LongLoRA
1.0.0
Longlora: صقل فعال لنماذج لغة كبيرة في السياق [ورقة]
Yukang Chen ، Shengju Qian ، Haotian Tang ، Xin Lai ، Zhijian Liu ، Song Han ، Jiaya Jia
Requirements والتثبيت Installation and Quick Guide أدناه.لتنزيل الأوزان التي ستحتاج إليها واستخدامها:
لتثبيت التطبيق وتشغيله:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
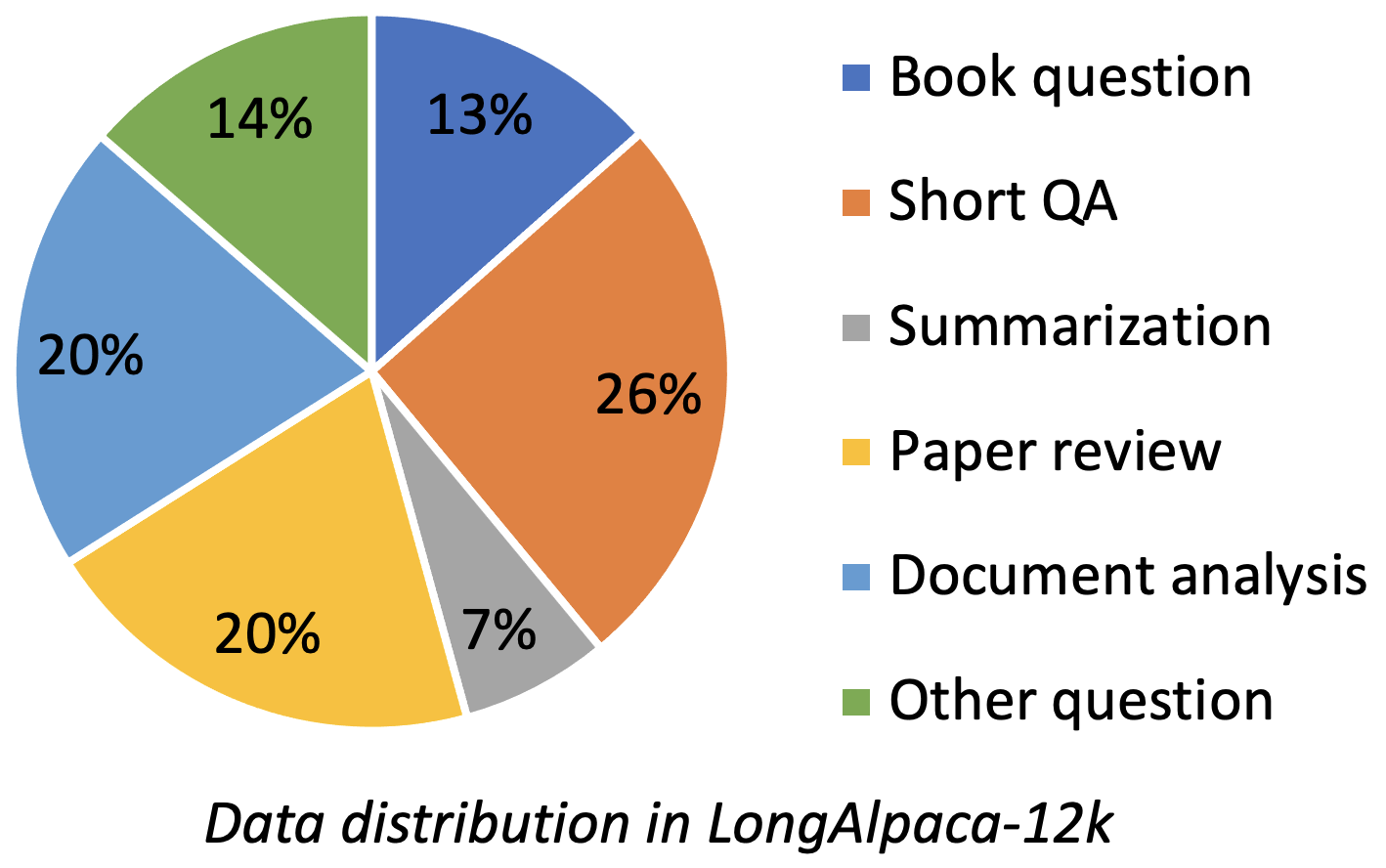
يحتوي LongalPaca-12k على بيانات QA طويلة 9K التي جمعناها وأخذ عينات من QA قصيرة 3K من بيانات الألبكة الأصلية. هذا لتجنب الحالة التي قد يتحللها النموذج بناءً على تعليمات قصيرة. تحتوي البيانات التي نجمعها على أنواع ومبالغ مختلفة مثل الشكل التالي.
