LongLoRA
1.0.0
Longlora: การปรับจูนแบบจำลองภาษาขนาดใหญ่ที่มีประสิทธิภาพยาวนาน [Paper]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, เพลง Han, Jiaya Jia
Requirements และ Installation and Quick Guide ด้านล่างในการดาวน์โหลดและใช้น้ำหนักที่ได้รับการฝึกอบรมล่วงหน้าที่คุณต้องการ:
ในการติดตั้งและเรียกใช้แอปพลิเคชัน:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
Longalpaca-12K มีข้อมูล QA ยาว 9k ที่เรารวบรวมและ QA สั้น 3K ตัวอย่างจากข้อมูล Alpaca ดั้งเดิม นี่คือการหลีกเลี่ยงกรณีที่โมเดลอาจลดระดับการเรียนการสอนสั้น ๆ ต่อไปนี้ ข้อมูลที่เรารวบรวมมีประเภทและจำนวนที่หลากหลายเป็นรูปต่อไปนี้
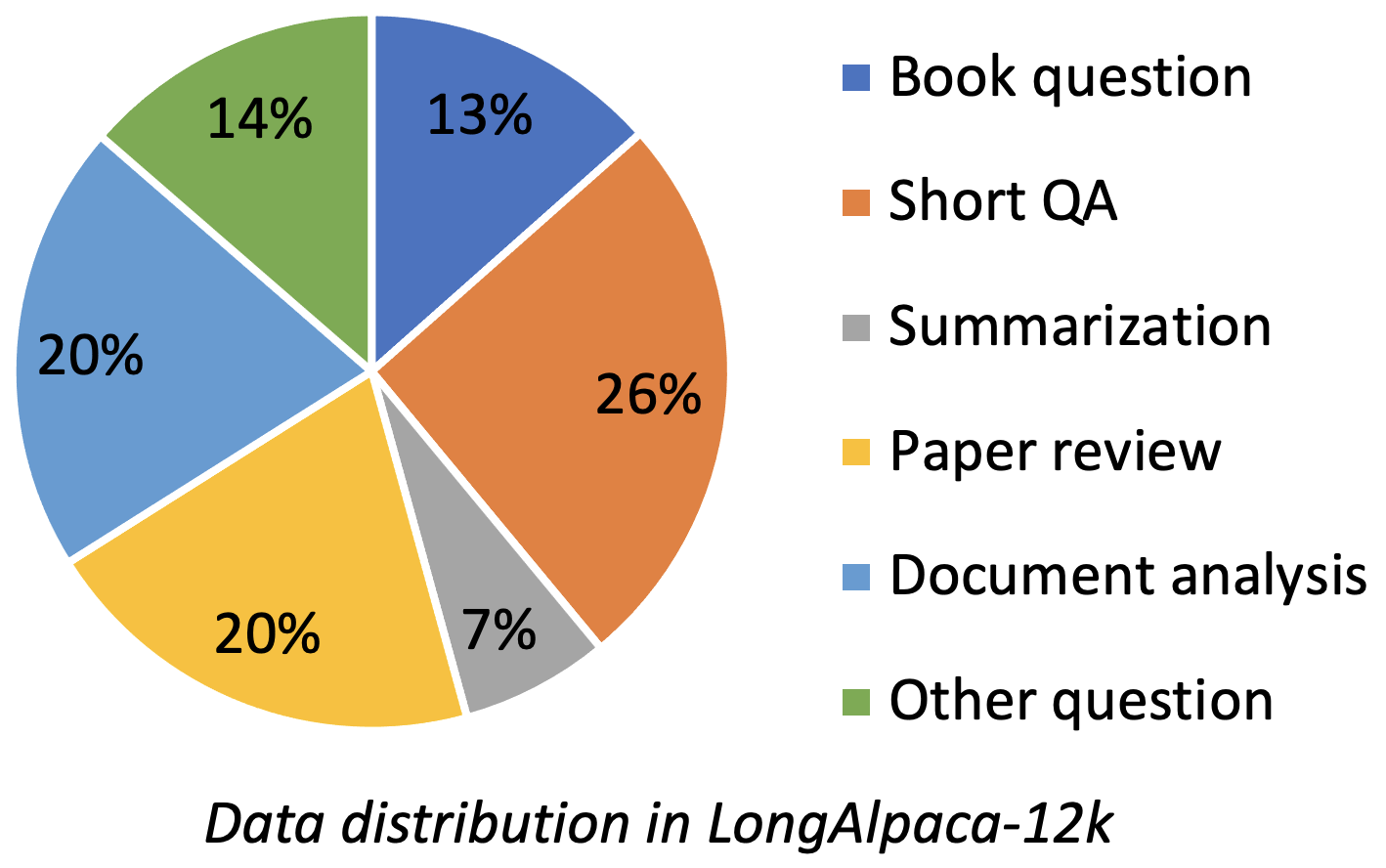
| ข้อมูล | QA สั้น ๆ | QA ยาว | ทั้งหมด | การดาวน์โหลด |
|---|---|---|---|---|
| Longalpaca-12k | 3K | 9K | 12K | การเชื่อมโยง |
ตามรูปแบบ Alpaca ดั้งเดิมข้อมูล QA ยาวของเราใช้พรอมต์ต่อไปนี้สำหรับการปรับแต่ง:
instruction : str อธิบายงานที่โมเดลควรดำเนินการ ตัวอย่างเช่นเพื่อตอบคำถามหลังจากอ่านส่วนหนังสือหรือกระดาษ เราเปลี่ยนแปลงเนื้อหาและคำถามเพื่อให้คำแนะนำที่หลากหลายoutput : str คำตอบของคำแนะนำ เราไม่ได้ใช้รูปแบบ input ในรูปแบบ Alpaca เพื่อความเรียบง่าย
| แบบอย่าง | ขนาด | บริบท | รถไฟ | การเชื่อมโยง |
|---|---|---|---|---|
| Longalpaca-7b | 7b | 32768 | เต็มฟุต | แบบอย่าง |
| Longalpaca-13b | 13B | 32768 | เต็มฟุต | แบบอย่าง |
| Longalpaca-70b | 70b | 32768 | Lora+ | รุ่น (Lora-Weight) |
| แบบอย่าง | ขนาด | บริบท | รถไฟ | การเชื่อมโยง |
|---|---|---|---|---|
| llama-2-7b-longlora-8k-ft | 7b | 8192 | เต็มฟุต | แบบอย่าง |
| llama-2-7b-longlora-16k-ft | 7b | 16384 | เต็มฟุต | แบบอย่าง |
| llama-2-7b-longlora-32k-ft | 7b | 32768 | เต็มฟุต | แบบอย่าง |
| llama-2-7b-longlora-100k-ft | 7b | 100000 | เต็มฟุต | แบบอย่าง |
| llama-2-13b-longlora-8k-ft | 13B | 8192 | เต็มฟุต | แบบอย่าง |
| llama-2-13b-longlora-16k-ft | 13B | 16384 | เต็มฟุต | แบบอย่าง |
