LongLoRA
1.0.0
Longlora:ロングコンテキストの大型言語モデルの効率的な微調整[紙]
Yukang Chen、Shengju Qian、Haotian Tang、Xin Lai、Zhijian Liu、Song Han、Jiaya Jia
RequirementsとInstallation and Quick Guideセクションの両方をお読みください。事前に訓練されたウェイトをダウンロードして使用するには、必要です。
アプリケーションをインストールして実行するには:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
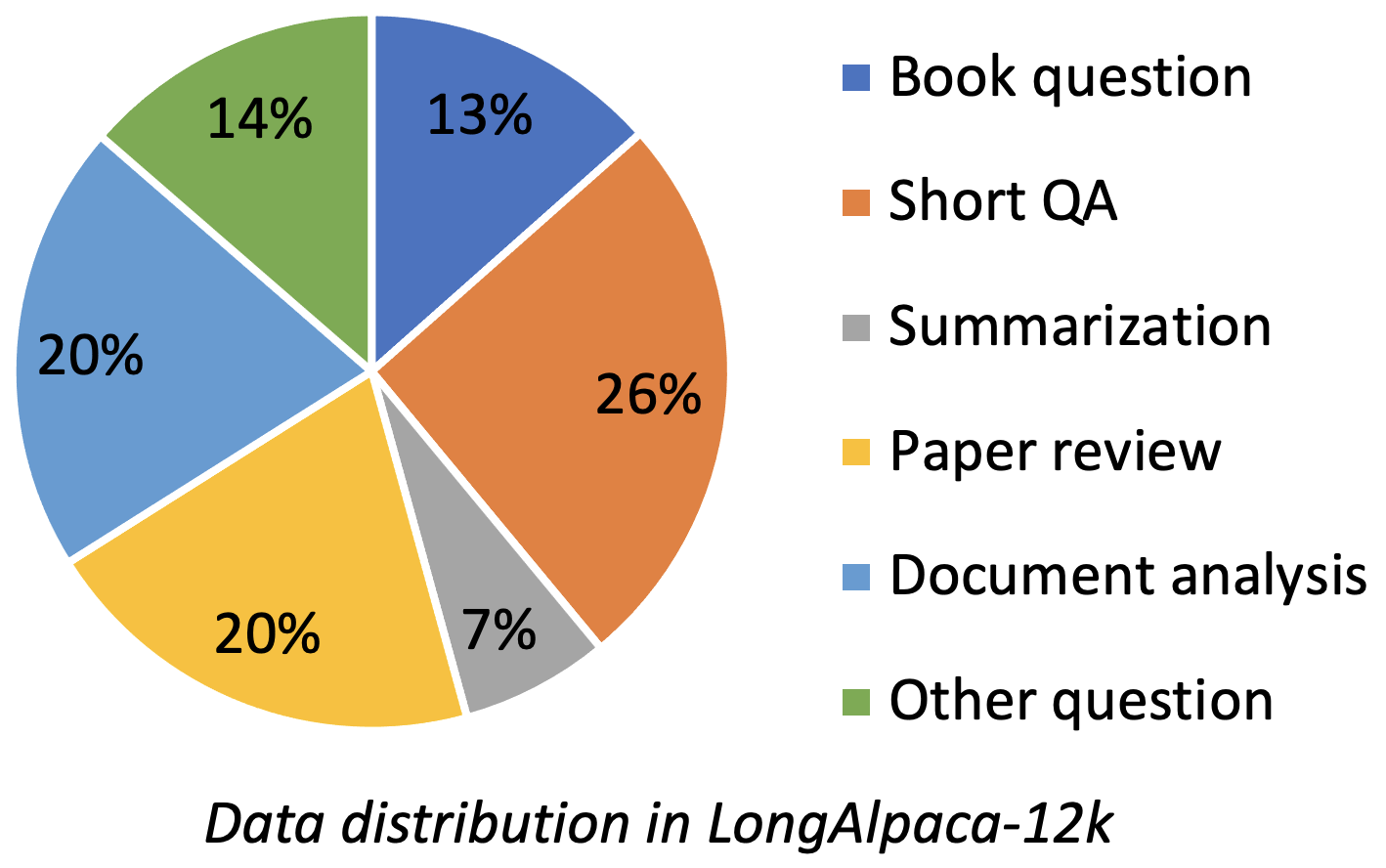
Longalpaca-12Kには、収集した9Kの長さのQAデータと、元のAlpacaデータからサンプリングされた3KショートQAが含まれています。これは、モデルが以下の短い指示で劣化する可能性がある場合を回避するためです。収集したデータには、次の図としてさまざまなタイプと量が含まれています。
| データ | 短いqa | 長いQa | 合計 | ダウンロード |
|---|---|---|---|---|
| Longalpaca-12k | 3k | 9k | 12k | リンク |
元のALPACA形式に従って、長いQAデータでは、次のプロンプトを微調整するために使用します。
instruction : str 、モデルが実行するタスクを説明します。たとえば、本のセクションや紙を読んだ後に質問に答えること。指示を多様にするために、内容と質問を変化させます。output : str 、命令に対する答え。簡単にするために、Alpaca形式のinput形式を使用しませんでした。
| モデル | サイズ | コンテクスト | 電車 | リンク |
|---|---|---|---|---|
| longalpaca-7b | 7b | 32768 | フルFT | モデル |
| longalpaca-13b | 13b | 32768 | フルFT | モデル |
| longalpaca-70b | 70b | 32768 | ロラ+ | モデル(lora-weight) |
| モデル | サイズ | コンテクスト | 電車 | リンク |
|---|---|---|---|---|
| llama-2-7b-longlora-8k-ft | 7b | 8192 | フルFT | モデル |
| llama-2-7b-longlora-16k-ft | 7b | 16384 | フルFT | モデル |
| llama-2-7b-longlora-32k-ft | 7b | 32768 | フルFT | モデル |
| llama-2-7b-longlora-100k-ft | 7b | 100000 | フルFT | モデル |
| llama-2-13b-longlora-8k-ft | 13b | 8192 | フルFT | モデル |
| llama-2-13b-longlora-16k-ft | 13b | 16384 | フルFT | モデル |
| llama-2-13b-longlora-32k-ft | 13b | 32768 | フルFT | モデル |
| モデル | サイズ | コンテクスト | 電車 | リンク |
|---|---|---|---|---|
| llama-2-7b-longlora-8k | 7b | 8192 | ロラ+ | lora-weight |
| llama-2-7b-longlora-16k | 7b | 16384 | ロラ+ | lora-weight |
| llama-2-7b-longlora-32k | 7b | 32768 | ロラ+ | lora-weight |
| llama-2-13b-longlora-8k | 13b | 8192 | ロラ+ | lora-weight |
| llama-2-13b-longlora-16k | 13b | 16384 | ロラ+ | lora-weight |
| llama-2-13b-longlora-32k | 13b | 32768 | ロラ+ | lora-weight |
