Comprehensive E2E TTS
1.0.0
非自動入學的端到端文本到語音(生成波形給定文本),支持SOTA家族無監督的持續時間模型。該項目隨著研究界的發展而發展,旨在實現最終的E2E-TT 。歡迎對最佳端到端TT的任何建議:)
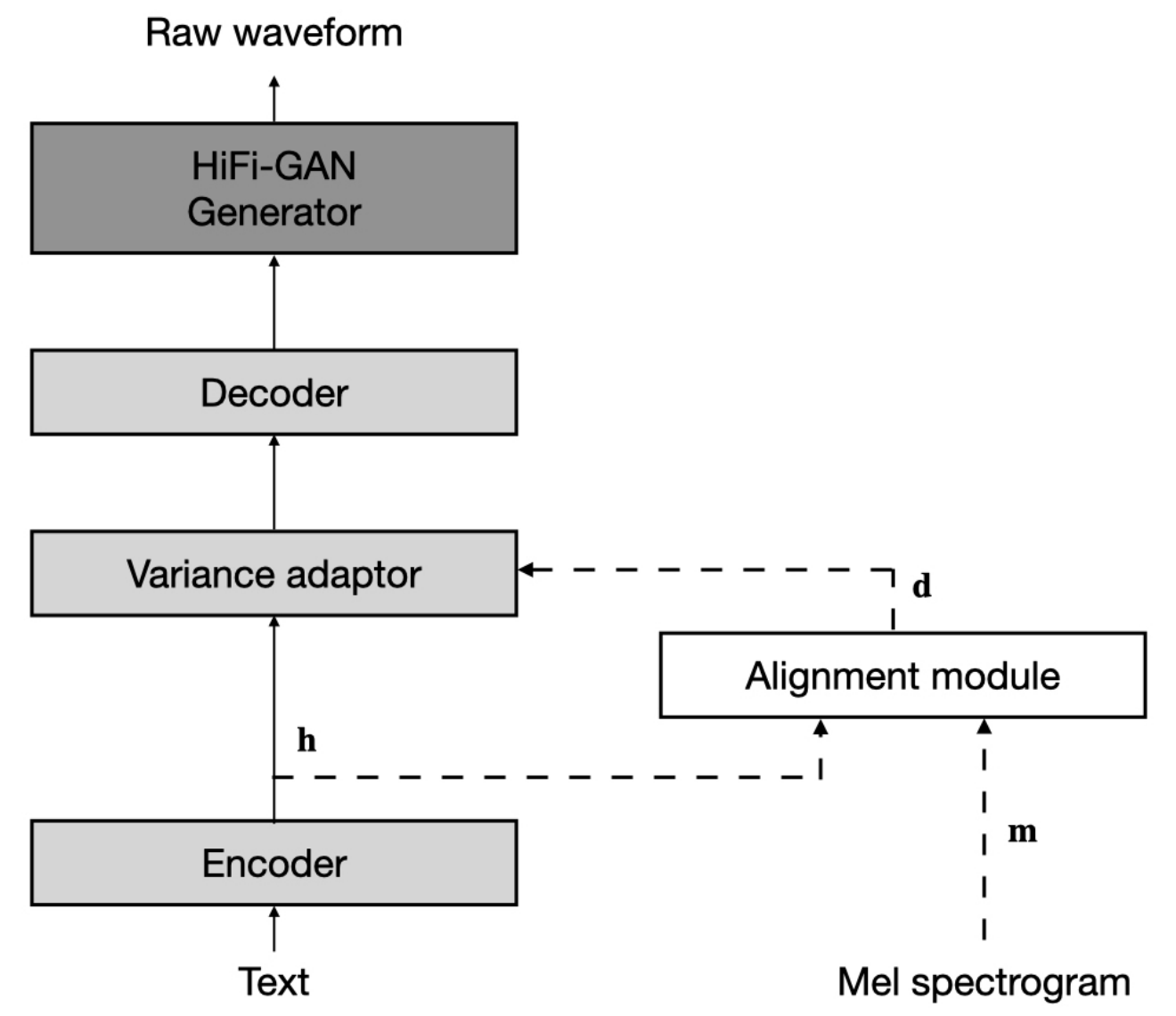
數據集在以下文檔中指的是數據集的名稱,例如LJSpeech和VCTK 。
您可以使用
pip3 install -r requirements.txt
此外,還為Docker用戶提供Dockerfile 。
您必須下載驗證的型號(將很快共享),並將其放入output/ckpt/DATASET/ 。
對於單揚聲器TTS ,運行
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
對於多演講者TTS ,運行
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
可以在preprocessed_data/DATASET/speakers.json上找到學習的揚聲器的字典,並且生成的話語將放在output/result/ 。
也支持批次推理,嘗試
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
