LongLoRA
1.0.0
Longlora: Fine-tuning yang efisien dari model bahasa besar konteks panjang [kertas]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
Requirements dan Installation and Quick Guide di bawah ini.Untuk mengunduh dan menggunakan bobot terlatih yang Anda perlukan:
Untuk menginstal dan menjalankan aplikasi:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
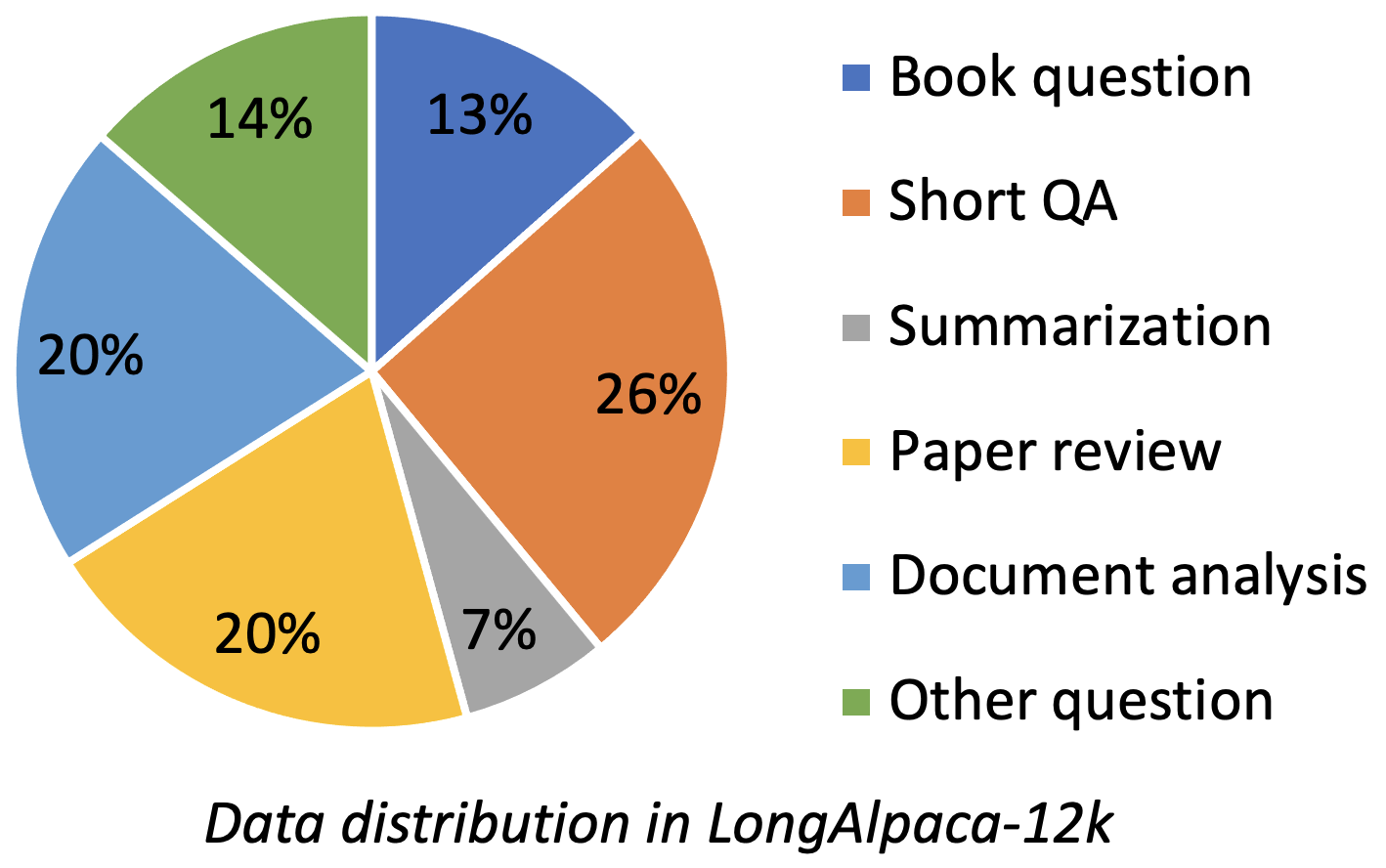
Longalpaca-12K berisi data QA panjang 9k yang kami kumpulkan dan 3K QA pendek sampel dari data alpaca asli. Ini untuk menghindari kasus bahwa model mungkin terdegradasi pada pengajaran singkat berikut. Data yang kami kumpulkan berisi berbagai jenis dan jumlah sebagai gambar berikut.
