LongLoRA
1.0.0
Longlora: эффективная тонкая настройка длинноконтекстовых моделей крупных языков [Paper]
Юканг Чен, Шенгджу Цянь, Хаотиан Тан, Синь Лай, Чжиджян Лю, Сонг Хан, Цзяя Цзя
Requirements , так и Installation and Quick Guide разделы ниже.Чтобы загрузить и использовать предварительно обученные веса, которые вам понадобятся:
Чтобы установить и запустить приложение:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
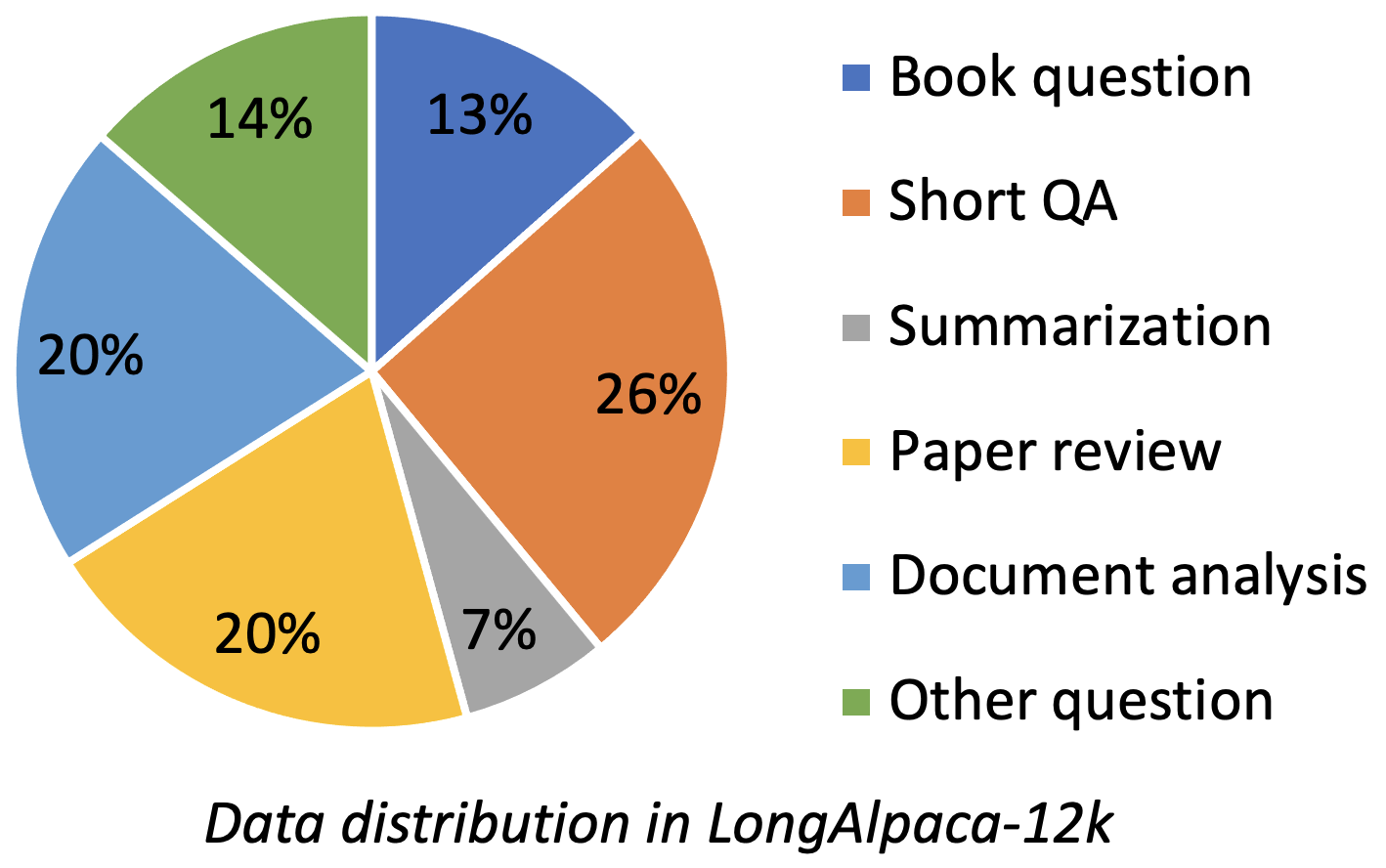
Longalpaca-12K содержит данные QA длиной 9K, которые мы собрали, и 3K короткий QA, отобранные из исходных данных Alpaca. Это значит избежать того, что модель может ухудшиться при короткой инструкции. Данные, которые мы собираем, содержат различные типы и суммы в качестве следующего рисунка.
