LongLoRA
1.0.0
Longlora: affinement efficace des modèles de langage grand contexte à long contexte [papier]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
Requirements et les sections Installation and Quick Guide ci-dessous.Pour télécharger et utiliser les poids pré-formés dont vous aurez besoin:
Pour installer et exécuter l'application:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
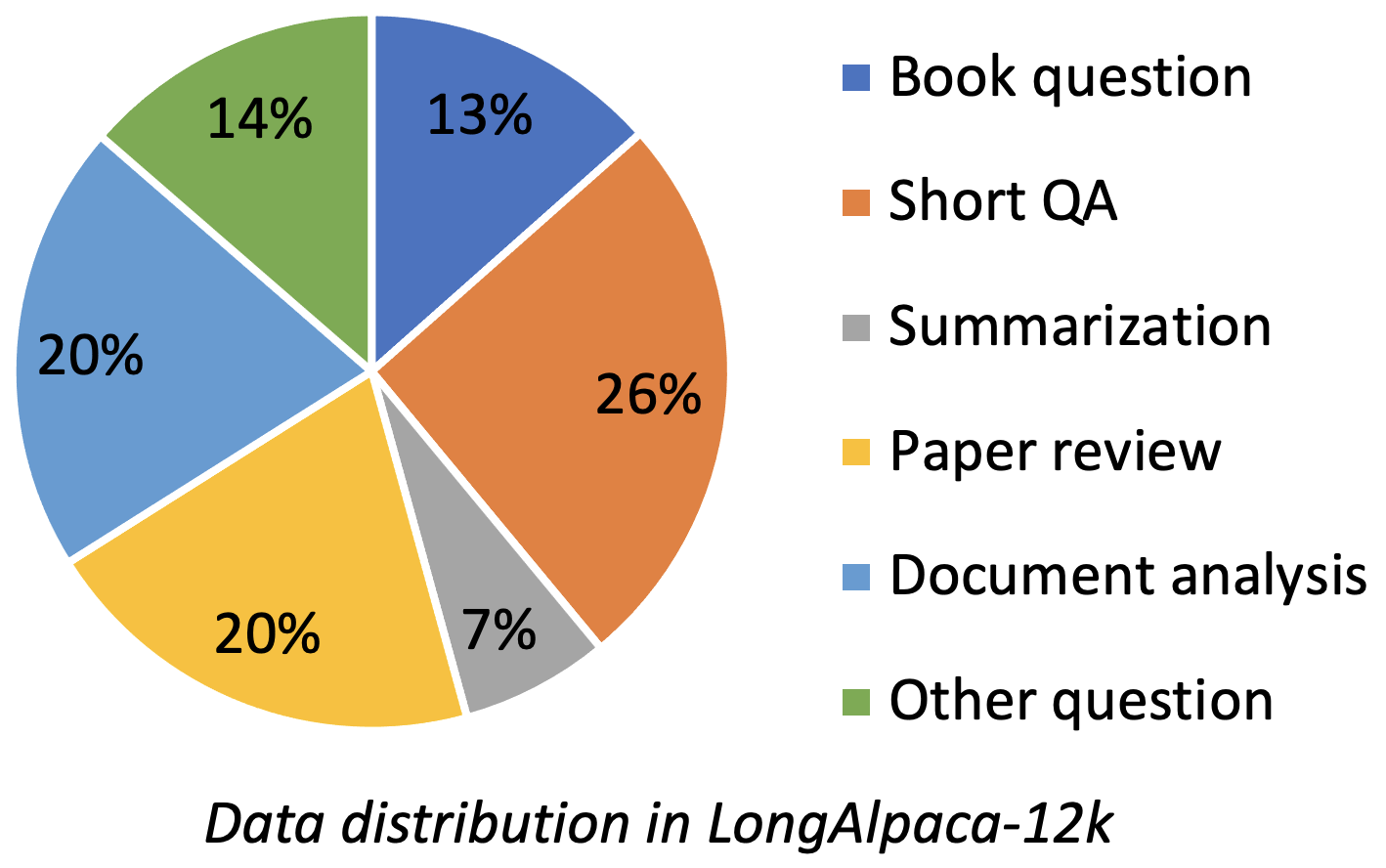
LongalPACA-12k contient des données QA de 9 km de long que nous avons collectées et 3K Short QA échantillonné à partir des données d'alpaca d'origine. Il s'agit d'éviter le cas que le modèle pourrait se dégrader à des instructions courtes suivantes. Les données que nous collectons contient différents types et montants comme la figure suivante.