| بيانات | QA قصيرة | QA طويل | المجموع | تحميل |
|---|---|---|---|---|
| Longalpaca-12k | 3K | 9k | 12 كيلو | وصلة |
بعد تنسيق الألبكة الأصلي ، تستخدم بيانات ضمان الجودة الطويلة لدينا المطالبات التالية للضبط:
instruction : str ، يصف المهمة التي يجب أن يؤديها النموذج. على سبيل المثال ، للإجابة على سؤال بعد قراءة قسم كتاب أو ورقة. نحن نختلف المحتويات والأسئلة لجعل التعليمات متنوعة.output : str ، إجابة التعليمات. لم نستخدم تنسيق input في تنسيق الألبكة للبساطة.
| نموذج | مقاس | سياق | يدرب | وصلة |
|---|---|---|---|---|
| Longalpaca-7b | 7 ب | 32768 | قدم كاملة | نموذج |
| Longalpaca-13b | 13 ب | 32768 | قدم كاملة | نموذج |
| Longalpaca-70b | 70 ب | 32768 | لورا+ | النموذج (لورا الوزن) |
| نموذج | مقاس | سياق | يدرب | وصلة |
|---|---|---|---|---|
| llama-2-7b-longlora-8k-ft | 7 ب | 8192 | قدم كاملة | نموذج |
| llama-2-7b-longlora-16k-ft | 7 ب | 16384 | قدم كاملة | نموذج |
| llama-2-7b-longlora-32k-ft | 7 ب | 32768 | قدم كاملة | نموذج |
| LLAMA-2-7B-LONGLORA-100K-FT | 7 ب | 100000 | قدم كاملة | نموذج |
| Llama-2-13b-Longlora-8K-Ft | 13 ب | 8192 | قدم كاملة | نموذج |
| Llama-2-13b-Longlora-16K-Ft | 13 ب | 16384 | قدم كاملة | نموذج |
| Llama-2-13b-Longlora-32k-Ft | 13 ب | 32768 | قدم كاملة | نموذج |
| نموذج | مقاس | سياق | يدرب | وصلة |
|---|---|---|---|---|
| llama-2-7b-longlora-8k | 7 ب | 8192 | لورا+ | لورا وايت |
| Llama-2-7b-longlora-16k | 7 ب | 16384 | لورا+ | لورا وايت |
| Llama-2-7b-longlora-32k | 7 ب | 32768 | لورا+ | لورا وايت |
| llama-2-13b-longlora-8k | 13 ب | 8192 | لورا+ | لورا وايت |
| Llama-2-13b-Longlora-16K | 13 ب | 16384 | لورا+ | لورا وايت |
| Llama-2-13b-Longlora-32k | 13 ب | 32768 | لورا+ | لورا وايت |
| llama-2-13b-longlora-64k | 13 ب | 65536 | لورا+ | لورا وايت |
| Llama-2-70b-longlora-32k | 70 ب | 32768 | لورا+ | لورا وايت |
| LLAMA-2-70B-Chat-Longlora-32K | 70 ب | 32768 | لورا+ | لورا وايت |
نحن نستخدم نماذج Llama2 كأوزان مدربة مسبقًا وضبطها على أحجام نوافذ السياق الطويلة. تنزيل بناءً على اختياراتك.
| الأوزان المدربة مسبقا |
|---|
| Llama-2-7B-HF |
| Llama-2-13b-HF |
| Llama-2-70B-HF |
| Llama-2-7b-Chat-Hf |
| Llama-2-13b-Chat-Hf |
| LLAMA-2-70B-Chat-HF |
يدعم هذا المشروع أيضًا نماذج GPTNEOX باعتبارها بنية النموذج الأساسي. قد تشمل بعض الأوزان التي تم تدريبها مسبقًا GPT-NEOX-20B و Polyglot-KO-12.8B وغيرها من المتغيرات.
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf ، path_to_saving_checkpoints ، path_to_cache إلى الدليل الخاص بك.model_max_length إلى قيم أخرى.ds_configs/stage2.json إلى ds_configs/stage3.json إذا كنت تريد.use_flash_attn False إذا كنت تستخدم آلات V100 أو عدم تثبيت اهتمام فلاش.low_rank_training False إذا كنت تريد استخدام الضبط بالكامل. سيكلف المزيد من ذاكرة GPU وأبطأ ، لكن الأداء سيكون أفضل قليلاً. cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
لاحظ أن path_to_saving_checkpoints قد يكون دليل global_step ، والذي يعتمد على إصدارات السرعة العميقة.