| Данные | Короткий QA | Длинный QA | Общий | Скачать |
|---|---|---|---|---|
| Longalpaca-12K | 3K | 9K | 12K | Связь |
После исходного формата Alpaca наши длинные данные QA используют следующие подсказки для точной настройки:
instruction : str , описывает задачу, которую должна выполнять модель. Например, чтобы ответить на вопрос после прочтения раздела книги или бумаги. Мы различаем содержание и вопросы, чтобы сделать инструкции разнообразными.output : str , ответ на инструкцию. Мы не использовали input формат в формате альпаки для простоты.
| Модель | Размер | Контекст | Тренироваться | Связь |
|---|---|---|---|---|
| Longalpaca-7b | 7b | 32768 | Полный фут | Модель |
| Longalpaca-13b | 13b | 32768 | Полный фут | Модель |
| Longalpaca-70b | 70b | 32768 | Лора+ | Модель (Lora-Weight) |
| Модель | Размер | Контекст | Тренироваться | Связь |
|---|---|---|---|---|
| Llama-2-7b-longlora-8k-ft | 7b | 8192 | Полный фут | Модель |
| Llama-2-7b-longlora-16k-ft | 7b | 16384 | Полный фут | Модель |
| Llama-2-7b-longlora-32k-ft | 7b | 32768 | Полный фут | Модель |
| Llama-2-7b-longlora-100K-FT | 7b | 100000 | Полный фут | Модель |
| Llama-2-13b-longlora-8k-ft | 13b | 8192 | Полный фут | Модель |
| Llama-2-13b-longlora-16k-ft | 13b | 16384 | Полный фут | Модель |
| Llama-2-13B-Longlora-32K-FT | 13b | 32768 | Полный фут | Модель |
| Модель | Размер | Контекст | Тренироваться | Связь |
|---|---|---|---|---|
| Лама-2-7B-Лонглор-8K | 7b | 8192 | Лора+ | Лора-Вейт |
| Лама-2-7B-Лонглор-16K | 7b | 16384 | Лора+ | Лора-Вейт |
| Лама-2-7B-Лонглор-32K | 7b | 32768 | Лора+ | Лора-Вейт |
| Лама-2-13B-Лонглор-8K | 13b | 8192 | Лора+ | Лора-Вейт |
| Лама-2-13B-Лонглор-16K | 13b | 16384 | Лора+ | Лора-Вейт |
| Llama-2-13b-longlora-32K | 13b | 32768 | Лора+ | Лора-Вейт |
| Llama-2-13b-longlora-64K | 13b | 65536 | Лора+ | Лора-Вейт |
| Llama-2-70b-longlora-32K | 70b | 32768 | Лора+ | Лора-Вейт |
| Лама-2-70B-чат-лонгалор-32K | 70b | 32768 | Лора+ | Лора-Вейт |
Мы используем модели Llama2 в качестве предварительно обученных весов и настраивать их к длинным контекстам окна. Скачать на основе вашего выбора.
| Предварительно обученные веса |
|---|
| Лама-2-7B-HF |
| Лама-2-13B-HF |
| Лама-2-70B-HF |
| Llama-2-7b-Chat-HF |
| Лама-2-13B-чат-Х.Ф. |
| Лама-2-70B-чат-Х.Ф. |
Этот проект также поддерживает модели GPTNEOX в качестве базовой архитектуры модели. Некоторые кандидаты, предварительно обученные весами, могут включать GPT-Neox-20B, PolyGlot-KO-128B и другие варианты.