| llama-2-13b-longlora-64k | 13b | 65536 | ロラ+ | lora-weight |
| llama-2-70b-longlora-32k | 70b | 32768 | ロラ+ | lora-weight |
| llama-2-70b-chat-longlora-32k | 70b | 32768 | ロラ+ | lora-weight |
Llama2モデルを事前に訓練した重みとして使用し、それらを長いコンテキストウィンドウサイズに微調整します。選択に基づいてダウンロードしてください。
| 事前に訓練されたウェイト |
|---|
| llama-2-7b-hf |
| llama-2-13b-hf |
| llama-2-70b-hf |
| llama-2-7b-chat-hf |
| llama-2-13b-chat-hf |
| llama-2-70b-chat-hf |
このプロジェクトは、ベースモデルアーキテクチャとしてGptneoxモデルもサポートしています。訓練を受けた事前に訓練された重量には、GPT-Neox-20B、ポリグロット-KO-12.8B、その他のバリアントが含まれる場合があります。
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf 、 path_to_saving_checkpoints 、 path_to_cache独自のディレクトリに変更することを忘れないでください。model_max_length他の値に変更できることに注意してください。ds_configs/stage2.jsonをds_configs/stage3.jsonに変更できます。use_flash_attn Falseとして設定してください。low_rank_training Falseとして設定できます。より多くのGPUメモリと遅いコストがかかりますが、パフォーマンスは少し良くなります。 cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
path_to_saving_checkpointsは、deepspeedバージョンに依存するGlobal_Stepディレクトリである可能性があることに注意してください。
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
低ランクのトレーニングでは、埋め込み層と正規化層をトレーニング可能に設定します。次の行を使用して、 pytorch_model.binからトレーニング可能なウェイトトレーニングtrainable_params.binを抽出してください
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
pytorch_model.binとトレーニング可能なパラメーターのloraウェイトをマージして、 trainable_params.bin 、結果のモデルを抱きしめる顔形式の目的のパスに保存します。
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
例えば、
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
低ランク設定でトレーニングされているモデルを評価するには、 base_modelとpeft_model両方を設定してください。 base_model事前に訓練された重量です。 peft_model 、保存されたチェックポイントへのパスであり、 trainable_params.bin 、 adapter_model.bin 、 adapter_config.jsonを含む必要があります。例えば、
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
または、次のように複数のGPUで評価します。
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
完全に微調整さconfig.jsonたモデルを評価するには、 base_model保存pytorch_model.binれたチェックポイントへのパスとして設定する必要があります。 peft_model無視する必要があります。
