MedQA ChatGLM
1.0.0
注記
最新の作品へようこそ:Carellama(Care Alpaca)は、医療LLMの急速な発展を促進するために、公開されている多数の医療用微調整データセットと公然と利用可能な医療大規模な言語モデルを組み合わせた医療大規模な言語モデルです。
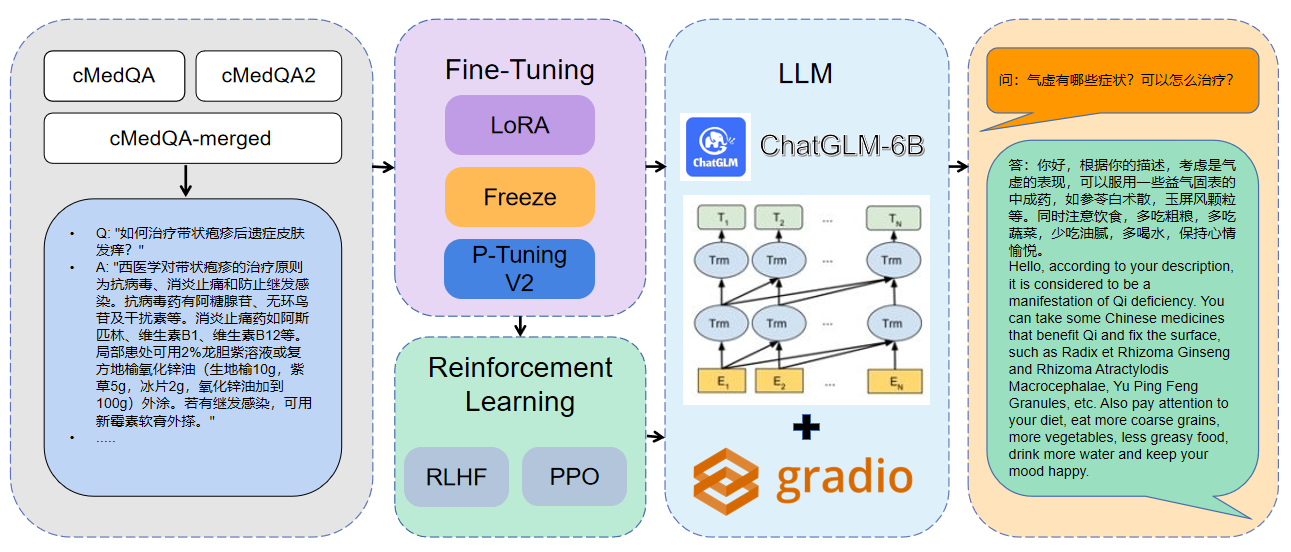
1使用されるデータはcmedqa2です
| プロジェクト | データセット | ベースモデル |
|---|---|---|
| チャットされた | 相談には50W +オンライン相談 + ChatGPT返信が含まれています、TCM従来の漢方薬の診断と治療データセットは公開されていません | llama-7b |
| チャットドクター | HealthcareMagic-100Kには100K+の実質患者ドクターダイアログデータセットが含まれています。ICLINIQ-10Kには10K+患者ドクターダイアログデータが含まれています。 | llama-7b |
| Med-chatglm | Huatuo-Data、Huatuo-LiverCancer | chatglm-6b |
| Huatuo-llama-med-chinese | Huatuo-Data、Huatuo-LiverCancer | llama-7b |
| Doctorglm | cmd。、meddialog、chatdoctorプロジェクトデータセット | chatglm-6b |
| MedicalGpt-Zh | データはオープンソースではありません | chatglm-6b |
| 博士 | ラマ | |
| Medical_nlp 2 | - | - |
| CMCQA 3 | - | - |
| Qizhengpt | - | - |
| LLM-Pretrain-Finetune | - | - |
| PMC-llama | - | llama-7b |
| ビアンケ | - | - |
| メダルパカ | - | llama-7b |
| MedicalGpt | - | - |
| LLM-Pretrain-Finetune | - | - |
| Shennong-tcm-llm | - | - |
| Sunsimiao | - | - |
| cmlm-zhongjing | - | - |
| Zhongjing | - | - |
| 明 | - | - |
| disc-medllm | - | - |
pip install - r requirements . txt CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type lora
- - output_dir . / med - lora
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type freeze
- - output_dir . / med - freeze
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 1 python MedQA - ChatGLM / finetune . py
- - do_train - - dataset merged - cMedQA
- - finetuning_type p_tuning
- - output_dir . / med - p_tuning
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16パラメーター情報の詳細については、docs/parameters.mdの詳細な説明を表示できます。
マルチGPU分散トレーニング:
# 配置分布式参数
accelerate config
# 分布式训练
accelerate launch src / finetune . py
- - do_train
- - dataset Huatuo , CMD , MedDialog , guanaco , cognition
- - finetuning_type lora
- - output_dir med - lora
- - per_device_train_batch_size 16
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 3.0
- - fp16
- - ddp_find_unused_parameters False # 分布式训练时,LoRA微调需要添加防止报错
- - plot_loss CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / web_demo . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / ) CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / infer . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / )モデルをマージします:
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / export_weights . py
- - finetuning_weights_path . / med - lora
- - save_weights_path . / save_loraマージされたモデルのロード:
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / load_export_weights . py
- - save_weights_path . / save_lora| 微調整方法 | モデルの重量 | トレーニング期間 | トレーニングラウンド |
|---|---|---|---|
| ロラ | Medqa-chatglm-lora | 28時間 | 10 |
| P調整V2 | Medqa-chatglm-ptuningv2 | 27H | 10 |
| フリーズ | Medqa-chatglm-freeze | 28時間 | 10 |
*実験はLinux System、A100(1x、80GB)で実施されました
このプロジェクトに関連するリソースは、学術研究のみであり、商業目的で厳密に禁止されています。サードパーティコードを含むパーツを使用する場合は、対応するオープンソースプロトコルに厳密に従ってください。モデルによって生成されるコンテンツは、モデルの計算、ランダム性、定量的精度損失などの要因の影響を受けます。このプロジェクトは、その精度を保証することはできません。このプロジェクトのデータセットのほとんどはモデルによって生成され、特定の医学的事実に準拠していても、実際の医療診断の基礎として使用することはできません。このプロジェクトは、モデルによるコンテンツ出力に対する法的責任を想定しておらず、関連するリソースと出力結果の使用から生じる可能性のある損失についても責任を負いません。