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf , path_to_saving_checkpoints , path_to_cache в ваш собственный каталог.model_max_length на другие значения.ds_configs/stage2.json на ds_configs/stage3.json если хотите.use_flash_attn как False , если вы используете машины V100 или не устанавливаете внимания Flash.low_rank_training как False , если вы хотите использовать полностью тонкую настройку. Это будет стоить дороже памяти GPU и медленнее, но производительность будет немного лучше. cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
Обратите внимание, что PATH_TO_SAVER_CHECKPOINTS может быть каталогом Global_step, который зависит от версий DeepSpeed.
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
При обучении с низким уровнем ранга мы устанавливаем слои встраивания и нормализации как обучаемые. Пожалуйста, используйте следующую строку, чтобы извлечь обучаемые веса trainable_params.bin из pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
Объедините веса LORA pytorch_model.bin и обучаемые параметры trainable_params.bin , сохраните полученную модель в желаемом пути в формате обнимающего лица:
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
Например,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
Чтобы оценить модель, которая обучается в настройке с низким уровнем ранга, пожалуйста, установите как base_model , так и peft_model . base_model -это предварительно обученный вес. peft_model - это путь к сохраненной контрольной точке, которая должна содержать trainable_params.bin , adapter_model.bin и adapter_config.json . Например,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Или оценить с несколькими графическими процессорами следующим образом.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Чтобы оценить модель, которая полностью настраивается, вам нужно только установить base_model в качестве пути к сохраненной контрольной точке, которая должна содержать pytorch_model.bin и config.json . peft_model следует игнорировать.
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Или оценить с несколькими графическими процессорами следующим образом.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Обратите внимание, что --seq_len , чтобы установить длину последовательности для оценки. --context_size -это установить длину контекста модели во время точной настройки. --seq_len не должен быть больше, чем --context_size .
Мы уже направили валидацию и тесты на набор данных PG19 и наборы Proof-Pile в pg19/validation.bin , pg19/test.bin и proof-pile/test_sampled_data.bin , с токенизатором LLAMA. proof-pile/test_sampled_data.bin содержит 128 документов, которые случайным образом отображаются из общего раскола тестов с достопримечательностью. Для каждого документа он имеет не менее 32768 жетонов. Мы также выпускаем отобранные идентификаторы в Proof-Pile/test_sampled_ids.bin. Вы можете скачать их по ссылкам ниже.
| Набор данных | Расколоть | Связь |
|---|---|---|
| PG19 | валидация | pg19/velyation.bin |
| PG19 | тест | pg19/test.bin |
| Доказычная | тест | Proof-Pile/test_sampled_data.bin |
Мы предоставляем способ проверить точность поиска PassKey. Например,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size -это длина контекста во время точной настройки.max_tokens - максимальная длина для документа в оценке поиска PassKey.interval - это интервал во время увеличения длины документа. Это грубое число, потому что документ увеличивается по предложениям. Пообщаться с моделями Longalpaca,
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
Чтобы задать вопрос, связанный с книгой:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
Чтобы задать вопрос, связанный с статьей:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
Чтобы развернуть свой собственный демонстрационный запуск
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
Пример
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True сделает поколение медленным, но сохраняет много памяти графического процессора. Мы поддерживаем вывод моделей Longalpaca с Streamingllm. Это увеличивает длину контекста многоуровневого диалога в Streamingllm. Вот пример,
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath - это файл JSON, который содержит подсказки для вывода. Мы предоставляем пример файла outputs_stream.json, который представляет собой подмножество Longalpaca-12K. Вы можете заменить его на свои собственные вопросы. Во время нашей коллекции наборов данных мы конвертируем бумаги и книги из PDF в текст. Качество конверсии оказывает большое влияние на качество окончательного модели. Мы думаем, что этот шаг нетривилен. Мы выпускаем инструмент для преобразования PDF2TXT, в папке pdf2txt . Он построен на pdf2image , easyocr , ditod и detectron2 . Пожалуйста, обратитесь к readme.md в pdf2txt для получения более подробной информации.







Если вы найдете этот проект полезным в своем исследовании, рассмотрите возможность ссылаться:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


