LongLoRA
1.0.0
LONGLORA: Ajuste fino eficiente de modelos de linguagem grande de longo contexto [papel]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, Jiaya Jia
Requirements e as seções Installation and Quick Guide abaixo.Para baixar e usar os pesos pré-treinados de que você precisará:
Para instalar e executar o aplicativo:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
LongalPaca-12K contém dados de qa de 9k de longa duração que coletamos e 3K curto de controle de qualidade amostrados dos dados originais da ALPACA. Isso evita o caso que o modelo pode degradar -se com instruções curtas a seguir. Os dados que coletamos contêm vários tipos e quantidades como a figura a seguir.
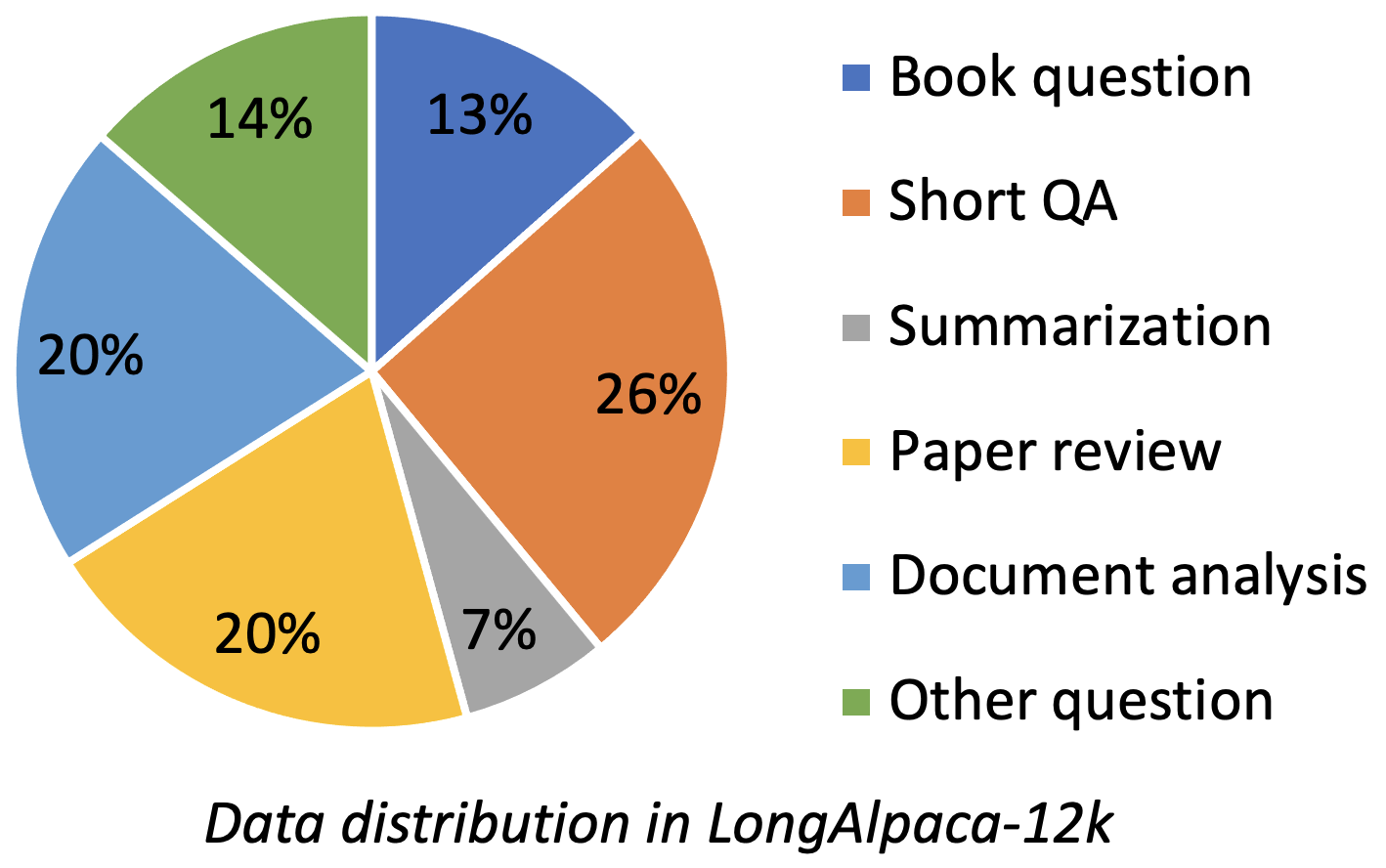
| Dados | QA curto | Qa longo | Total | Download |
|---|---|---|---|---|
| Longalpaca-12k | 3k | 9K | 12k | Link |
Após o formato Alpaca original, nossos dados de controle de qualidade longos usam os seguintes prompts para ajustar fino:
instruction : str , descreve a tarefa que o modelo deve executar. Por exemplo, para responder a uma pergunta depois de ler uma seção ou papel de livro. Variavamos o conteúdo e as perguntas para tornar as instruções diversas.output : str , a resposta para a instrução. Não usamos o formato input no formato Alpaca para simplificar.
