LongLoRA
1.0.0
Longlora: ajuste fino eficiente de modelos de lenguaje grande de contexto largo [papel]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
Requirements e Installation and Quick Guide a continuación.Para descargar y usar los pesos previamente capacitados que necesitará:
Para instalar y ejecutar la aplicación:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
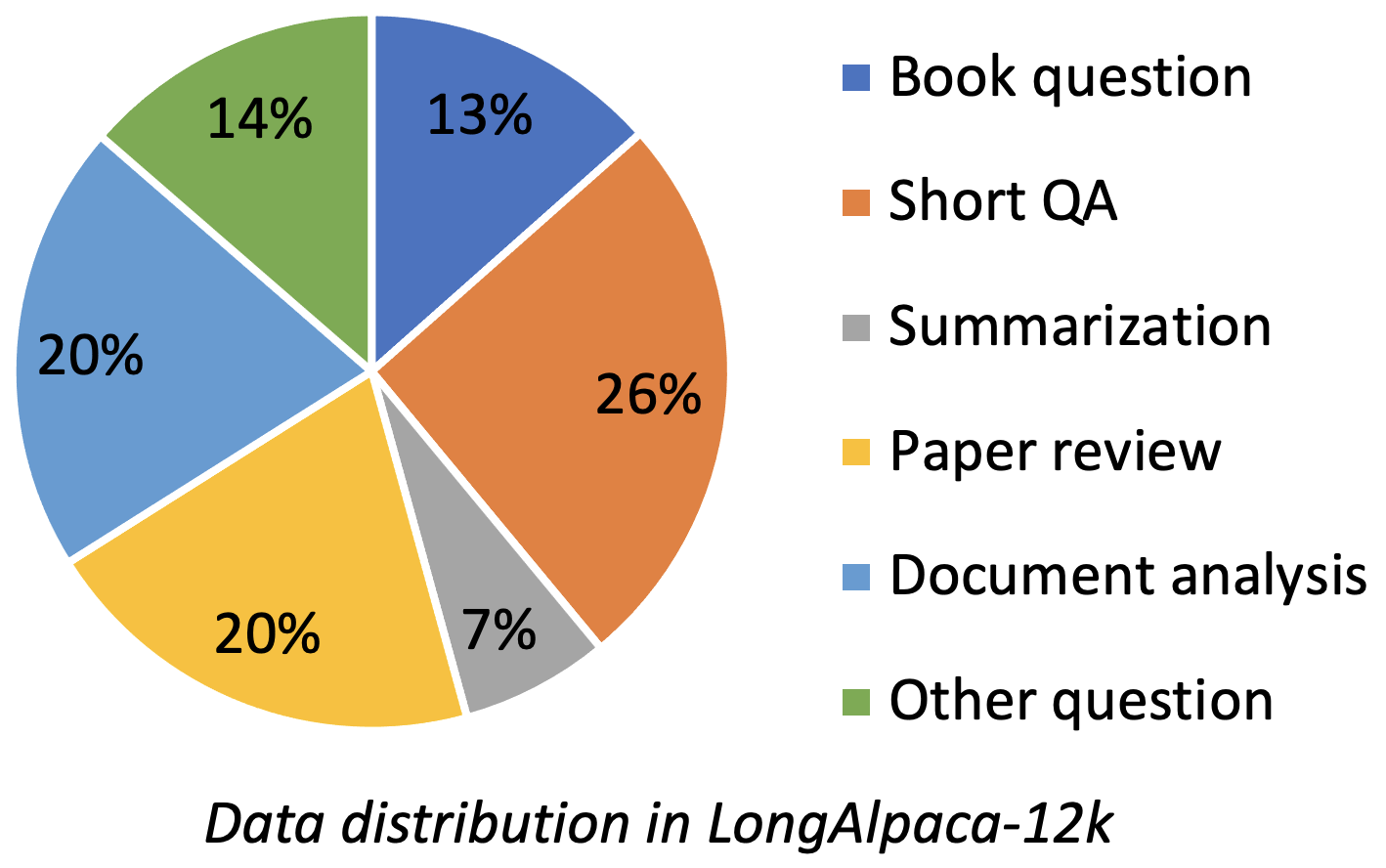
Longalpaca-12k contiene datos de control de calidad de 9k de largo que recopilamos y 3K cortos de QA muestreados a partir de los datos originales de Alpaca. Esto es para evitar el caso que el modelo podría degradarse a la instrucción corta que sigue. Los datos que recopilamos contienen varios tipos y cantidades como la siguiente figura.
