LongLoRA
1.0.0
longlora : 장기 텍스트 대형 언어 모델의 효율적인 미세 조정 [종이]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
Requirements 및 Installation and Quick Guide 섹션을 모두 읽으십시오.필요한 미리 훈련 된 무게를 다운로드하고 사용하려면 다음과 같습니다.
응용 프로그램을 설치하고 실행하려면 :
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
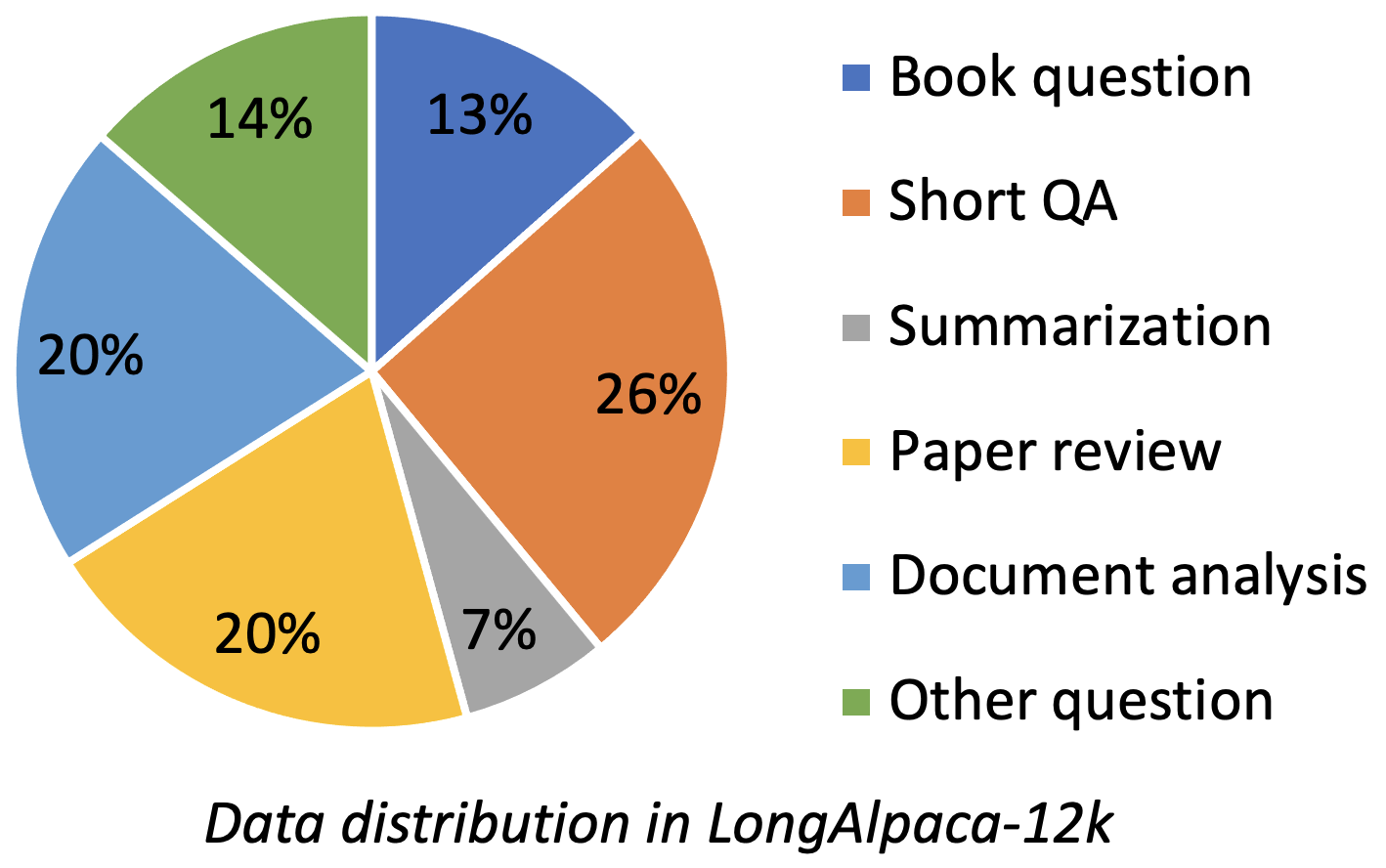
Longalpaca-12k에는 우리가 수집 한 9k 길이의 QA 데이터가 포함되어 있으며 원래 Alpaca 데이터에서 3K 짧은 QA 샘플링. 이는 모델이 다음에 간단한 명령으로 저하 될 수있는 경우를 피하기위한 것입니다. 우리가 수집하는 데이터에는 다음과 같은 다양한 유형과 금액이 포함되어 있습니다.
