LongLoRA
1.0.0
Longlora: Effiziente Feinabstimmung von Langkontext-Großsprachenmodellen [Papier]
Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Lied Han, Jiaya Jia
Requirements als Installation and Quick Guide unten.Um die vorgebreiteten Gewichte herunterzuladen und zu verwenden, werden Sie benötigen:
Um die Anwendung zu installieren und auszuführen:
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
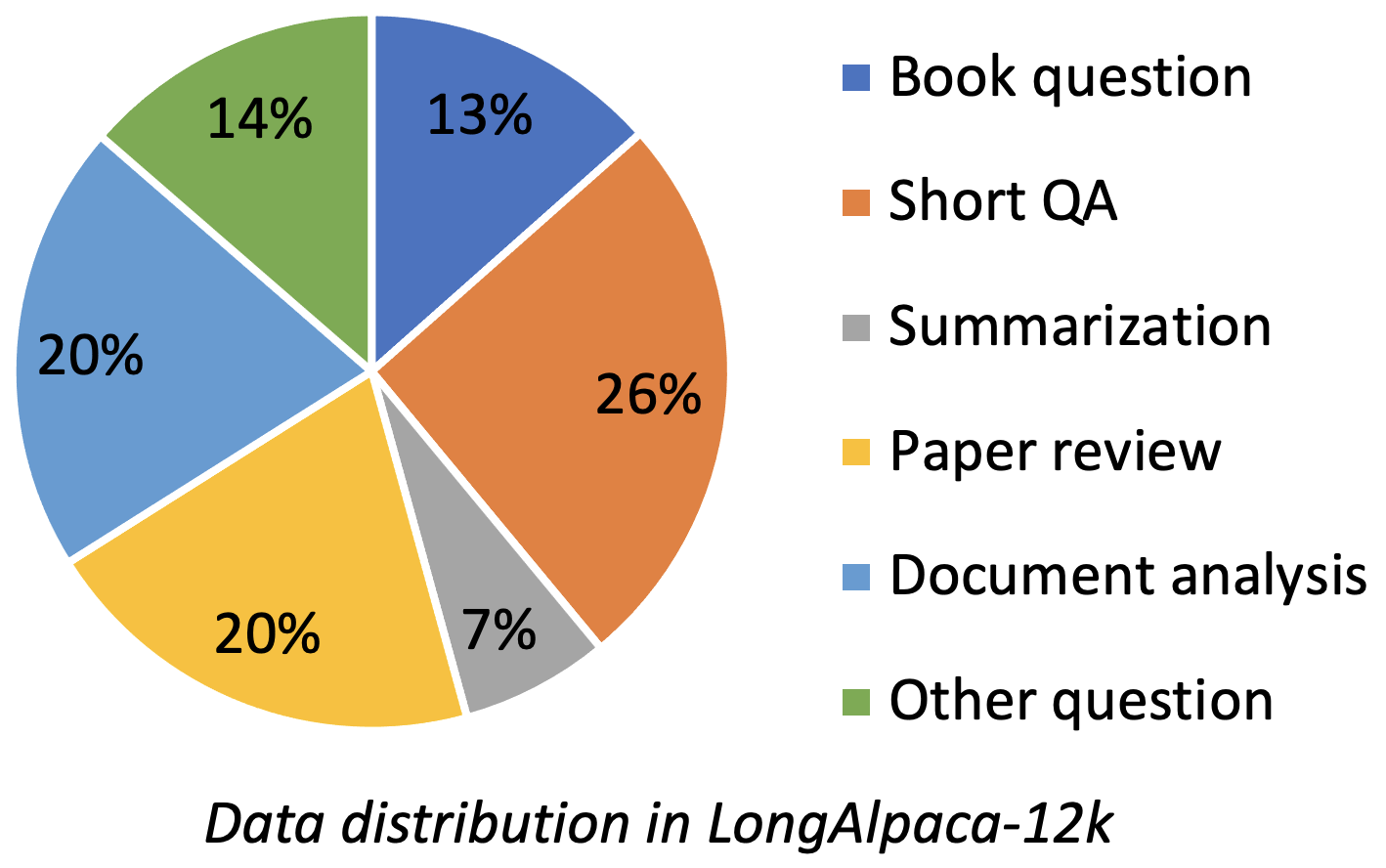
Longalpaca-12K enthält 9K-Long-QA-Daten, die wir gesammelt haben und die 3K-kurze QA aus den ursprünglichen Alpaka-Daten abgetastet wurden. Dies soll den Fall vermeiden, dass sich das Modell bei kurzen Anweisungen degradieren kann. Die Daten, die wir sammeln, enthält verschiedene Typen und Mengen als folgende Abbildung.