| Datos | QA corto | QA largo | Total | Descargar |
|---|---|---|---|---|
| Longalpaca-12k | 3k | 9k | 12k | Enlace |
Siguiendo el formato de Alpaca original, nuestros largos datos de control de calidad utilizan las siguientes indicaciones para ajustar:
instruction : str , describe la tarea que debe realizar el modelo. Por ejemplo, para responder una pregunta después de leer una sección o documento del libro. Varimos los contenidos y las preguntas para hacer diversas instrucciones.output : str , la respuesta a la instrucción. No usamos el formato input en el formato Alpaca por simplicidad.
| Modelo | Tamaño | Contexto | Tren | Enlace |
|---|---|---|---|---|
| Longalpaca-7b | 7b | 32768 | Ft completo | Modelo |
| Longalpaca-13b | 13B | 32768 | Ft completo | Modelo |
| Longalpaca-70b | 70b | 32768 | Lora+ | Modelo (lora-peso) |
| Modelo | Tamaño | Contexto | Tren | Enlace |
|---|---|---|---|---|
| LLAMA-2-7B-LENGLora-8K-FT | 7b | 8192 | Ft completo | Modelo |
| Llama-2-7B-Longlora-16k-ft | 7b | 16384 | Ft completo | Modelo |
| LLAMA-2-7B-LONGLora-32K-FT | 7b | 32768 | Ft completo | Modelo |
| Llama-2-7B-Longlora-100k-ft | 7b | 100000 | Ft completo | Modelo |
| Llama-2-13b-longlora-8k-ft | 13B | 8192 | Ft completo | Modelo |
| Llama-2-13b-Longlora-16k-ft | 13B | 16384 | Ft completo | Modelo |
| Llama-2-13b-longlora-32k-ft | 13B | 32768 | Ft completo | Modelo |
| Modelo | Tamaño | Contexto | Tren | Enlace |
|---|---|---|---|---|
| LLAMA-2-7B-LENGLora-8K | 7b | 8192 | Lora+ | Lora-peso |
| Llama-2-7B-Longlora-16k | 7b | 16384 | Lora+ | Lora-peso |
| LLAMA-2-7B-LENGLora-32K | 7b | 32768 | Lora+ | Lora-peso |
| Llama-2-13b-longlora-8k | 13B | 8192 | Lora+ | Lora-peso |
| Llama-2-13b-Longlora-16k | 13B | 16384 | Lora+ | Lora-peso |
| Llama-2-13b-longlora-32k | 13B | 32768 | Lora+ | Lora-peso |
| Llama-2-13b-longlora-64k | 13B | 65536 | Lora+ | Lora-peso |
| Llama-2-70B-Longlora-32k | 70b | 32768 | Lora+ | Lora-peso |
| LLAMA-2-70B-CHAT-LONGLora-32K | 70b | 32768 | Lora+ | Lora-peso |
Utilizamos modelos LLAMA2 como pesos previamente capacitados y los ajustan a los tamaños de ventanas de contexto largos. Descargar basado en sus elecciones.
| Pesos previamente capacitados |
|---|
| Llama-2-7B-HF |
| Llama-2-13B-HF |
| LLAMA-2-70B-HF |
| LLAMA-2-7B-CHAT-HF |
| Llama-2-13B-CHAT-HF |
| LLAMA-2-70B-CHAT-HF |
Este proyecto también admite los modelos GPTNEOX como la arquitectura del modelo base. Algunos pesos previamente capacitados candidatos pueden incluir GPT-NEOX-20B, Polyglot-KO-12.8b y otras variantes.