| Data | QA pendek | QA panjang | Total | Unduh |
|---|---|---|---|---|
| Longalpaca-12k | 3K | 9k | 12k | Link |
Mengikuti format alpaca asli, data QA panjang kami menggunakan petunjuk berikut untuk menyempurnakan:
instruction : str , menjelaskan tugas yang harus dilakukan model. Misalnya, untuk menjawab pertanyaan setelah membaca bagian atau kertas buku. Kami memvariasikan konten dan pertanyaan untuk membuat instruksi beragam.output : str , jawaban untuk instruksi. Kami tidak menggunakan format input dalam format ALPACA untuk kesederhanaan.
| Model | Ukuran | Konteks | Kereta | Link |
|---|---|---|---|---|
| Longalpaca-7b | 7b | 32768 | Ft penuh | Model |
| Longalpaca-13b | 13b | 32768 | Ft penuh | Model |
| Longalpaca-70b | 70b | 32768 | Lora+ | Model (lora-weight) |
| Model | Ukuran | Konteks | Kereta | Link |
|---|---|---|---|---|
| Llama-2-7b-longlora-8k-ft | 7b | 8192 | Ft penuh | Model |
| Llama-2-7b-longlora-16k-ft | 7b | 16384 | Ft penuh | Model |
| Llama-2-7b-longlora-32k-ft | 7b | 32768 | Ft penuh | Model |
| Llama-2-7b-longlora-100k-ft | 7b | 100000 | Ft penuh | Model |
| Llama-2-13b-longlora-8k-ft | 13b | 8192 | Ft penuh | Model |
| Llama-2-13b-longlora-16k-ft | 13b | 16384 | Ft penuh | Model |
| Llama-2-13b-longlora-32k-ft | 13b | 32768 | Ft penuh | Model |
| Model | Ukuran | Konteks | Kereta | Link |
|---|---|---|---|---|
| Llama-2-7b-longlora-8k | 7b | 8192 | Lora+ | Lora-weight |
| Llama-2-7b-longlora-16k | 7b | 16384 | Lora+ | Lora-weight |
| Llama-2-7B-Longlora-32K | 7b | 32768 | Lora+ | Lora-weight |
| Llama-2-13b-longlora-8k | 13b | 8192 | Lora+ | Lora-weight |
| Llama-2-13b-longlora-16k | 13b | 16384 | Lora+ | Lora-weight |
| Llama-2-13b-longlora-32k | 13b | 32768 | Lora+ | Lora-weight |
| Llama-2-13b-longlora-64k | 13b | 65536 | Lora+ | Lora-weight |
| LLAMA-2-70B-Longlora-32K | 70b | 32768 | Lora+ | Lora-weight |
| LLAMA-2-70B-CHAT-Longlora-32K | 70b | 32768 | Lora+ | Lora-weight |
Kami menggunakan model LLAMA2 sebagai bobot pra-terlatih dan menyempurnakannya untuk ukuran jendela konteks yang panjang. Unduh berdasarkan pilihan Anda.
| Bobot pra-terlatih |
|---|
| Llama-2-7b-hf |
| Llama-2-13b-hf |
| Llama-2-70b-hf |
| LLAMA-2-7B-CHAT-HF |
| LLAMA-2-13B-CHAT-HF |
| LLAMA-2-70B-CHAT-HF |
Proyek ini juga mendukung model GPTNEOX sebagai arsitektur model dasar. Beberapa kandidat bobot pra-terlatih mungkin termasuk GPT-NEOX-20B, Polyglot-KO-12.8B dan varian lainnya.
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf , path_to_saving_checkpoints , path_to_cache ke direktori Anda sendiri.model_max_length ke nilai lain.ds_configs/stage2.json ke ds_configs/stage3.json jika Anda mau.use_flash_attn sebagai False jika Anda menggunakan mesin V100 atau tidak menginstal perhatian flash.low_rank_training sebagai False jika Anda ingin menggunakan fine-tuning sepenuhnya. Ini akan membutuhkan lebih banyak memori GPU dan lebih lambat, tetapi kinerjanya akan sedikit lebih baik. cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
Perhatikan bahwa PATT_TO_SAVING_CHECKPOINTS mungkin adalah direktori Global_Step, yang tergantung pada versi Deepspeed.
