vuln detection
1.0.0
저자 : Yong-wan Lee, James Flora, Shijie Zhao 및 Yunhan Qiao
이 프로젝트는 Shestov et al. 의 연구를 복제하고 기반으로합니다. (2024) , 결과를 검증하고 확장하는 것을 목표로합니다. 원래 연구는 코드 취약성 탐지를위한 LLM (Large Language Model) (LLM)을 미세 조정하는 데 중점을 두었습니다. 이 접근법은 미세 조정을 위해 층 내에 어댑터를 추가하는 기술인 LoRA (저 순위 적응)를 사용했습니다. 이 과정에서 원래 모델 매개 변수가 동결 되고 어댑터 만 훈련되어 교육 프로세스가 더욱 비용 효율적입니다.
우리의 작업의 주요 혁신은 QLoRA 의 맞춤형 적응을 통합하는 것입니다. Qlora는 먼저 LLM을 4 비트 플로트 로 정량화하여 크기를 크게 줄입니다. 예를 들어, 원래 약 26GB 이며 일반적으로 30GB 이상의 VRAM을 필요로하는 13B-WizardCoder 모델은 양자화 후 약 7GB 로 감소됩니다. 양자화 후, LoRA 기술은 미세 조정에 적용됩니다.
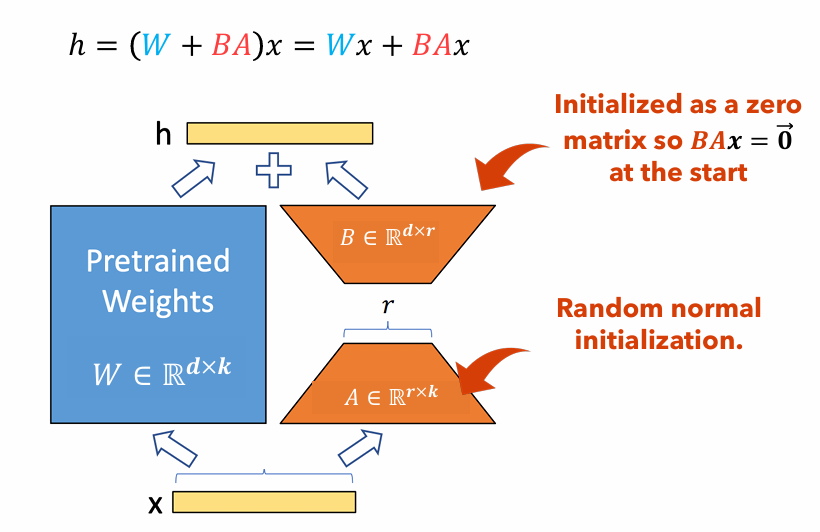
그림 1 : LORA 어댑터 그림
그림 1은 LORA 어댑터가 원래 매개 변수 크기보다 상당히 작을 수있는 방법을 보여줍니다. 매개 변수 수
예를 들어, 무게 매트릭스가있는 LLM의 레이어를 고려하십시오.
$ w in mathbb {r}^{1000 times 100} $ . 매개 변수 수$ W $ ~이다$ 1000 Times 100 = 100,000 $ . 우리가 로라 순위를 설정하면$ r = 5 $ LORA 어댑터의 크기는 전용입니다$ 1000 Times 5 + 100 Times 5 = 5,500 $ . 이것은 어댑터 크기가 원래 무게 매트릭스의 약 5%임을 의미합니다.$ W $ 원래 무게 매트릭스로 훈련을 위해 매우 관리 할 수 있습니다.$ W $ 훈련 단계에서 얼어 붙었습니다.
이 프로젝트에서는 dataset , sequence length 및 the use of focal loss 변화 시켰습니다. LORA에 비해 결과 성능 변경을 측정했습니다. 이 프로젝트의 보고서 : PDF
이 문서는 연구 프로젝트를 복제하기위한 자세한 지침을 제공합니다. 필요한 환경을 설정하고 필요한 코드 변경, 고성능 컴퓨팅 (HPC) 클러스터에서 모델을 실행하고 결과를 제시하기위한 단계가 포함됩니다.