| Modelo | Tamanho | Contexto | Trem | Link |
|---|---|---|---|---|
| Longalpaca-7b | 7b | 32768 | Ft completo | Modelo |
| Longalpaca-13b | 13b | 32768 | Ft completo | Modelo |
| Longalpaca-70b | 70B | 32768 | Lora+ | Modelo (Lora-Weight) |
| Modelo | Tamanho | Contexto | Trem | Link |
|---|---|---|---|---|
| LLAMA-2-7B-LONGLORA-8K-FT | 7b | 8192 | Ft completo | Modelo |
| LLAMA-2-7B-LONGLORA-16K-FT | 7b | 16384 | Ft completo | Modelo |
| LLAMA-2-7B-LONGLORA-32K-FT | 7b | 32768 | Ft completo | Modelo |
| LLAMA-2-7B-LONGLORA-100K-FT | 7b | 100000 | Ft completo | Modelo |
| LLAMA-2-13B-LONGLORA-8K-FT | 13b | 8192 | Ft completo | Modelo |
| LLAMA-2-13B-LONGLORA-16K-FT | 13b | 16384 | Ft completo | Modelo |
| LLAMA-2-13B-LONGLORA-32K-FT | 13b | 32768 | Ft completo | Modelo |
| Modelo | Tamanho | Contexto | Trem | Link |
|---|---|---|---|---|
| LLAMA-2-7B-LONGLORA-8K | 7b | 8192 | Lora+ | Lora-peso |
| LLAMA-2-7B-LONGLORA-16K | 7b | 16384 | Lora+ | Lora-peso |
| LLAMA-2-7B-LONGLORA-32K | 7b | 32768 | Lora+ | Lora-peso |
| LLAMA-2-13B-LONGLORA-8K | 13b | 8192 | Lora+ | Lora-peso |
| LLAMA-2-13B-LONGLORA-16K | 13b | 16384 | Lora+ | Lora-peso |
| LLAMA-2-13B-LONGLORA-32K | 13b | 32768 | Lora+ | Lora-peso |
| LLAMA-2-13B-LONGLORA-64K | 13b | 65536 | Lora+ | Lora-peso |
| LLAMA-2-70B-LONGLORA-32K | 70B | 32768 | Lora+ | Lora-peso |
| Llama-2-70b-chat-longlora-32k | 70B | 32768 | Lora+ | Lora-peso |
Usamos os modelos LLAMA2 como pesos pré-treinados e os ajustamos para tamanhos de janelas de contexto longo. Download com base em suas escolhas.
| Pesos pré-treinados |
|---|
| LLAMA-2-7B-HF |
| LLAMA-2-13B-HF |
| LLAMA-2-70B-HF |
| LLAMA-2-7B-CHAT-HF |
| Lhama-2-13b-chat-hf |
| Llama-2-70b-chat-hf |
Este projeto também suporta os modelos GPTNeox como a arquitetura do modelo básico. Alguns pesos pré-treinados candidatos podem incluir GPT-Neox-20B, Polyglot-Ko-12.8b e outras variantes.