| llama-2-13b-longlora-32k-ft | 13B | 32768 | เต็มฟุต | แบบอย่าง |
| แบบอย่าง | ขนาด | บริบท | รถไฟ | การเชื่อมโยง |
|---|---|---|---|---|
| LLAMA-2-7B-LONGLORA-8K | 7b | 8192 | Lora+ | Lora-Weight |
| LLAMA-2-7B-LONGLORA-16K | 7b | 16384 | Lora+ | Lora-Weight |
| LLAMA-2-7B-LONGLORA-32K | 7b | 32768 | Lora+ | Lora-Weight |
| LLAMA-2-13B-LONGLORA-8K | 13B | 8192 | Lora+ | Lora-Weight |
| LLAMA-2-13B-LONGLORA-16K | 13B | 16384 | Lora+ | Lora-Weight |
| LLAMA-2-13B-LONGLORA-32K | 13B | 32768 | Lora+ | Lora-Weight |
| LLAMA-2-13B-LONGLORA-64K | 13B | 65536 | Lora+ | Lora-Weight |
| LLAMA-2-70B-LONGLORA-32K | 70b | 32768 | Lora+ | Lora-Weight |
| LLAMA-2-70B-Chat-Longlora-32K | 70b | 32768 | Lora+ | Lora-Weight |
เราใช้โมเดล LLAMA2 เป็นน้ำหนักที่ได้รับการฝึกอบรมล่วงหน้าและปรับให้เข้ากับขนาดของหน้าต่างบริบทที่ยาว ดาวน์โหลดตามตัวเลือกของคุณ
| น้ำหนักที่ได้รับการฝึกอบรมล่วงหน้า |
|---|
| LLAMA-2-7B-HF |
| llama-2-13b-hf |
| LLAMA-2-70B-HF |
| llama-2-7b-chat-hf |
| llama-2-13b-chat-hf |
| LLAMA-2-70B-Chat-HF |
โครงการนี้ยังรองรับรุ่น GPTNEOX เป็นสถาปัตยกรรมแบบจำลองพื้นฐาน น้ำหนักที่ได้รับการฝึกอบรมล่วงหน้าผู้สมัครบางคนอาจรวมถึง GPT-NEOX-20B, PolyGlot-KO-12.8B และตัวแปรอื่น ๆ
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf , path_to_saving_checkpoints , path_to_cache ไปยังไดเรกทอรีของคุณเองmodel_max_length เป็นค่าอื่น ๆds_configs/stage2.json เป็น ds_configs/stage3.json หากคุณต้องการuse_flash_attn เป็น False ถ้าคุณใช้เครื่อง V100 หรือไม่ติดตั้งความสนใจของแฟลชlow_rank_training เป็น False หากคุณต้องการใช้การปรับแต่งอย่างสมบูรณ์ มันจะมีค่าใช้จ่ายหน่วยความจำ GPU มากขึ้นและช้าลง แต่ประสิทธิภาพจะดีขึ้นเล็กน้อย cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
โปรดทราบว่า path_to_saving_checkpoints อาจเป็นไดเรกทอรี global_step ซึ่งขึ้นอยู่กับรุ่น Deepspeed
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