綜合preprocessed_data/DATASET/val.txt中的所有話語。
可以通過指定所需的音高/能量/持續時間比來控制合成話語的音高/音量/口語速率。例如,一個人可以將語言率提高20%,並將數量減少20%
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
添加-speaker_id speaker_id用於多演講者tts。
支持的數據集是
在LJSpeech和VCTK之後,分別添加了單個揚聲器TTS數據集(例如,2013年暴雪挑戰)和多揚聲器TTS數據集(例如,庫)。此外,可以在此處調整您自己的語言和數據集。
./deepspeaker/pretrained_models/中。 python3 preprocess.py --dataset DATASET
培訓您的模型
python3 train.py --dataset DATASET
有用的選項:
CUDA_VISIBLE_DEVICES=<GPU_IDs> 。使用
tensorboard --logdir output/log
在您的本地主機上提供張板。
'none'和'DeepSpeaker'之間)進行切換。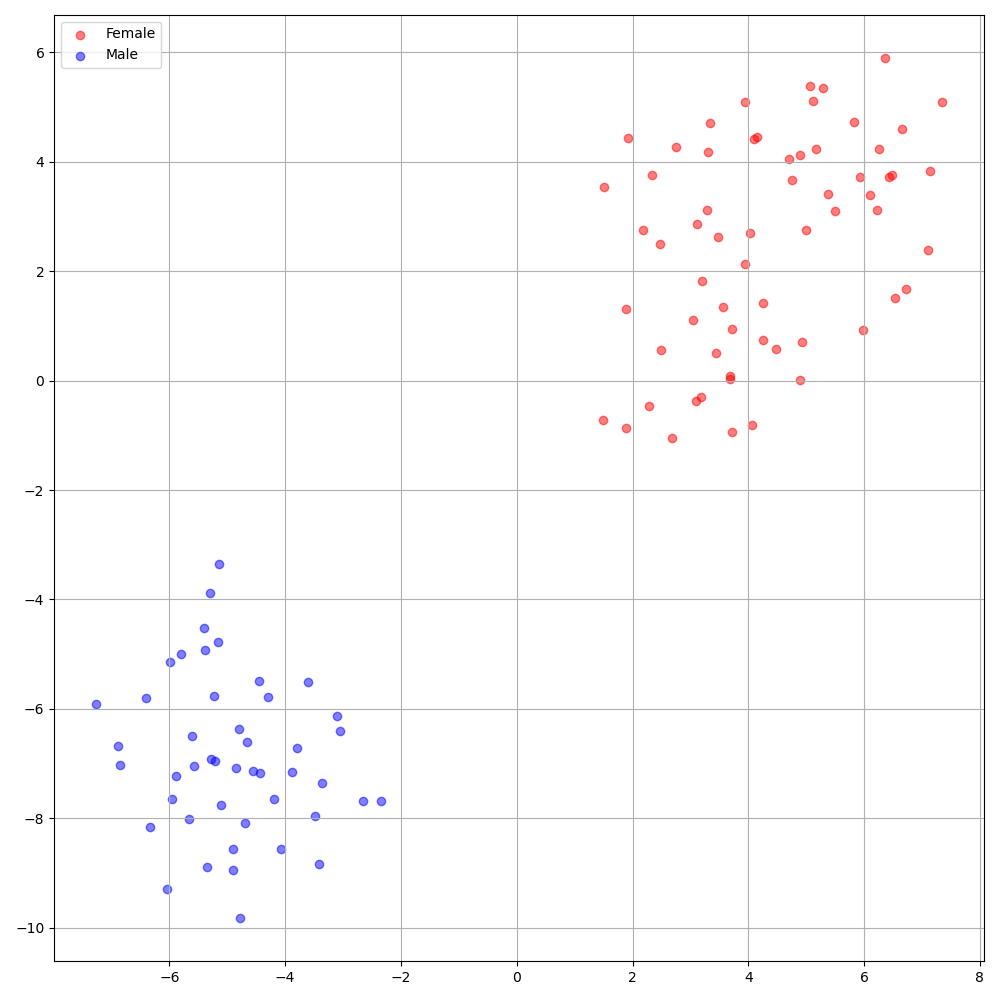
請用“引用此存儲庫”的“關於部分”(主頁的右上角)引用此存儲庫。