| Données | QA court | QA long | Total | Télécharger |
|---|---|---|---|---|
| Longalpaca-12k | 3K | 9K | 12K | Lien |
Suivant le format Alpaca d'origine, nos longues données QA utilisent les invites suivantes pour le réglage fin:
instruction : str , décrit la tâche que le modèle doit effectuer. Par exemple, pour répondre à une question après avoir lu une section ou un article de livre. Nous varions le contenu et les questions pour rendre les instructions diverses.output : str , la réponse à l'instruction. Nous n'avons pas utilisé le format input au format alpaca pour la simplicité.
| Modèle | Taille | Contexte | Former | Lien |
|---|---|---|---|---|
| Longalpaca-7b | 7b | 32768 | Plein ft | Modèle |
| Longalpaca-13b | 13B | 32768 | Plein ft | Modèle |
| Longalpaca-70b | 70b | 32768 | Lora + | Modèle (Lora-Weight) |
| Modèle | Taille | Contexte | Former | Lien |
|---|---|---|---|---|
| Lama-2-7b-longa-8k-ft | 7b | 8192 | Plein ft | Modèle |
| LLAMA-2-7B-LONGLORA-16K-FT | 7b | 16384 | Plein ft | Modèle |
| Lama-2-7b-longa-32k-ft | 7b | 32768 | Plein ft | Modèle |
| LLAMA-2-7B-LONGLORA-100K-FT | 7b | 100000 | Plein ft | Modèle |
| Lama-2-13b-longa-8k-ft | 13B | 8192 | Plein ft | Modèle |
| LLAMA-2-13B-LONGLORA-16K-FT | 13B | 16384 | Plein ft | Modèle |
| Lama-2-13b-longa-32k-ft | 13B | 32768 | Plein ft | Modèle |
| Modèle | Taille | Contexte | Former | Lien |
|---|---|---|---|---|
| Lama-2-7b-longa-8k | 7b | 8192 | Lora + | Lora-poids |
| LLAMA-2-7B-LONGLORA-16K | 7b | 16384 | Lora + | Lora-poids |
| LLAMA-2-7B-LONGLORA-32K | 7b | 32768 | Lora + | Lora-poids |
| Lama-2-13b-longa-8k | 13B | 8192 | Lora + | Lora-poids |
| LLAMA-2-13B-LONGLORA-16K | 13B | 16384 | Lora + | Lora-poids |
| LLAMA-2-13B-LONGLORA-32K | 13B | 32768 | Lora + | Lora-poids |
| LLAMA-2-13B-LONGLORA-64K | 13B | 65536 | Lora + | Lora-poids |
| LLAMA-2-70B-LONGLORA-32K | 70b | 32768 | Lora + | Lora-poids |
| LLAMA-2-70B-CHAT-LONGLORA-32K | 70b | 32768 | Lora + | Lora-poids |
Nous utilisons les modèles LLAMA2 comme poids pré-formés et les affinons à des tailles de fenêtre de contexte longues. Téléchargez en fonction de vos choix.
| Poids pré-formés |
|---|
| Lama-2-7b-hf |
| Lama-2-13b-hf |
| Lama-2-70b-hf |
| Lama-2-7b-chat-hf |
| Lama-2-13b-chat-hf |
| Lama-2-70b-chat-hf |
Ce projet prend également en charge les modèles GPTNEOX comme architecture de modèle de base. Certains poids pré-formés candidats peuvent inclure GPT-Neox-20B, Polyglot-KO-2.8b et autres variantes.