| Daten | Kurze QA | Lange QA | Gesamt | Herunterladen |
|---|---|---|---|---|
| Longalpaca-12k | 3k | 9k | 12k | Link |
Nach dem ursprünglichen Alpaka-Format verwenden unsere Long QA-Daten die folgenden Eingabeaufforderungen für die Feinabstimmung:
instruction : str , beschreibt die Aufgabe, die das Modell ausführen sollte. Zum Beispiel, um eine Frage nach dem Lesen eines Buchabschnitts oder Papiers zu beantworten. Wir variieren den Inhalt und die Fragen, um die Anweisungen unterschiedlich zu gestalten.output : str , die Antwort auf die Anweisung. Wir haben das input im Alpaka -Format für den Einfachheit halber nicht verwendet.
| Modell | Größe | Kontext | Zug | Link |
|---|---|---|---|---|
| Longalpaca-7b | 7b | 32768 | Volle ft | Modell |
| Longalpaca-13b | 13b | 32768 | Volle ft | Modell |
| Longalpaca-70b | 70b | 32768 | Lora+ | Modell (Lora-Gewicht) |
| Modell | Größe | Kontext | Zug | Link |
|---|---|---|---|---|
| LAMA-2-7B-Longlora-8K-ft | 7b | 8192 | Volle ft | Modell |
| LAMA-2-7B-Longlora-16K-ft | 7b | 16384 | Volle ft | Modell |
| LAMA-2-7B-Longlora-32K-ft | 7b | 32768 | Volle ft | Modell |
| LAMA-2-7B-Longlora-100K-ft | 7b | 100000 | Volle ft | Modell |
| LAMA-2-13B-Longlora-8K-ft | 13b | 8192 | Volle ft | Modell |
| LAMA-2-13B-Longlora-16K-ft | 13b | 16384 | Volle ft | Modell |
| LAMA-2-13B-Longlora-32K-ft | 13b | 32768 | Volle ft | Modell |
| Modell | Größe | Kontext | Zug | Link |
|---|---|---|---|---|
| LAMA-2-7B-Longlora-8K | 7b | 8192 | Lora+ | Lora-Gewicht |
| LAMA-2-7B-Longlora-16K | 7b | 16384 | Lora+ | Lora-Gewicht |
| LAMA-2-7B-Longlora-32k | 7b | 32768 | Lora+ | Lora-Gewicht |
| LAMA-2-13B-LONGLORA-8K | 13b | 8192 | Lora+ | Lora-Gewicht |
| LAMA-2-13B-LONGLORA-16K | 13b | 16384 | Lora+ | Lora-Gewicht |
| LAMA-2-13B-LONGLORA-32K | 13b | 32768 | Lora+ | Lora-Gewicht |
| LAMA-2-13B-LONGLORA-64K | 13b | 65536 | Lora+ | Lora-Gewicht |
| LAMA-2-70B-Longlora-32K | 70b | 32768 | Lora+ | Lora-Gewicht |
| LLAMA-2-70B-CHAT-LONGLORA-32K | 70b | 32768 | Lora+ | Lora-Gewicht |
Wir verwenden LLAMA2-Modelle als vorgebreitete Gewichte und feinstimmen sie auf lange Kontextfenstergrößen. Laden Sie basierend auf Ihren Auswahlmöglichkeiten herunter.
| Vorgeborene Gewichte |
|---|
| LAMA-2-7B-HF |
| LAMA-2-13B-HF |
| LAMA-2-70B-HF |
| LAMA-2-7B-CHAT-HF |
| LAMA-2-13B-CHAT-HF |
| LAMA-2-70B-CHAT-HF |
Dieses Projekt unterstützt auch GPTNEOX -Modelle als Basismodellarchitektur. Einige vorgeborene Kandidaten können GPT-NEOX-20B, Polyglot-KO-2.8b und andere Varianten umfassen.