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
または、次のように複数のGPUで評価します。
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
--seq_len 、評価のためにシーケンス長を設定することに注意してください。 --context_size 、微調整中にモデルのコンテキスト長を設定することです。 --seq_len 、 --context_sizeよりも大きくしてはなりません。
PG19とプルーフパイルデータセットの検証とテストスプリットをpg19/validation.bin 、 pg19/test.bin 、およびproof-pile/test_sampled_data.bin 、llamaのトークンザーとともにトークン化しました。 proof-pile/test_sampled_data.binには、Total Proof-Pileテスト分割からランダムにサンプリングされた128のドキュメントが含まれています。各ドキュメントについて、少なくとも32768トークンがあります。また、Proof-Pile/test_sampled_ids.binでサンプリングされたIDをリリースします。以下のリンクからダウンロードできます。
| データセット | スプリット | リンク |
|---|---|---|
| PG19 | 検証 | pg19/validation.bin |
| PG19 | テスト | PG19/test.bin |
| プルーフパイル | テスト | Proof-Pile/test_sampled_data.bin |
PassKeyの検索精度をテストする方法を提供します。例えば、
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size 、微調整中のコンテキストの長さであることに注意してください。max_tokens 、PassKey検索評価のドキュメントの最大長です。interval 、ドキュメントの長さが増加する間の間隔です。文書が文によって増加するため、これは大まかな数です。 Longalpacaモデルとチャットするには、
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
本に関連する質問をする:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
論文に関連する質問をする:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
独自のデモ実行を展開します
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
例
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=Trueは生成を遅くしますが、多くのGPUメモリを保存することに注意してください。 streamingllmを使用したLongalpacaモデルの推論をサポートしています。これにより、Streamingllmのマルチラウンドダイアログのコンテキスト長が増加します。これが例です、
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepathは、推論のプロンプトを含むJSONファイルです。 longalpaca-12kのサブセットであるファイルoutputs_stream.jsonの例を提供します。自分の質問に置き換えることができます。 データセットコレクション中に、紙と本をPDFからテキストに変換します。変換の品質は、最終的なモデルの品質に大きな影響を与えます。このステップは自明ではないと思います。フォルダーpdf2txtで、PDF2TXT変換用のツールをリリースします。 pdf2image 、 easyocr 、 ditodおよびdetectron2の上に構築されています。詳細については、 pdf2txtのreadme.mdを参照してください。







このプロジェクトがあなたの研究で役立つと思う場合は、引用を検討してください。
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


