MedQA ChatGLM
1.0.0
Nota
Bienvenido a nuestro último trabajo: Carellama (Care Alpaca), un modelo de lenguaje grande médico que combina docenas de conjuntos de datos médicos de ajuste médico disponibles públicamente y modelos de lenguaje médico médico abiertamente disponible para promover el rápido desarrollo de Medical LLM: https://github.com/wangrongsheng/carellama
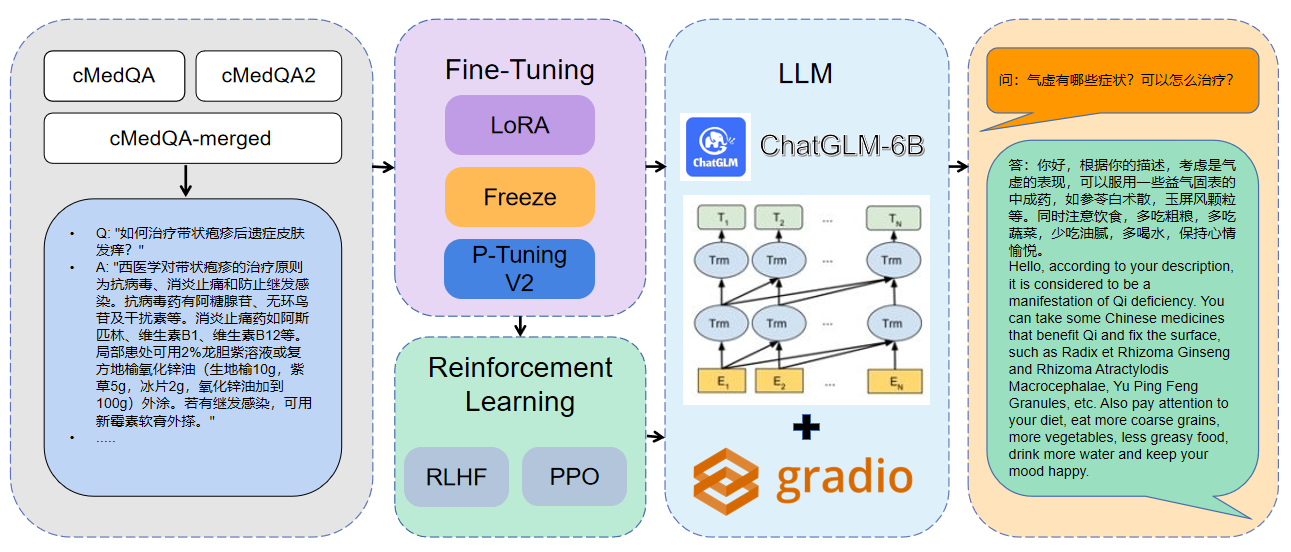
1 Los datos utilizados son CMEDQA2
| proyecto | Conjunto de datos | Modelo base |
|---|---|---|
| Chated | Consultar contiene 50W + consulta en línea + respuesta de chatgpt, no se ha publicado un conjunto de datos de diagnóstico y tratamiento de medicina tradicional de TCM. | Llama-7b |
| Chatdoctor | HealthCaremagic-100k contiene 100k+ conjunto de datos de diálogo de pacientes con el paciente real, ICLINIQ-10K contiene 10k+ conjunto de datos de diálogo-doctor de paciente, GenMedgpt-5K contiene un conjunto de datos de diálogo para el médico de 5K+ generado por GPT generado por GPT | Llama-7b |
| Med-Chatglm | Huatuo-Data, Huatuo-Liver-Cancer | Chatglm-6b |
| Huatuo-llama-Med-chines | Huatuo-Data, Huatuo-Liver-Cancer | Llama-7b |
| Doctorglm | CMD., Meddialog, conjunto de datos del proyecto ChatDoctor | Chatglm-6b |
| Medicalgpt-zh | Datos no de código abierto | Chatglm-6b |
| Dr.lama | Llama | |
| Medical_NLP 2 | - | - |
| CMCQA 3 | - | - |
| Qizhengpt | - | - |
| Llm-pretrain-finetune | - | - |
| PMC-LLAMA | - | Llama-7b |
| Bianque | - | - |
| medallpaca | - | Llama-7b |
| Médico | - | - |
| Llm-pretrain-finetune | - | - |
| Shennong-tcm-llm | - | - |
| Sunsimiao | - | - |
| Cmlm-zhongjing | - | - |
| Zhongjing | - | - |
| Ming | - | - |
| Disco-Medllm | - | - |
pip install - r requirements . txt CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type lora
- - output_dir . / med - lora
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / finetune . py
- - do_train
- - dataset merged - cMedQA
- - finetuning_type freeze
- - output_dir . / med - freeze
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16 CUDA_VISIBLE_DEVICES = 1 python MedQA - ChatGLM / finetune . py
- - do_train - - dataset merged - cMedQA
- - finetuning_type p_tuning
- - output_dir . / med - p_tuning
- - per_device_train_batch_size 32
- - gradient_accumulation_steps 256
- - lr_scheduler_type cosine
- - logging_steps 500
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 10.0
- - fp16Para obtener más información de parámetros, puede ver la explicación detallada de docs/parámetros.md.
Capacitación distribuida multi-GPU:
# 配置分布式参数
accelerate config
# 分布式训练
accelerate launch src / finetune . py
- - do_train
- - dataset Huatuo , CMD , MedDialog , guanaco , cognition
- - finetuning_type lora
- - output_dir med - lora
- - per_device_train_batch_size 16
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 3.0
- - fp16
- - ddp_find_unused_parameters False # 分布式训练时,LoRA微调需要添加防止报错
- - plot_loss CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / web_demo . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / ) CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / infer . py
- - checkpoint_dir med - lora /
( med - freez / )
( med - p_tuning / )Fusionar el modelo:
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / export_weights . py
- - finetuning_weights_path . / med - lora
- - save_weights_path . / save_loraCargando el modelo fusionado:
CUDA_VISIBLE_DEVICES = 0 python MedQA - ChatGLM / load_export_weights . py
- - save_weights_path . / save_lora| Método de ajuste | Peso modelo | Duración del entrenamiento | Rondas de entrenamiento |
|---|---|---|---|
| Lora | Medqa-chatglm-lora | 28h | 10 |
| P-ajuste V2 | Medqa-chatglm-ptuningv2 | 27h | 10 |
| Congelar | Medqa-chatglm-congelle | 28h | 10 |
* El experimento se realizó en el sistema Linux, A100 (1x, 80 GB)
Los recursos relacionados con este proyecto son solo para la investigación académica y están estrictamente prohibidas para fines comerciales. Al usar piezas que involucran código de terceros, siga estrictamente el protocolo de código abierto correspondiente. El contenido generado por el modelo se ve afectado por factores como el cálculo del modelo, la aleatoriedad y las pérdidas cuantitativas de precisión, y este proyecto no puede garantizar su precisión. La mayoría de los conjuntos de datos de este proyecto son generados por modelos y no pueden usarse como base para el diagnóstico médico real, incluso si cumplen con ciertos hechos médicos. Este proyecto no asume ninguna responsabilidad legal por la producción de contenido por parte del modelo, ni es responsable de las pérdidas que puedan surgir del uso de recursos relevantes y resultados de salida.