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
Dalam pelatihan peringkat rendah, kami menetapkan lapisan embedding dan normalisasi sebagai dapat dilatih. Silakan gunakan baris berikut untuk mengekstrak bobot yang dapat dilatih yang trainable_params.bin dari pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
Gabungkan bobot lora dari pytorch_model.bin dan parameter yang dapat dilatih trainable_params.bin , simpan model yang dihasilkan ke jalur yang Anda inginkan dalam format wajah pelukan:
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
Misalnya,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
Untuk mengevaluasi model yang dilatih dalam pengaturan peringkat rendah, silakan atur base_model dan peft_model . base_model adalah berat pra-terlatih. peft_model adalah jalur ke pos pemeriksaan yang disimpan, yang seharusnya berisi trainable_params.bin , adapter_model.bin dan adapter_config.json . Misalnya,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Atau evaluasi dengan beberapa GPU sebagai berikut.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Untuk mengevaluasi model yang sepenuhnya disesuaikan, Anda hanya perlu mengatur base_model sebagai jalur ke pos pemeriksaan yang disimpan, yang seharusnya berisi pytorch_model.bin dan config.json . peft_model harus diabaikan.
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Atau evaluasi dengan beberapa GPU sebagai berikut.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Perhatikan bahwa --seq_len adalah untuk mengatur panjang urutan untuk evaluasi. --context_size adalah untuk mengatur panjang konteks model selama penyempurnaan. --seq_len seharusnya tidak lebih besar dari --context_size .
Kami telah mengubah validasi dan pemisahan tes pg19 dan dataset bukti-pile menjadi pg19/validation.bin , pg19/test.bin , dan proof-pile/test_sampled_data.bin , dengan tokenizer llama. proof-pile/test_sampled_data.bin berisi 128 dokumen yang diambil secara acak dari split uji Total Proof-Pile. Untuk setiap dokumen, ia memiliki setidaknya 32768 token. Kami juga merilis ID sampel dalam proof-pile/test_sampled_ids.bin. Anda dapat mengunduhnya dari tautan di bawah ini.
| Dataset | Membelah | Link |
|---|---|---|
| Pg19 | validasi | pg19/validasi.bin |
| Pg19 | tes | pg19/test.bin |
| Bukti-bajingan | tes | Bukti-pile/test_sampled_data.bin |
Kami memberikan cara untuk menguji akurasi pengambilan passkey. Misalnya,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size adalah panjang konteks selama penyetelan.max_tokens adalah panjang maksimum untuk dokumen dalam evaluasi pengambilan passkey.interval adalah interval selama panjang dokumen meningkat. Ini adalah angka yang kasar karena dokumen meningkat berdasarkan kalimat. Untuk mengobrol dengan model longalpaca,
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
Untuk mengajukan pertanyaan terkait buku:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
Untuk mengajukan pertanyaan yang terkait dengan makalah:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
Untuk menggunakan demo Anda sendiri
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
Contoh
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True akan membuat generasi lambat tetapi menyimpan banyak memori GPU. Kami mendukung inferensi model Longalpaca dengan streamingllm. Ini meningkatkan panjang konteks dari dialog multi-putaran dalam streamingllm. Inilah contohnya,
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath adalah file JSON yang berisi permintaan untuk inferensi. Kami memberikan contoh file outputs_stream.json, yang merupakan subset dari longalpaca-12k. Anda dapat menggantinya ke pertanyaan Anda sendiri. Selama koleksi dataset kami, kami mengonversi kertas dan buku dari PDF ke teks. Kualitas konversi memiliki pengaruh besar pada kualitas model akhir. Kami berpikir bahwa langkah ini tidak sepele. Kami melepaskan alat untuk konversi PDF2TXT, di folder pdf2txt . Ini dibangun di atas pdf2image , easyocr , ditod dan detectron2 . Silakan merujuk ke readme.md di pdf2txt untuk lebih jelasnya.







Jika Anda menemukan proyek ini berguna dalam penelitian Anda, silakan pertimbangkan mengutip:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