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf , path_to_saving_checkpoints , path_to_cache vers votre propre répertoire.model_max_length en d'autres valeurs.ds_configs/stage2.json en ds_configs/stage3.json si vous le souhaitez.use_flash_attn comme False si vous utilisez des machines V100 ou n'installez pas l'attention du flash.low_rank_training en tant que False si vous souhaitez utiliser entièrement le réglage fin. Cela coûtera plus de mémoire GPU et plus lent, mais les performances seront un peu meilleures. cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
Notez que les points Path_To_Saving_Check peuvent être le répertoire global_step, qui dépend des versions DeepPeed.
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
Dans une formation de faible rang, nous avons réglé des couches d'intégration et de normalisation comme entraînant. Veuillez utiliser la ligne suivante pour extraire les poids entraînables trainable_params.bin de pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
Fusionnez les poids lora de pytorch_model.bin et des paramètres d'entraînement trainable_params.bin , enregistrez le modèle résultant dans votre chemin souhaité dans le format de face étreint:
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
Par exemple,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
Pour évaluer un modèle formé dans le réglage de bas rang, veuillez définir à la fois base_model et peft_model . base_model est le poids pré-formé. peft_model est le chemin du point de contrôle enregistré, qui doit contenir trainable_params.bin , adapter_model.bin et adapter_config.json . Par exemple,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Ou évaluer avec plusieurs GPU comme suit.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Pour évaluer un modèle entièrement affiné, il vous suffit de définir base_model comme chemin vers le point de contrôle enregistré, qui doit contenir pytorch_model.bin et config.json . peft_model doit être ignoré.
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Ou évaluer avec plusieurs GPU comme suit.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Notez que --seq_len consiste à définir la longueur de séquence pour l'évaluation. --context_size est de définir la longueur du contexte du modèle pendant le réglage fin. --seq_len ne doit pas être plus grand que --context_size .
Nous avons déjà tokenisé les divisions de validation et de test de PG19 et de jeu de données de pile de preuve dans pg19/validation.bin , pg19/test.bin , et proof-pile/test_sampled_data.bin , avec le tokenizer de Llama. proof-pile/test_sampled_data.bin contient 128 documents qui sont échantillonnés au hasard à partir du test de test de preuve total. Pour chaque document, il dispose d'au moins 32768 jetons. Nous libérons également les ID échantillonnés dans Proof-Pile / test_sampled_ids.bin. Vous pouvez les télécharger à partir des liens ci-dessous.
| Ensemble de données | Diviser | Lien |
|---|---|---|
| Pg19 | validation | pg19 / validation.bin |
| Pg19 | test | pg19 / test.bin |
| Pile de preuve | test | preuve-pile / test_sampled_data.bin |
Nous fournissons un moyen de tester la précision de la récupération de la clé passante. Par exemple,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size est la longueur du contexte pendant le réglage fin.max_tokens est une longueur maximale pour le document dans l'évaluation de la récupération de Passkey.interval est l'intervalle pendant l'augmentation de la longueur du document. C'est un nombre approximatif car le document augmente par les phrases. Pour discuter avec des modèles Longalpaca,
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
Pour poser une question liée à un livre:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
Pour poser une question liée à un article:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
Pour déployer votre propre démo
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
Exemple
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True rendra la génération lente mais enregistrera beaucoup de mémoire GPU. Nous soutenons l'inférence des modèles Longalpaca avec StreamingLLM. Cela augmente la longueur contextuelle du dialogue multi-ronde dans StreamingLLM. Voici un exemple,
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath est le fichier JSON qui contient des invites pour l'inférence. Nous fournissons un exemple de fichier de sorties_stream.json, qui est un sous-ensemble de longalpaca-12k. Vous pouvez le remplacer par vos propres questions. Au cours de notre collection de jeux de données, nous convertissons du papier et des livres de PDF au texte. La qualité de conversion a une grande influence sur la qualité finale du modèle. Nous pensons que cette étape n'est pas triviale. Nous publions l'outil pour la conversion PDF2TXT, dans le dossier pdf2txt . Il est construit sur pdf2image , easyocr , ditod et detectron2 . Veuillez vous référer à Readme.md dans pdf2txt pour plus de détails.







Si vous trouvez ce projet utile dans vos recherches, veuillez envisager de citer:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


