LongLoRA
1.0.0
LONGLORA:長篇文章大語模型的有效微調[紙]
Yukang Chen,Shengju Qian,Haotian Tang,Xin Lai,Zhijian Liu,Song Han,Jiaya Jia
Requirements和Installation and Quick Guide部分。要下載並使用您需要的預先訓練的權重:
安裝並運行應用程序:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
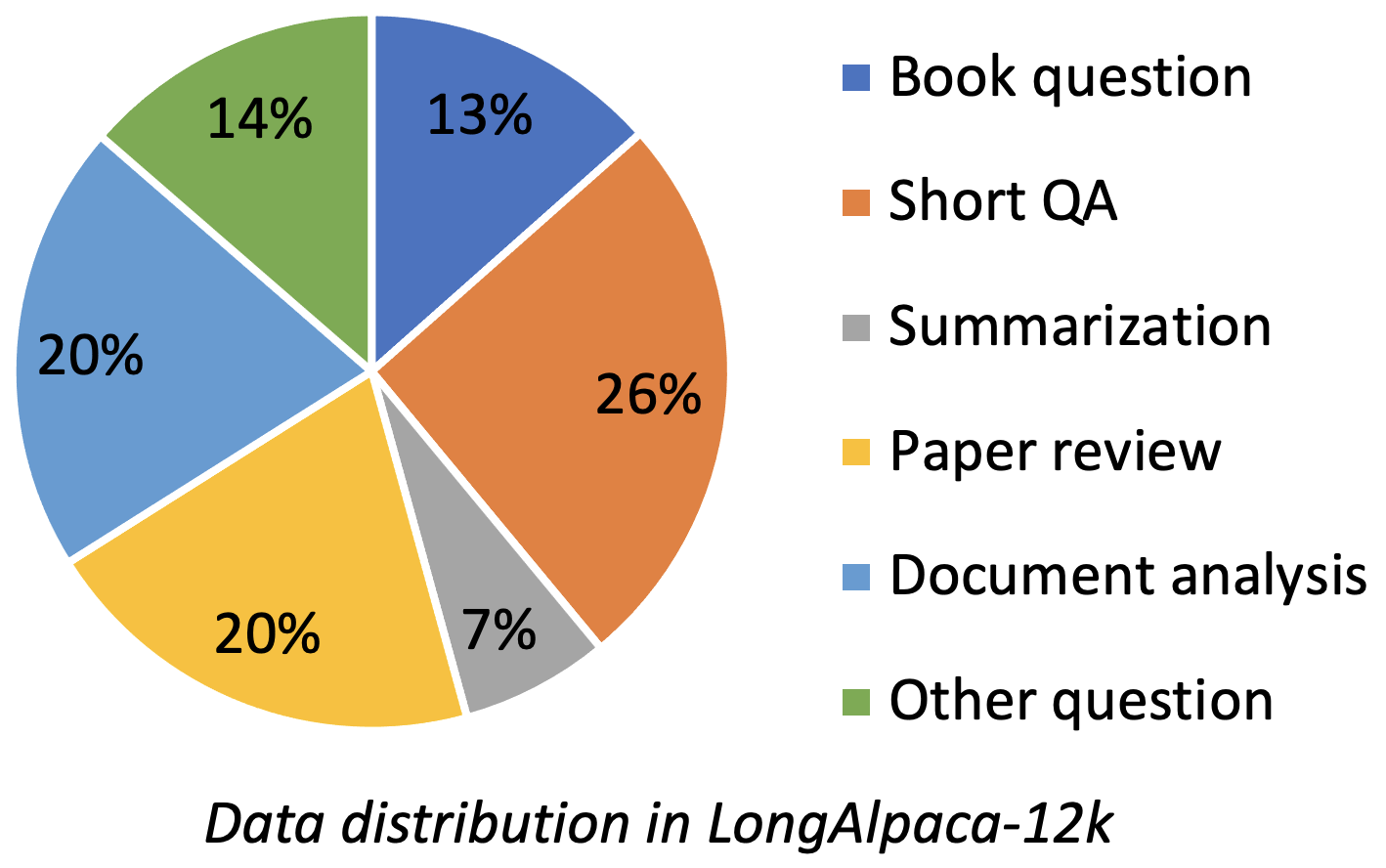
Longalpaca-12k包含我們收集的9K長QA數據,並從原始羊駝數據中採樣了3K簡短的QA。這是為了避免模型在以下簡短指令中降級的情況。我們收集的數據包含各種類型和數量,如下圖。
| 數據 | 簡短的質量檢查 | 長質量檢查 | 全部的 | 下載 |
|---|---|---|---|---|
| longalpaca-12k | 3k | 9k | 12k | 關聯 |
遵循原始的羊駝格式,我們的長質量檢查數據使用以下提示進行微調:
instruction : str ,描述模型應執行的任務。例如,閱讀書本或論文後回答問題。我們改變了內容和問題,以使指示多樣化。output : str ,指令的答案。為簡單起見,我們沒有使用羊駝格式的input格式。
| 模型 | 尺寸 | 情境 | 火車 | 關聯 |
|---|---|---|---|---|
| longalpaca-7b | 7b | 32768 | 全英尺 | 模型 |
| longalpaca-13b | 13b | 32768 | 全英尺 | 模型 |
| longalpaca-70b | 70B | 32768 | 洛拉+ | 模型(洛拉 - 重量) |
| 模型 | 尺寸 | 情境 | 火車 | 關聯 |
|---|---|---|---|---|
| Llama-2-7b-Longlora-8K-ft | 7b | 8192 | 全英尺 | 模型 |
| Llama-2-7b-Longlora-16k-ft | 7b | 16384 | 全英尺 | 模型 |
| Llama-2-7b-Longlora-32k-ft | 7b | 32768 | 全英尺 | 模型 |
| Llama-2-7b-Longlora-100k-ft | 7b | 100000 | 全英尺 | 模型 |
| Llama-2-13b-Longlora-8K-ft | 13b | 8192 | 全英尺 | 模型 |
| Llama-2-13b-Longlora-16k-ft | 13b | 16384 | 全英尺 | 模型 |
| Llama-2-13b-Longlora-32k-ft | 13b | 32768 | 全英尺 | 模型 |
| 模型 | 尺寸 | 情境 | 火車 | 關聯 |
|---|---|---|---|---|
| Llama-2-7b-Longlora-8K | 7b | 8192 | 洛拉+ | 洛拉重量 |
| Llama-2-7b-Longlora-16k | 7b | 16384 | 洛拉+ | 洛拉重量 |
| Llama-2-7b-Longlora-32k | 7b | 32768 | 洛拉+ | 洛拉重量 |
| Llama-2-13b-Longlora-8K | 13b | 8192 | 洛拉+ | 洛拉重量 |
| Llama-2-13b-Longlora-16k | 13b | 16384 | 洛拉+ | 洛拉重量 |
| Llama-2-13b-Longlora-32k | 13b | 32768 | 洛拉+ | 洛拉重量 |
| Llama-2-13b-Longlora-64k | 13b | 65536 | 洛拉+ | 洛拉重量 |
| Llama-2-70b-Longlora-32k | 70B | 32768 | 洛拉+ | 洛拉重量 |
| Llama-2-70B-Chat-Longlora-32k | 70B | 32768 | 洛拉+ | 洛拉重量 |
我們使用Llama2模型作為預先訓練的權重,然後將它們微調為長上下文窗口尺寸。根據您的選擇下載。
| 預訓練的重量 |
|---|
| Llama-2-7b-hf |
| Llama-2-13b-hf |
| Llama-2-70b-hf |
| Llama-2-7b-chat-hf |
| Llama-2-13b-chat-hf |
| Llama-2-70B-Chat-HF |
該項目還支持GPTNEOX模型作為基本模型體系結構。一些候選預訓練的權重可能包括GPT-Neox-20b,Polyglot-KO-122.8B和其他變體。
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf更改為path_to_saving_checkpoints , path_to_cache到您自己的目錄。model_max_length更改為其他值。ds_configs/stage2.json更改為ds_configs/stage3.json 。use_flash_attn設置為False 。low_rank_training設置為False 。它將花費更多的GPU內存和較慢的成本,但是性能會好一些。 cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
