MedQA ChatGLM
1.0.0
Catatan
Selamat datang di karya terbaru kami: Carellama (Care Alpaca), model bahasa medis besar yang menggabungkan lusinan set data penyesuaian medis yang tersedia untuk umum dan secara terbuka tersedia model bahasa medis besar untuk mempromosikan perkembangan cepat LLM Medis: https://github.com/wangrongsheng/carellama: https://github.com/wangrongsheng/carellama: https://github.com/wangrongsheng/carellama
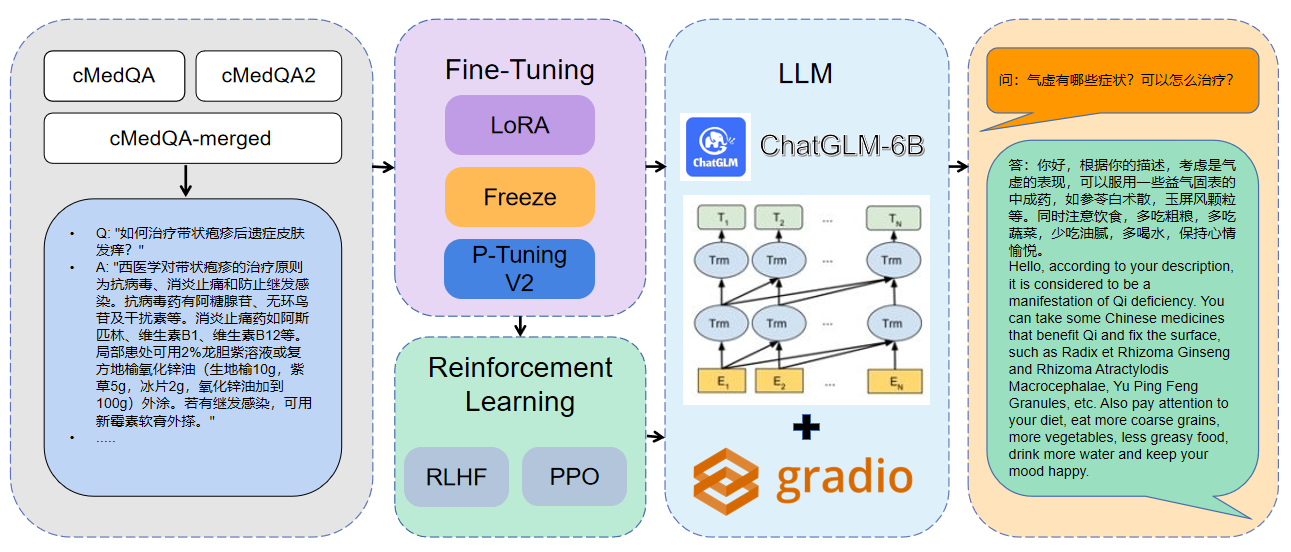
1 Data yang digunakan adalah cmedqa2
| proyek | Dataset | Model dasar |
|---|---|---|
| Chatmed | Konsultasikan berisi 50W + Konsultasi Online + Balas CHATGPT, TCM Tradition Chinese Medicine Diagnosis dan kumpulan data pengobatan belum dipublikasikan | Llama-7b |
| Chatdoctor | HealthCaremagic-100K berisi 100K+ Dataset Dialog Pasien-Doktor Nyata, ICLINIQ-10K berisi 10K+ Dataset Dialog Pasien-Doktor, GenMedGPT-5K berisi 5K+ Data Dialog Dokter-Pasien yang Dihasilkan oleh GPT | Llama-7b |
| Med-catglm | HUATUO-DATA, HUATUO-LIVER-CANCER | Chatglm-6b |
| HUatuo-Llama-Med-Chinese | HUATUO-DATA, HUATUO-LIVER-CANCER | Llama-7b |
| Dokterglm | Cmd., Meddialog, dataset proyek chatdoctor | Chatglm-6b |
| MedicalGpt-Zh | Data bukan sumber terbuka | Chatglm-6b |
| Dr.llama | Llama | |
| Medical_nlp 2 | - | - |
| CMCQA 3 | - | - |
| Qizhengpt | - | - |
| Llm-pretrain-finetune | - | - |
| PMC-llama | - | Llama-7b |
| Bianque | - | - |
| Medalpaca | - | Llama-7b |
| MedicalGpt | - | - |
| Llm-pretrain-finetune | - | - |
| Shennong-tcm-llm | - | - |
| Sunsimiao | - | - |
| CMLM-ZHONGJING | - | - |
| Zhongjing | - | - |
| Ming | - | - |
| DISC-MEDLLM | - | - |
pip install - r requirements . txt CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type lora
- - output_dir . / med - lora
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type freeze
- - output_dir . / med - freeze
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 1 python MedQA - ChatGLM / finetune . py
- - do_train - - dataset merged - cMedQA
- - finetuning_type p_tuning
- - output_dir . / med - p_tuning
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16Untuk informasi parameter lebih lanjut, Anda dapat melihat penjelasan terperinci dari dokumen/parameter.md.
Pelatihan Terdistribusi Multi-GPU:
# 配置分布式参数
accelerate config
# 分布式训练
accelerate launch src / finetune . py
- - do_train
- - dataset Huatuo , CMD , MedDialog , guanaco , cognition
- - finetuning_type lora
- - output_dir med - lora
- - per_device_train_batch_size 16
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 3.0
- - fp16
- - ddp_find_unused_parameters False # 分布式训练时,LoRA微调需要添加防止报错
- - plot_loss CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / web_demo . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / ) CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / infer . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / )Gabungkan model:
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / export_weights . py
- - finetuning_weights_path . / med - lora
- - save_weights_path . / save_loraMemuat model gabungan:
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / load_export_weights . py
- - save_weights_path . / save_lora| Metode penyempurnaan | Berat model | Durasi pelatihan | Putaran pelatihan |
|---|---|---|---|
| Lora | Medqa-catglm-lora | 28h | 10 |
| P-tuning v2 | Medqa-catglm-ptuningv2 | 27h | 10 |
| Membekukan | Medqa-chatglm-freeze | 28h | 10 |
* Percobaan dilakukan pada sistem Linux, A100 (1x, 80GB)
Sumber daya yang terkait dengan proyek ini hanya untuk penelitian akademik dan dilarang ketat untuk tujuan komersial. Saat menggunakan bagian yang melibatkan kode pihak ketiga, silakan ikuti protokol open source yang sesuai. Konten yang dihasilkan oleh model dipengaruhi oleh faktor -faktor seperti perhitungan model, keacakan dan kerugian akurasi kuantitatif, dan proyek ini tidak dapat menjamin keakuratannya. Sebagian besar set data dari proyek ini dihasilkan oleh model dan tidak dapat digunakan sebagai dasar untuk diagnosis medis yang sebenarnya bahkan jika mereka mematuhi fakta medis tertentu. Proyek ini mengasumsikan tidak ada kewajiban hukum untuk setiap output konten oleh model, juga tidak bertanggung jawab atas kerugian yang mungkin timbul dari penggunaan sumber daya yang relevan dan hasil output.