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf , path_to_saving_checkpoints , path_to_cache para o seu próprio diretório.model_max_length para outros valores.ds_configs/stage2.json para ds_configs/stage3.json se quiser.use_flash_attn como False se você usar máquinas V100 ou não instalar a atenção do flash.low_rank_training como False se quiser usar o ajuste totalmente fino. Custará mais memória da GPU e mais lenta, mas o desempenho será um pouco melhor. cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
Observe que o PATH_TO_SAVE_CHECCETS pode ser o diretório global_Step, que depende das versões DeepSpeed.
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
No treinamento de baixo rank, definimos camadas de incorporação e normalização como treináveis. Por favor, use a seguinte linha para extrair os pesos treináveis trainable_params.bin de pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
Mesclar os pesos lora de pytorch_model.bin e parâmetros treináveis trainable_params.bin , salve o modelo resultante no caminho desejado no formato da face abraçadora:
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
Por exemplo,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
Para avaliar um modelo que é treinado na configuração de baixo rank, defina base_model e peft_model . base_model é o peso pré-treinado. peft_model é o caminho para o ponto de verificação salvo, que deve conter trainable_params.bin , adapter_model.bin e adapter_config.json . Por exemplo,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Ou avaliar com várias GPUs da seguinte maneira.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Para avaliar um modelo totalmente ajustado, você só precisa definir base_model como o caminho para o ponto de verificação salvo, que deve conter pytorch_model.bin e config.json . peft_model deve ser ignorado.
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Ou avaliar com várias GPUs da seguinte maneira.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Observe que --seq_len deve definir o comprimento da sequência para avaliação. --context_size é definir o comprimento do contexto do modelo durante o ajuste fino. --seq_len não deve ser maior que --context_size .
Já tocamos as divisões de validação e teste do conjunto de dados PG19 e PROV-PILE em pg19/validation.bin , pg19/test.bin e proof-pile/test_sampled_data.bin , com o tokenizer do LLAMA. proof-pile/test_sampled_data.bin contém 128 documentos que são amostrados aleatoriamente a partir da divisão de teste total da pilha de prova. Para cada documento, ele possui pelo menos 32768 tokens. Também lançamos os IDs amostrados no Proof-Pile/test_sampled_ids.bin. Você pode baixá -los nos links abaixo.
| Conjunto de dados | Dividir | Link |
|---|---|---|
| PG19 | validação | pg19/validation.bin |
| PG19 | teste | pg19/test.bin |
| Prova de prova | teste | Prova-PILE/TEST_SAMPLED_DATA.BIN |
Fornecemos uma maneira de testar a precisão da recuperação da Passkey. Por exemplo,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size é o comprimento do contexto durante o ajuste fino.max_tokens é o comprimento máximo para o documento na avaliação de recuperação da Passkey.interval é o intervalo durante o comprimento do documento. É um número difícil porque o documento aumenta por frases. Para conversar com os modelos Longalpaca,
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
Para fazer uma pergunta relacionada a um livro:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
Para fazer uma pergunta relacionada a um artigo:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
Para implantar sua própria demonstração
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
Exemplo
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True tornará a geração lenta, mas economize muita memória da GPU. Apoiamos a inferência de modelos Longalpaca com Streamingllm. Isso aumenta o comprimento do contexto do diálogo de várias rodadas no Streamingllm. Aqui está um exemplo,
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath é o arquivo json que contém prompts para inferência. Fornecemos um exemplo de arquivo saídas_stream.json, que é um subconjunto de longalpaca-12k. Você pode substituí -lo por suas próprias perguntas. Durante nossa coleção de dados, convertemos papel e livros de PDF em texto. A qualidade da conversão tem uma grande influência na qualidade do modelo final. Achamos que essa etapa não é trivial. Lançamos a ferramenta para a conversão PDF2TXT, na pasta pdf2txt . Ele é construído sobre pdf2image , easyocr , ditod e detectron2 . Consulte o readme.md no pdf2txt para obter mais detalhes.







Se você achar este projeto útil em sua pesquisa, considere citar:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


