MedQA ChatGLM
1.0.0
메모
우리의 최신 작품에 오신 것을 환영합니다 : Carellama (Care Alpaca)는 의료 LLM의 빠른 개발을 촉진하기 위해 수십 개의 공개적으로 이용 가능한 의료용 미세 조정 데이터 세트와 공개적으로 이용 가능한 의료 대형 언어 모델을 결합한 의료 대형 언어 모델입니다.
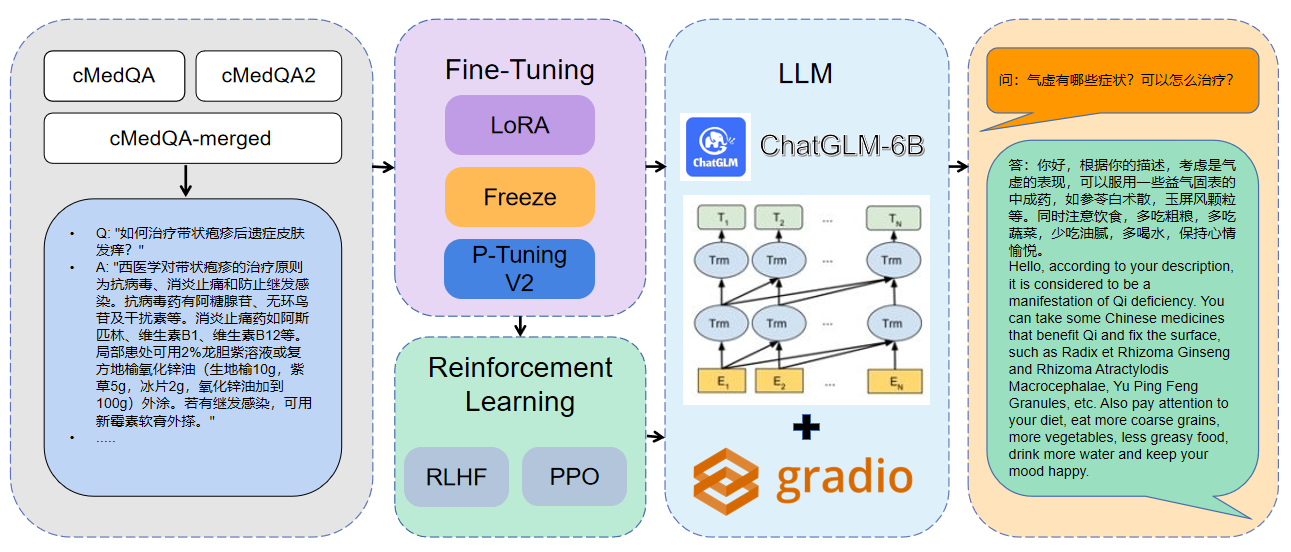
1 사용 된 데이터는 CMEDQA2입니다
| 프로젝트 | 데이터 세트 | 기본 모델 |
|---|---|---|
| 채팅 | Consame은 50W + 온라인 상담 + ChatGpt 답장, TCM 전통 중국 의약 진단 및 치료 데이터 세트가 게시되지 않았습니다. | llama-7b |
| chatdoctor | HealthCaremagic-100K에는 100K+ 실제 환자-의사-박터 대화 데이터 세트가 포함되어 있으며, ICLINIQ-10K에는 10K+ 환자 의사 대화 데이터 세트가 포함되어 있으며 GenmedGPT-5K에는 GPT에 의해 생성 된 5K+ 의사-환자 대화 데이터 세트가 포함됩니다. | llama-7b |
| Med-Chatglm | huatuo-data, huatuo-livers-ancancer | chatglm-6b |
| huatuo-llama-med-chinese | huatuo-data, huatuo-livers-ancancer | llama-7b |
| 닥터 GLM | Cmd., Meddialog, ChatDoctor 프로젝트 데이터 세트 | chatglm-6b |
| MedicalGpt-Zh | 오픈 소스가 아닙니다 | chatglm-6b |
| Dr.llama | 야마 | |
| Medical_nlp 2 | - | - |
| CMCQA 3 | - | - |
| Qizhengpt | - | - |
| LLM- 프리 트레인-결합 | - | - |
| PMC-Llama | - | llama-7b |
| 육계 | - | - |
| 메달 파카 | - | llama-7b |
| MedicalGpt | - | - |
| LLM- 프리 트레인-결합 | - | - |
| Shennong-TCM-LLM | - | - |
| Sunsimiao | - | - |
| CMLM-Zhongjing | - | - |
| Zhongjing | - | - |
| 밍 | - | - |
| DISC-MEDLLM | - | - |
pip install - r requirements . txt CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type lora
- - output_dir . / med - lora
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type freeze
- - output_dir . / med - freeze
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 1 python MedQA - ChatGLM / finetune . py
- - do_train - - dataset merged - cMedQA
- - finetuning_type p_tuning
- - output_dir . / med - p_tuning
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16더 많은 매개 변수 정보를 보려면 DOCS/PARAMETERS.MD에 대한 자세한 설명을 볼 수 있습니다.
멀티 GPU 분산 교육 :
# 配置分布式参数
accelerate config
# 分布式训练
accelerate launch src / finetune . py
- - do_train
- - dataset Huatuo , CMD , MedDialog , guanaco , cognition
- - finetuning_type lora
- - output_dir med - lora
- - per_device_train_batch_size 16
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 3.0
- - fp16
- - ddp_find_unused_parameters False # 分布式训练时,LoRA微调需要添加防止报错
- - plot_loss CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / web_demo . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / ) CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / infer . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / )모델 병합 :
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / export_weights . py
- - finetuning_weights_path . / med - lora
- - save_weights_path . / save_lora병합 된 모델로드 :
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / load_export_weights . py
- - save_weights_path . / save_lora| 미세 조정 방법 | 모델 무게 | 훈련 기간 | 훈련 라운드 |
|---|---|---|---|
| 로라 | Medqa-Chatglm-lora | 28h | 10 |
| p- 튜닝 v2 | MEDQA-Chatglm-ptuningv2 | 27h | 10 |
| 꼭 매달리게 하다 | Medqa-Chatglm-freeze | 28h | 10 |
* 실험은 Linux System, A100 (1x, 80GB)에서 수행되었습니다.
이 프로젝트와 관련된 자료는 학업 연구를위한 것이며 상업적 목적으로 엄격하게 금지되어 있습니다. 타사 코드와 관련된 부품을 사용하는 경우 해당 오픈 소스 프로토콜을 엄격히 따르십시오. 모델에 의해 생성 된 내용은 모델 계산, 임의성 및 정량적 정확도 손실과 같은 요소에 의해 영향을 받으며이 프로젝트는 정확도를 보장 할 수 없습니다. 이 프로젝트의 대부분의 데이터 세트는 모델에 의해 생성되며 특정 의료 사실을 준수하더라도 실제 의료 진단의 기초로 사용할 수 없습니다. 이 프로젝트는 모델의 컨텐츠 출력에 대한 법적 책임을지지 않으며 관련 리소스 및 출력 결과를 사용하여 발생할 수있는 손실에 대해 책임을지지 않습니다.