ในการฝึกอบรมระดับต่ำเราตั้งค่าการฝังและการทำให้เป็นมาตรฐานในการฝึกอบรม โปรดใช้บรรทัดต่อไปนี้เพื่อสกัดน้ำหนักที่ฝึกอบรมได้ trainable_params.bin จาก pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
รวมน้ำหนัก lora ของ pytorch_model.bin และพารามิเตอร์ที่สามารถฝึกอบรมได้ trainable_params.bin , บันทึกโมเดลผลลัพธ์ลงในเส้นทางที่คุณต้องการในรูปแบบการกอดใบหน้า:
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
ตัวอย่างเช่น,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
ในการประเมินแบบจำลองที่ได้รับการฝึกฝนในการตั้งค่าระดับต่ำโปรดตั้งค่าทั้งสอง base_model และ peft_model base_model เป็นน้ำหนักที่ได้รับการฝึกอบรมล่วงหน้า peft_model เป็นเส้นทางไปยังจุดตรวจสอบที่บันทึกไว้ซึ่งควรมี trainable_params.bin , adapter_model.bin และ adapter_config.json ตัวอย่างเช่น,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
หรือประเมินด้วย GPU หลายตัวดังนี้
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
ในการประเมินแบบจำลองที่ได้รับการปรับแต่งอย่างสมบูรณ์คุณจะต้องตั้งค่า base_model เป็นเส้นทางไปยังจุดตรวจสอบที่บันทึกไว้ซึ่งควรมี pytorch_model.bin และ config.json ควรเพิกเฉยต่อ peft_model
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
หรือประเมินด้วย GPU หลายตัวดังนี้
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
โปรดทราบว่า --seq_len คือการตั้งค่าความยาวลำดับสำหรับการประเมินผล --context_size คือการตั้งค่าความยาวบริบทของโมเดลในระหว่างการปรับแต่ง --seq_len ไม่ควรใหญ่กว่า --context_size
เราได้เพิ่มการตรวจสอบความถูกต้องและการทดสอบการแยกของชุดข้อมูล PG19 และหลักฐานการสำรวจลงใน pg19/validation.bin , pg19/test.bin และ proof-pile/test_sampled_data.bin ด้วย tokenizer ของ llama proof-pile/test_sampled_data.bin มีเอกสาร 128 เอกสารที่สุ่มสุ่มจากการทดสอบการทดสอบการสำรวจทั้งหมด สำหรับแต่ละเอกสารมีโทเค็นอย่างน้อย 32768 นอกจากนี้เรายังปล่อย ID ตัวอย่างใน Proofit-Pile/Test_Sampled_ids.bin คุณสามารถดาวน์โหลดได้จากลิงค์ด้านล่าง