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
في التدريب منخفض الرتبة ، وضعنا طبقات التضمين والتطبيع على أنها قابلة للتدريب. يرجى استخدام السطر التالي لاستخراج الأوزان القابلة للتدريب trainable_params.bin من pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
دمج أوزان lora من pytorch_model.bin والمعلمات القابلة للتدريب trainable_params.bin ، احفظ النموذج الناتج في المسار المطلوب في تنسيق وجه المعانقة:
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
على سبيل المثال،
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
لتقييم نموذج يتم تدريبه في الإعداد منخفض الرتبة ، يرجى تعيين كل من base_model و peft_model . base_model هو الوزن المدربين مسبقًا. peft_model هو المسار إلى نقطة التفتيش المحفوظة ، والتي يجب أن تحتوي على trainable_params.bin و adapter_model.bin و adapter_config.json . على سبيل المثال،
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
أو تقييم مع وحدات معالجة الرسومات المتعددة على النحو التالي.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
لتقييم نموذج يتم ضبطه بالكامل ، تحتاج فقط إلى تعيين base_model كمسار إلى نقطة التفتيش المحفوظة ، والتي يجب أن تحتوي على pytorch_model.bin و config.json . يجب تجاهل peft_model .
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
أو تقييم مع وحدات معالجة الرسومات المتعددة على النحو التالي.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
لاحظ أن --seq_len هو تعيين طول التسلسل للتقييم. --context_size هو تعيين طول السياق للنموذج أثناء الضبط الدقيق. --seq_len لا ينبغي أن يكون أكبر من- --context_size .
لقد قمنا بالفعل برمز التحقق من صحة واختبار مجموعة بيانات PG19 ومجموعة بيانات الإثبات في pg19/validation.bin pg19/test.bin proof-pile/test_sampled_data.bin . يحتوي proof-pile/test_sampled_data.bin على 128 وثيقة يتم أخذ عينات منها بشكل عشوائي من تقسيم اختبار الإثبات الكلي. لكل وثيقة ، لديها ما لا يقل عن 32768 رمز الرموز. نقوم أيضًا بإصدار المعرفات التي تم أخذ عينات منها في الإثبات/test_sampled_ids.bin. يمكنك تنزيلها من الروابط أدناه.
| مجموعة البيانات | ينقسم | وصلة |
|---|---|---|
| PG19 | تصديق | PG19/التحقق من الصحة |
| PG19 | امتحان | PG19/Test.bin |
| إثبات الولادة | امتحان | إثبات pile/test_sampled_data.bin |
نحن نقدم طريقة لاختبار دقة استرجاع مفتاح المرور. على سبيل المثال،
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size هو طول السياق أثناء الضبط الدقيق.max_tokens هو الحد الأقصى للوثيقة في تقييم استرجاع مفتاح المرور.interval هو الفاصل الزمني أثناء زيادة طول المستند. إنه رقم تقريبي لأن المستند يزداد حسب الجمل. للدردشة مع طرز Longalpaca ،
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
لطرح سؤال يتعلق بكتاب:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
لطرح سؤال يتعلق بالورقة:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
لنشر التشغيل التجريبي الخاص بك
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
مثال
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True سيجعل الجيل بطيئًا ولكن حفظ الكثير من ذاكرة GPU. نحن ندعم استنتاج نماذج LongalPaca مع Dreamingllm. هذا يزيد من طول السياق للحوار متعدد الدورات في DreamingLlm. هنا مثال ،
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath هو ملف JSON الذي يحتوي على مطالبات للاستدلال. نحن نقدم مثال ملف Outss_stream.json ، وهي مجموعة فرعية من LongalPaca-12k. يمكنك استبدالها بأسئلتك الخاصة. خلال مجموعة البيانات الخاصة بنا ، نقوم بتحويل الورق والكتب من PDF إلى نص. جودة التحويل لها تأثير كبير على جودة النموذج النهائي. نعتقد أن هذه الخطوة غير تافهة. ننشر الأداة لتحويل PDF2TXT ، في المجلد pdf2txt . وهو مبني على pdf2image ، easyocr ، ditod و detectron2 . يرجى الرجوع إلى readme.md في pdf2txt لمزيد من التفاصيل.







إذا وجدت هذا المشروع مفيدًا في بحثك ، فيرجى التفكير في:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