pip install -r requirements.txtyour_venv/lib/python3.10/site-packages/transformers/models/gpt_bigcode/configuration_gpt_bigcode.py 에 위치한 Transformers 패키지의 GPTBigCodeConfig 클래스에 다음 함수를 추가하십시오. class GPTBigCodeConfig :
# ... other methods and attributes ...
def set_special_params ( self , args ):
self . args = vars ( args )./vul-llm-finetune/LLM/starcoder/run.py 에서 디렉토리 경로를 변경하십시오 sys . path . append ( "my_path/vul-llm-finetune/LLM/starcoder" )srun -p dgxh -time = 2-00 : 00 : 00 -c 2 -Gres = gpu : 2 --mem = 20g -pty bash
python vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--split= " train "
--lora_r 8
--seq_length 512
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_test/ '
--delete_whitespaces
--several_funcs_in_batch
--debug_on_small_modelpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " train "
--lora_r 8
--use_focal_loss
--focal_loss_gamma 1
--seq_length 512
--num_train_epochs 15
--batch_size 1
--gradient_accumulation_steps 160
--learning_rate 1e-4
--weight_decay 0.05
--num_warmup_steps 2
--log_freq=1
--output_dir= ' vul-llm-finetune/outputs/results_0/ '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batchpython vul-llm-finetune/LLM/starcoder/finetune/run.py
--dataset_tar_gz= ' vul-llm-finetune/Datasets/with_p3/java_k_1_strict_2023_06_30.tar.gz '
--load_quantized_model
--split= " test "
--run_test_peft
--lora_r 8
--seq_length 512
--checkpoint_dir= ' vul-llm-finetune/outputs/results_0 '
--model_checkpoint_path= ' final_checkpoint '
--delete_whitespaces
--base_model starcoder
--several_funcs_in_batch| 데이터 세트 | 시퀀스 길이 | 큰 기능 | ROC AUC | F1 점수 | GPU | 훈련 시간 (HR) | |
|---|---|---|---|---|---|---|---|
| Qlora | p₃없는 x₁ | 512 | 무시하다 | 0.53 | 0.65 | 테슬라 T4 | 8.2 |
| p₃없는 x₁ | 512 | 포함하다 | 0.56 | 0.66 | NVIDIA A100 X2 | 3.4 | |
| p₃없는 x₁ | 256 | 무시하다 | 0.51 | 0.63 | 테슬라 T4 | 2.9 | |
| x x p₃ | 512 | 무시하다 | 0.68 | 0.14 | RTX 4080 | 22.1 | |
| x x p₃ | 512 | 포함하다 | 0.72 | 0.17 | NVIDIA A100 X2 | 20.4 | |
| x x p₃ | 256 | 무시하다 | 0.70 | 0.14 | NVIDIA A100 X2 | 18.3 | |
| 로라 | p₃없는 x₁ | 2048 | 포함하다 | 0.69 | 0.71 | NVIDIA V100 X8 | |
| x x p₃ | 2048 | 포함하다 | 0.86 | 0.27 | NVIDIA V100 X8 |
이 논문에서는 Shestov et al . 코드 취약성 감지를 위해 LLM, 마법사 인 마법사를 미세화합니다. 원래의 저자는 LORA를 사용하여 Qlora를 사용하여 전체 모델 크기를 줄이고 소비자 등급 GPU에서 그러한 모델을 훈련시킬 수 있습니다. 그럼에도 불구하고, 우리는 성능 지표에서 상당한 저하가 발생하지만 모델이 여전히 일종의 학습을 수행하고 있음이 분명합니다. 또한, 우리는 하이퍼 파라미터 서열 길이 에 대한 실험을 수행하고 큰 기능을 포함합니다 . 우리는 큰 기능을 포함시키는 것이 모델의 학습 기능에 엄격한 긍정적이라는 결론을 내릴 수 있지만, 시퀀스 길이에 대한 증거는 나머지보다 훨씬 높은 결과를 가진 당황 실험으로 인해 결정적이지 않습니다.
[1] Shestov, A., Levichev, R., Mussabayev, R., Maslov, E., Cheshkov, A., & Zadorozhny, P. (2024). 취약성 탐지를위한 대형 언어 모델을 미세 조정합니다 . ARXIV PREPRINT ARXIV : 2401.17010. https://arxiv.org/abs/2401.17010에서 검색했습니다.
[2] Hu, EJ, Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., & Chen, W. (2021). LORA : 대형 언어 모델의 낮은 순위 적응. ARXIV PREPRINT ARXIV : 2106.09685. https://arxiv.org/abs/2106.09685에서 검색했습니다.
[3] Dettmers, T., Pagnoni, A., Holtzman, A., & Zettlemoyer, L. (2023). Qlora : 양자화 된 LLM의 효율적인 양조. Arxiv preprint arxiv : 2305.14314. https://arxiv.org/abs/2305.14314에서 검색했습니다.