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf , path_to_saving_checkpoints , path_to_cache a su propio directorio.model_max_length a otros valores.ds_configs/stage2.json a ds_configs/stage3.json si lo desea.use_flash_attn como False si usa máquinas V100 o no instala atención Flash.low_rank_training como False si desea usar completamente ajustado. Costará más memoria de GPU y más lenta, pero el rendimiento será un poco mejor. cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
Tenga en cuenta que el PATH_TO_Saving_CheckPoints podría ser el directorio Global_Step, que depende de las versiones de DeepSpeed.
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
En el entrenamiento de bajo rango, establecemos capas de incrustación y normalización como entrenables. Utilice la siguiente línea para extraer los pesos entrenables trainable_params.bin de pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
Fusione los pesos lora de pytorch_model.bin y parámetros capacitables trainable_params.bin , guarde el modelo resultante en su camino deseado en el formato de la cara abrazada:
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
Por ejemplo,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
Para evaluar un modelo que está entrenado en la configuración de bajo rango, establezca tanto base_model como peft_model . base_model es el peso previamente capacitado. peft_model es la ruta al punto de control guardado, que debe contener trainable_params.bin , adapter_model.bin y adapter_config.json . Por ejemplo,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
O evaluar con múltiples GPU de la siguiente manera.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Para evaluar un modelo que está completamente ajustado, solo necesita establecer base_model como la ruta al punto de control guardado, que debe contener pytorch_model.bin y config.json . peft_model debe ser ignorado.
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
O evaluar con múltiples GPU de la siguiente manera.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Tenga en cuenta que --seq_len debe establecer la longitud de secuencia para la evaluación. --context_size es establecer la longitud de contexto del modelo durante el ajuste fino. --seq_len no debe ser más grande que --context_size .
Ya hemos tocado las divisiones de validación y prueba de PG19 y el conjunto de datos de prueba de prueba en pg19/validation.bin , pg19/test.bin , y proof-pile/test_sampled_data.bin , con el tokenizer de llama. proof-pile/test_sampled_data.bin contiene 128 documentos que se muestrean aleatoriamente de la división de prueba de prueba de prueba total. Para cada documento, tiene al menos 32768 fichas. También liberamos los ID de muestreo en PROY-PILE/TEST_SAMPLED_IDS.BIN. Puede descargarlos desde los enlaces a continuación.
| Conjunto de datos | Dividir | Enlace |
|---|---|---|
| PG19 | validación | pg19/validation.bin |
| PG19 | prueba | PG19/test.bin |
| Prueba | prueba | Prueba-pile/test_sampled_data.bin |
Proporcionamos una manera para probar la precisión de recuperación de Key Key. Por ejemplo,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size es la longitud del contexto durante el ajuste fino.max_tokens es la longitud máxima para el documento en la evaluación de recuperación de passkey.interval es el intervalo durante la longitud del documento que aumenta. Es un número aproximado porque el documento aumenta por oraciones. Para chatear con modelos longalpaca,
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
Para hacer una pregunta relacionada con un libro:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
Para hacer una pregunta relacionada con un documento:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
Para implementar su propia demostración ejecutada
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
Ejemplo
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True hará que la generación sea lenta pero ahorrará mucha memoria GPU. Apoyamos la inferencia de los modelos Longalpaca con Streamingllm. Esto aumenta la longitud del contexto del diálogo de múltiples ronda en la transmisión. Aquí hay un ejemplo,
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath es el archivo JSON que contiene indicaciones para la inferencia. Proporcionamos un archivo de ejemplo salidas_stream.json, que es un subconjunto de longalpaca-12k. Puede reemplazarlo a sus propias preguntas. Durante nuestra colección de conjuntos de datos, convertimos papel y libros de PDF a texto. La calidad de conversión tiene una gran influencia en la calidad final del modelo. Creemos que este paso no es trivial. Lanzamos la herramienta para la conversión PDF2TXT, en la carpeta pdf2txt . Se basa en pdf2image , easyocr , ditod y detectron2 . Consulte el ReadMe.md en pdf2txt para obtener más detalles.







Si encuentra útil este proyecto en su investigación, considere citar:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