| 데이터 | 짧은 QA | 긴 QA | 총 | 다운로드 |
|---|---|---|---|---|
| longalpaca-12k | 3K | 9k | 12k | 링크 |
원래 Alpaca 형식에 따라 긴 QA 데이터는 미세 조정을위한 다음과 같은 프롬프트를 사용합니다.
instruction : str , 모델이 수행 해야하는 작업을 설명합니다. 예를 들어, 책 섹션이나 종이를 읽은 후 질문에 답하십시오. 우리는 지시 사항을 다양한 내용과 질문을 다양하게합니다.output : str , 지시에 대한 답. 단순성을 위해 Alpaca 형식의 input 형식을 사용하지 않았습니다.
| 모델 | 크기 | 문맥 | 기차 | 링크 |
|---|---|---|---|---|
| longalpaca-7b | 7b | 32768 | 전체 ft | 모델 |
| longalpaca-13b | 13b | 32768 | 전체 ft | 모델 |
| longalpaca-70b | 70b | 32768 | 로라+ | 모델 (Lora-weight) |
| 모델 | 크기 | 문맥 | 기차 | 링크 |
|---|---|---|---|---|
| llama-2-7b-longlora-8k-ft | 7b | 8192 | 전체 ft | 모델 |
| llama-2-7b-longlora-16k-ft | 7b | 16384 | 전체 ft | 모델 |
| llama-2-7b-longlora-32k-ft | 7b | 32768 | 전체 ft | 모델 |
| llama-2-7b-longlora-100k-ft | 7b | 100000 | 전체 ft | 모델 |
| llama-2-13b-longlora-8k-ft | 13b | 8192 | 전체 ft | 모델 |
| llama-2-13b-longlora-16k-ft | 13b | 16384 | 전체 ft | 모델 |
| llama-2-13b-longlora-32k-ft | 13b | 32768 | 전체 ft | 모델 |
| 모델 | 크기 | 문맥 | 기차 | 링크 |
|---|---|---|---|---|
| llama-2-7b-longlora-8k | 7b | 8192 | 로라+ | 로라-가이트 |
| llama-2-7b-longlora-16k | 7b | 16384 | 로라+ | 로라-가이트 |
| llama-2-7b-longlora-32k | 7b | 32768 | 로라+ | 로라-가이트 |
| llama-2-13b-longlora-8k | 13b | 8192 | 로라+ | 로라-가이트 |
| llama-2-13b-longlora-16k | 13b | 16384 | 로라+ | 로라-가이트 |
| llama-2-13b-longlora-32k | 13b | 32768 | 로라+ | 로라-가이트 |
| llama-2-13b-longlora-64k | 13b | 65536 | 로라+ | 로라-가이트 |
| llama-2-70b-longlora-32k | 70b | 32768 | 로라+ | 로라-가이트 |
| LLAMA-2-70B-Chat-Longlora-32K | 70b | 32768 | 로라+ | 로라-가이트 |
우리는 LLAMA2 모델을 미리 훈련 된 가중치로 사용하여 긴 컨텍스트 창 크기로 미세 조정합니다. 선택에 따라 다운로드하십시오.
| 미리 훈련 된 무게 |
|---|
| LLAMA-2-7B-HF |
| LLAMA-2-13B-HF |
| LLAMA-2-70B-HF |
| LLAMA-2-7B-Chat-HF |
| LLAMA-2-13B-Chat-HF |
| LLAMA-2-70B-Chat-HF |
이 프로젝트는 또한 기본 모델 아키텍처로서 gptneox 모델을 지원합니다. 일부 후보 사전 훈련 된 중량에는 GPT-NEOX-20B, Polyglot-KO-12.8B 및 기타 변이체가 포함될 수 있습니다.
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf , path_to_saving_checkpoints , path_to_cache 자신의 디렉토리로 변경하십시오.model_max_length 다른 값으로 변경할 수 있습니다.ds_configs/stage2.json ds_configs/stage3.json 으로 변경할 수 있습니다.use_flash_attn False 로 설정하십시오.low_rank_training False 로 설정할 수 있습니다. 더 많은 GPU 메모리가 비용이 많이 들고 느리게하지만 성능은 조금 더 나을 것입니다. cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
PATH_TO_SAVING_CHECKPOINST는 딥 스피드 버전에 따라 Global_Step 디렉토리 일 수 있습니다.