| ชุดข้อมูล | แยก | การเชื่อมโยง |
|---|---|---|
| PG19 | การตรวจสอบความถูกต้อง | pg19/validation.bin |
| PG19 | ทดสอบ | pg19/test.bin |
| ไพ่ | ทดสอบ | Proofit-Pile/Test_Sampled_data.bin |
เราให้วิธีการทดสอบความแม่นยำในการดึง Passkey ตัวอย่างเช่น,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size เป็นความยาวบริบทในระหว่างการปรับแต่งmax_tokens มีความยาวสูงสุดสำหรับเอกสารในการประเมินการดึง Passkeyinterval คือช่วงเวลาระหว่างความยาวเอกสารที่เพิ่มขึ้น มันเป็นหมายเลขคร่าวๆเนื่องจากเอกสารเพิ่มขึ้นตามประโยค เพื่อแชทกับรุ่น Longalpaca
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
ถามคำถามที่เกี่ยวข้องกับหนังสือ:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
ถามคำถามที่เกี่ยวข้องกับกระดาษ:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
เพื่อปรับใช้การสาธิตของคุณเอง
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
ตัวอย่าง
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True จะทำให้รุ่นช้า แต่บันทึกหน่วยความจำ GPU มาก เราสนับสนุนการอนุมานของรุ่น Longalpaca ด้วยสตรีมมิ่ง สิ่งนี้จะเพิ่มความยาวบริบทของบทสนทนาหลายรอบในสตรีมมิ่ง นี่คือตัวอย่าง
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath เป็นไฟล์ JSON ที่มีพรอมต์สำหรับการอนุมาน เราให้ตัวอย่างไฟล์ outputs_stream.json ซึ่งเป็นชุดย่อยของ longalpaca-12k คุณสามารถแทนที่เป็นคำถามของคุณเอง ในระหว่างการรวบรวมชุดข้อมูลของเราเราแปลงกระดาษและหนังสือจาก PDF เป็นข้อความ คุณภาพการแปลงมีอิทธิพลอย่างมากต่อคุณภาพของโมเดลขั้นสุดท้าย เราคิดว่าขั้นตอนนี้ไม่น่าสนใจ เราปล่อยเครื่องมือสำหรับการแปลง PDF2TXT ในโฟลเดอร์ pdf2txt มันถูกสร้างขึ้นบน pdf2image , easyocr , ditod และ detectron2 โปรดดู readme.md ใน pdf2txt สำหรับรายละเอียดเพิ่มเติม







หากคุณพบว่าโครงการนี้มีประโยชน์ในการวิจัยของคุณโปรดพิจารณาอ้าง:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