請注意,path_to_saving_checkpoints可能是Global_Step Directory,該目錄取決於DeepSpeed版本。
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
在低級訓練中,我們將嵌入和歸一化層設置為可訓練。請使用以下行從pytorch_model.bin提取可訓練的權重trainable_params.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
合併pytorch_model.bin和可訓練的參數trainable_params.bin的lora重量
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
例如,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
要評估在低級別設置中訓練的模型,請同時設置base_model和peft_model 。 base_model是預訓練的重量。 peft_model是保存檢查點的路徑,該路徑應包含trainable_params.bin , adapter_model.bin和adapter_config.json 。例如,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
或使用多個GPU進行評估如下。
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
要評估完全微調的模型,您只需要將base_model設置為已保存檢查點的路徑,該路徑應包含pytorch_model.bin和config.json 。 peft_model應忽略。
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
或使用多個GPU進行評估如下。
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
請注意, --seq_len將設置序列長度以進行評估。 --context_size是在微調過程中設置模型的上下文長度。 --seq_len不應大於--context_size 。
我們已經將PG19和PROCK-PILE數據集的驗證和測試拆分標記為pg19/validation.bin , pg19/test.bin proof-pile/test_sampled_data.bin以及llama的標記器。 proof-pile/test_sampled_data.bin包含128個文檔,這些文檔是從總驗證測試拆分中隨機採樣的。對於每個文檔,它至少具有32768個令牌。我們還將在profile-pile/test_sampled_ids.s.bin中釋放採樣ID。您可以從下面的鏈接下載它們。
| 數據集 | 分裂 | 關聯 |
|---|---|---|
| PG19 | 驗證 | PG19/驗證 |
| PG19 | 測試 | PG19/test.bin |
| 驗證 | 測試 | PROCE-PILE/TEST_SAMPLED_DATA.BIN |
我們提供了測試Passkey檢索準確性的方式。例如,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size _size是微調過程中的上下文長度。max_tokens是Passkey檢索評估中該文檔的最大長度。interval是文檔長度增加期間的間隔。這是一個粗略的數字,因為文檔通過句子增加。 與Longalpaca型號聊天,
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
問一個與書有關的問題:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
問一個與論文有關的問題:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
部署自己的演示運行
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
例子
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True將使生成緩慢,但節省了很多GPU內存。 我們支持使用Streamlingllm的Longalpaca模型的推斷。這增加了Streamingllm中多輪對話的上下文長度。這是一個例子,
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath是包含推理提示的JSON文件。我們提供了一個示例文件outputs_stream.json,該文件是longalpaca-12k的子集。您可以將其替換為自己的問題。 在我們的數據集集合中,我們將紙張和書籍從PDF轉換為文本。轉換質量對最終模型質量有很大影響。我們認為這一步是不平凡的。我們在文件夾pdf2txt中發布了PDF2TXT轉換的工具。它建立在pdf2image , easyocr , ditod和detectron2上。有關更多詳細信息,請參閱pdf2txt中的readme.md。







如果您發現此項目在您的研究中有用,請考慮引用:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