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
낮은 순위 교육에서 우리는 임베딩 및 정규화 층을 훈련 가능한 것으로 설정했습니다. 다음 줄을 사용하여 Trainable weights trainable_params.bin 에서 pytorch_model.bin 에서 추출하십시오.
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
pytorch_model.bin 의 lora weights and trainable 매개 변수 trainable_params.bin 병합하고, 결과 모델을 원하는 경로로 저장하십시오.
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
예를 들어,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
낮은 순위 설정에서 훈련 된 모델을 평가하려면 base_model 과 peft_model 모두 설정하십시오. base_model 미리 훈련 된 중량입니다. peft_model 저장된 체크 포인트의 경로로, trainable_params.bin , adapter_model.bin 및 adapter_config.json 포함해야합니다. 예를 들어,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
또는 다음과 같이 여러 GPU로 평가하십시오.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
완전히 미세 조정 된 모델을 평가하려면 base_model 저장된 체크 포인트의 경로로 만 설정하면 pytorch_model.bin 및 config.json 포함되어야합니다. peft_model 무시해야합니다.
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
또는 다음과 같이 여러 GPU로 평가하십시오.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
--seq_len 은 평가를 위해 시퀀스 길이를 설정하는 것입니다. --context_size 미세 조정 중에 모델의 컨텍스트 길이를 설정하는 것입니다. --seq_len --context_size 보다 크지 않아야합니다.
우리는 이미 PG19 및 Proof-Pile DataSet의 유효성 검사 및 테스트 분할을 pg19/validation.bin , pg19/test.bin 및 proof-pile/test_sampled_data.bin 으로 Tokenizer와 함께 토큰 화했습니다. proof-pile/test_sampled_data.bin 에는 총 증명 파일 테스트 분할에서 무작위로 샘플링되는 128 개의 문서가 포함되어 있습니다. 각 문서마다 32768 개의 토큰이 있습니다. 또한 Proof-Pile/Test_sampled_ids.bin에서 샘플링 된 ID를 해제합니다. 아래 링크에서 다운로드 할 수 있습니다.
| 데이터 세트 | 나뉘다 | 링크 |
|---|---|---|
| PG19 | 확인 | pg19/validation.bin |
| PG19 | 시험 | pg19/test.bin |
| 증명서 | 시험 | 교정-파일/test_sampled_data.bin |
패스 키 검색 정확도를 테스트하는 방법을 제공합니다. 예를 들어,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size 는 미세 조정 중 컨텍스트 길이입니다.max_tokens Passkey 검색 평가에서 문서의 최대 길이입니다.interval 문서 길이가 증가하는 동안의 간격입니다. 문서가 문장별로 증가하기 때문에 거친 숫자입니다. Longalpaca 모델과 채팅하려면
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
책과 관련된 질문을하려면 :
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
논문과 관련된 질문을하려면 :
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
자신의 데모 실행을 배포합니다
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
예
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True 는 생성을 느리게 만들지 만 많은 GPU 메모리를 저장합니다. 우리는 Streamingllm으로 Longalpaca 모델의 추론을 지원합니다. 이것은 Streamingllm에서 다중 라운드 대화의 컨텍스트 길이를 증가시킵니다. 다음은 예입니다.
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath 추론 프롬프트가 포함 된 JSON 파일입니다. Longalpaca-12K의 하위 집합 인 Prite Outputs_stream.json 예제를 제공합니다. 자신의 질문으로 교체 할 수 있습니다. 데이터 세트 컬렉션 중에 종이와 책을 PDF에서 텍스트로 변환합니다. 변환 품질은 최종 모델 품질에 큰 영향을 미칩니다. 우리는이 단계가 사소한 일이라고 생각합니다. pdf2txt 폴더에서 PDF2TXT 변환을위한 도구를 해제합니다. 그것은 pdf2image , easyocr , ditod 및 detectron2 에 기반을두고 있습니다. 자세한 내용은 pdf2txt 의 readme.md를 참조하십시오.







이 프로젝트가 귀하의 연구에 유용하다고 생각되면 다음을 고려하십시오.
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


