MedQA ChatGLM
1.0.0
Note
歡迎關注我們最新的工作:CareLlama (關懷羊駝),它是一個醫療大語言模型,同時它集合了數十個公開可用的醫療微調數據集和開放可用的醫療大語言模型以促進醫療LLM快速發展:https://github.com/WangRongsheng/CareLlama
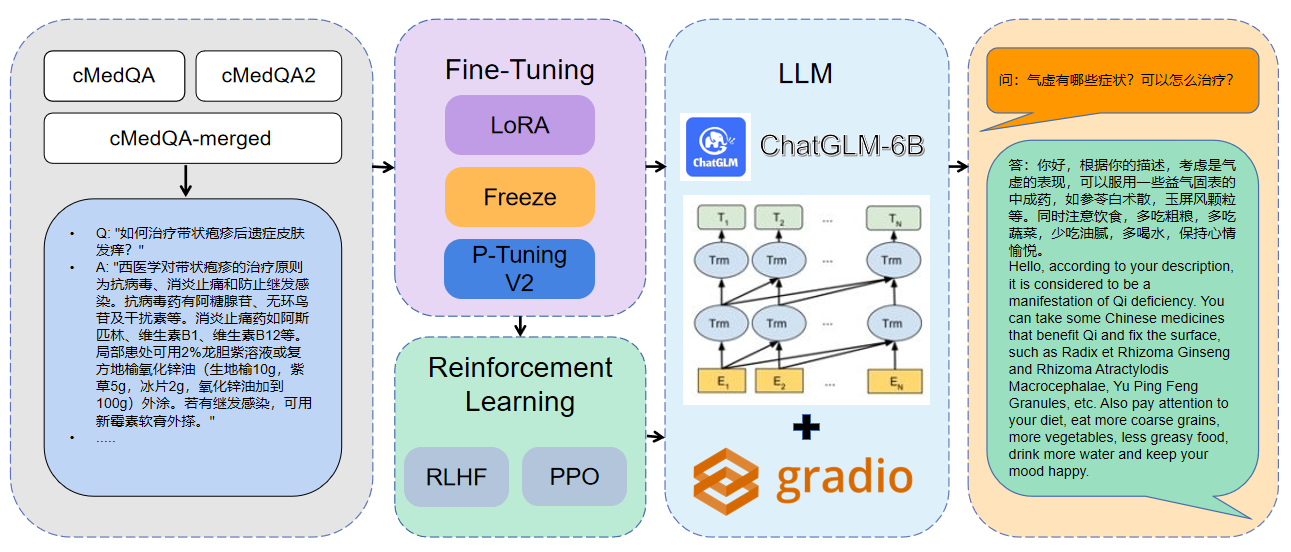
1使用的數據為cMedQA2
| 專案 | 數據集 | 底座模型 |
|---|---|---|
| ChatMed | Consult 包含50w+在線問診+ChatGPT回复,TCM中醫藥診療數據集未公開 | LLaMA-7B |
| ChatDoctor | HealthCareMagic-100k 包含100k+真實患者與醫生對話數據集,icliniq-10k 包含10k+患者與醫生對話數據集,GenMedGPT-5k 包含5k+由GPT生成的醫患對話數據集 | LLaMA-7B |
| Med-ChatGLM | Huatuo-data 、Huatuo-liver-cancer | ChatGLM-6B |
| Huatuo-Llama-Med-Chinese | Huatuo-data 、Huatuo-liver-cancer | LLaMA-7B |
| DoctorGLM | CMD. 、MedDialog 、ChatDoctor項目數據集 | ChatGLM-6B |
| MedicalGPT-zh | 數據未開源 | ChatGLM-6B |
| Dr.LLaMA | LLaMA | |
| Medical_NLP 2 | - | - |
| CMCQA 3 | - | - |
| QiZhenGPT | - | - |
| LLM-Pretrain-FineTune | - | - |
| PMC-LLaMA | - | LLaMA-7B |
| BianQue | - | - |
| medAlpaca | - | LLaMA-7B |
| MedicalGPT | - | - |
| LLM-Pretrain-FineTune | - | - |
| ShenNong-TCM-LLM | - | - |
| Sunsimiao | - | - |
| CMLM-ZhongJing | - | - |
| ZhongJing | - | - |
| Ming | - | - |
| DISC-MedLLM | - | - |
pip install - r requirements . txt CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type lora
- - output_dir . / med - lora
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type freeze
- - output_dir . / med - freeze
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 1 python MedQA - ChatGLM / finetune . py
- - do_train - - dataset merged - cMedQA
- - finetuning_type p_tuning
- - output_dir . / med - p_tuning
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16更多參數信息,可以查看docs/參數詳解.md .
多GPU分佈式訓練:
# 配置分布式参数
accelerate config
# 分布式训练
accelerate launch src / finetune . py
- - do_train
- - dataset Huatuo , CMD , MedDialog , guanaco , cognition
- - finetuning_type lora
- - output_dir med - lora
- - per_device_train_batch_size 16
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 3.0
- - fp16
- - ddp_find_unused_parameters False # 分布式训练时,LoRA微调需要添加防止报错
- - plot_loss CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / web_demo . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / ) CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / infer . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / )合併模型:
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / export_weights . py
- - finetuning_weights_path . / med - lora
- - save_weights_path . / save_lora加載合併模型:
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / load_export_weights . py
- - save_weights_path . / save_lora| 微調方式 | 模型權重 | 訓練時長 | 訓練輪次 |
|---|---|---|---|
| LoRA | MedQA-ChatGLM-LoRA | 28h | 10 |
| P-Tuning V2 | MedQA-ChatGLM-PTuningV2 | 27h | 10 |
| Freeze | MedQA-ChatGLM-Freeze | 28h | 10 |
* 實驗是在Linux系統,A100 (1X, 80GB)上進行的
本項目相關資源僅供學術研究之用,嚴禁用於商業用途。使用涉及第三方代碼的部分時,請嚴格遵循相應的開源協議。模型生成的內容受模型計算、隨機性和量化精度損失等因素影響,本項目無法對其準確性作出保證。本項目數據集絕大部分由模型生成,即使符合某些醫學事實,也不能被用作實際醫學診斷的依據。對於模型輸出的任何內容,本項目不承擔任何法律責任,亦不對因使用相關資源和輸出結果而可能產生的任何損失承擔責任。