torchrun --nproc_per_node=8 fine-tune.py
--model_name_or_path path_to/Llama-2-7b-hf
--bf16 True
--output_dir path_to_saving_checkpoints
--cache_dir path_to_cache
--model_max_length 8192
--use_flash_attn True
--low_rank_training False
--num_train_epochs 1
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 1000
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
--max_steps 1000
path_to/Llama-2-7b-hf , path_to_saving_checkpoints , path_to_cache in Ihr eigenes Verzeichnis zu ändern.model_max_length in andere Werte ändern können.ds_configs/stage2.json in ds_configs/stage3.json ändern, wenn Sie möchten.use_flash_attn als False fest, wenn Sie V100 -Maschinen verwenden oder die Aufmerksamkeit der Flash nicht installieren.low_rank_training als False einstellen, wenn Sie eine vollständige Einstellung verwenden möchten. Es wird mehr GPU -Speicher und langsamer kosten, aber die Leistung wird etwas besser sein. cd path_to_saving_checkpoints && python zero_to_fp32.py . pytorch_model.bin
Beachten Sie, dass das path_to_saving_checkpoints das global_step -Verzeichnis sein könnte, das von den Deepspeed -Versionen abhängt.
torchrun --nproc_per_node=8 supervised-fine-tune.py
--model_name_or_path path_to_Llama2_chat_models
--bf16 True
--output_dir path_to_saving_checkpoints
--model_max_length 16384
--use_flash_attn True
--data_path LongAlpaca-16k-length.json
--low_rank_training True
--num_train_epochs 5
--per_device_train_batch_size 1
--per_device_eval_batch_size 2
--gradient_accumulation_steps 8
--evaluation_strategy "no"
--save_strategy "steps"
--save_steps 98
--save_total_limit 2
--learning_rate 2e-5
--weight_decay 0.0
--warmup_steps 20
--lr_scheduler_type "constant_with_warmup"
--logging_steps 1
--deepspeed "ds_configs/stage2.json"
--tf32 True
Im niedrigen Training setzen wir Einbettung und Normalisierungsschichten als trainierbar. Bitte verwenden Sie die folgende Linie, um die trainierbaren Gewichte zu extrahieren trainable_params.bin von pytorch_model.bin
python3 get_trainable_weights.py --checkpoint_path path_to_saving_checkpoints --trainable_params "embed,norm"
Fucken Sie die Lora -Gewichte von pytorch_model.bin und trainierbaren Parametern trainable_params.bin zusammen und speichern Sie das resultierende Modell in Ihrem gewünschten Weg im umringenden Gesichtsformat:
python3 merge_lora_weights_and_save_hf_model.py
--base_model path_to/Llama-2-7b-hf
--peft_model path_to_saving_checkpoints
--context_size 8192
--save_path path_to_saving_merged_model
Zum Beispiel,
python3 merge_lora_weights_and_save_hf_model.py
--base_model /dataset/pretrained-models/Llama-2-7b-hf
--peft_model /dataset/yukangchen/hf_models/lora-models/Llama-2-7b-longlora-8k
--context_size 8192
--save_path /dataset/yukangchen/models/Llama-2-7b-longlora-8k-merged
Um ein Modell zu bewerten, das in der Einstellung mit niedrigem Rang trainiert wird, setzen Sie bitte sowohl base_model als auch peft_model . base_model ist das vorgebrachte Gewicht. peft_model ist der Pfad zum gespeicherten Checkpoint, der trainable_params.bin , adapter_model.bin und adapter_config.json enthalten sollte. Zum Beispiel,
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Oder mit mehreren GPUs wie folgt bewerten.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to/Llama-2-7b-hf --peft_model path_to_saving_checkpoints --data_path pg19/test.bin
Um ein vollständig fein abgestimmter Modell zu bewerten, müssen Sie base_model nur als Pfad zum gespeicherten Checkpoint festlegen, pytorch_model.bin und config.json enthalten sollte. peft_model sollte ignoriert werden.
python3 eval.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Oder mit mehreren GPUs wie folgt bewerten.
torchrun --nproc_per_node=auto eval_distributed.py --seq_len 8192 --context_size 8192 --batch_size 1 --base_model path_to_saving_checkpoints --data_path pg19/test.bin
Beachten Sie, dass --seq_len die Sequenzlänge für die Bewertung festlegen soll. --context_size soll die Kontextlänge des Modells während der Feinabstimmung festlegen. --seq_len sollte nicht größer sein als --context_size .
Wir haben bereits die Validierungs- und Testspaltungen von PG19- und Proof-Pile-Datensatz in pg19/validation.bin , pg19/test.bin und proof-pile/test_sampled_data.bin mit dem Tokenizer von LLAMA tokenisiert. proof-pile/test_sampled_data.bin enthält 128 Dokumente, die zufällig aus dem Total Proof-Pile-Test aufgeteilt werden. Für jedes Dokument verfügt es über mindestens 32768 Token. Wir geben auch die abgetasteten IDs in Proof-Pile/test_sampled_ids.bin frei. Sie können sie aus den folgenden Links herunterladen.
| Datensatz | Teilt | Link |
|---|---|---|
| PG19 | Validierung | PG19/Validierung.bin |
| PG19 | prüfen | pg19/test.bin |
| Proof-Pile | prüfen | Proof-Pile/test_sampled_data.bin |
Wir bieten eine Art und Weise, um die Genauigkeit der Passkey -Abruf zu testen. Zum Beispiel,
python3 passkey_retrivial.py
--context_size 32768
--base_model path_to/Llama-2-7b-longlora-32k
--max_tokens 32768
--interval 1000
context_size die Kontextlänge während der Feinabstimmung ist.max_tokens ist die maximale Länge für das Dokument in der PassKey -Abrufbewertung.interval ist das Intervall während der Dokumentlänge, die zunimmt. Es ist eine grobe Zahl, da das Dokument um Sätze zunimmt. Mit Longalpaca -Modellen zu chatten,
python3 inference.py
--base_model path_to_model
--question $question
--context_size $context_length
--max_gen_len $max_gen_len
--flash_attn True
--material $material_content
Um eine Frage zu einem Buch zu stellen:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "Why doesn't Professor Snape seem to like Harry?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/Harry Potter and the Philosophers Stone_section2.txt"
Eine Frage zu einem Papier zu stellen:
python3 inference.py
--base_model /data/models/LongAlpaca-13B
--question "What are the main contributions and novelties of this work?"
--context_size 32768
--max_gen_len 512
--flash_attn True
--material "materials/paper1.txt"
Um einen eigenen Demo -Lauf bereitzustellen
python3 demo.py
--base_model path_to_model
--context_size $context_size
--max_gen_len $max_gen_len
--flash_attn True
Beispiel
python3 demo.py
--base_model /data/models/LongAlpaca-13B
--context_size 32768
--max_gen_len 512
--flash_attn True
flash_attn=True die Generation langsamer macht, aber viel GPU -Speicher speichert. Wir unterstützen die Schlussfolgerung von Longalpaca -Modellen mit Streamingllm. Dies erhöht die Kontextlänge des mehrköpfigen Dialogs im Streamingllm. Hier ist ein Beispiel,
python run_streaming_llama_longalpaca.py
----enable_streaming
--test_filepath outputs_stream.json
--use_flash_attn True
--recent_size 32768
test_filepath ist die JSON -Datei, die Eingabeaufforderungen für Inferenz enthält. Wir bieten eine Beispieldatei-Ausgänge_Stream.json, eine Teilmenge von Longalpaca-12k. Sie können es auf Ihre eigenen Fragen ersetzen. Während unserer Datensatzsammlung konvertieren wir Papier und Bücher von PDF in Text. Die Konversionsqualität hat einen großen Einfluss auf die endgültige Modellqualität. Wir denken, dass dieser Schritt nicht trivial ist. Wir geben das Tool für die PDF2TXT -Konvertierung im Ordner pdf2txt frei. Es basiert auf pdf2image , easyocr , ditod und detectron2 . Weitere Informationen finden Sie in der Readme.md in pdf2txt .







Wenn Sie dieses Projekt in Ihrer Forschung nützlich finden, sollten Sie sich angeben:
@inproceedings{longlora,
author = {Yukang Chen and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {LongLoRA: Efficient Fine-tuning of Long-Context Large Language Models},
booktitle = {The International Conference on Learning Representations (ICLR)},
year = {2024},
}
@misc{long-alpaca,
author = {Yukang Chen and Shaozuo Yu and Shengju Qian and Haotian Tang and Xin Lai and Zhijian Liu and Song Han and Jiaya Jia},
title = {Long Alpaca: Long-context Instruction-following models},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/dvlab-research/LongLoRA}},
}


