Comprehensive E2E TTS
1.0.0
Un texto a discurso de extremo a voz no autorgresivo (generando forma de onda dada de texto), que respalda a una familia de modelos de duración no supervisados SOTA. Este proyecto crece con la comunidad de investigación, con el objetivo de lograr el mejor E2E-TTS . Cualquier sugerencia hacia los mejores TT de extremo a extremo es bienvenido :)
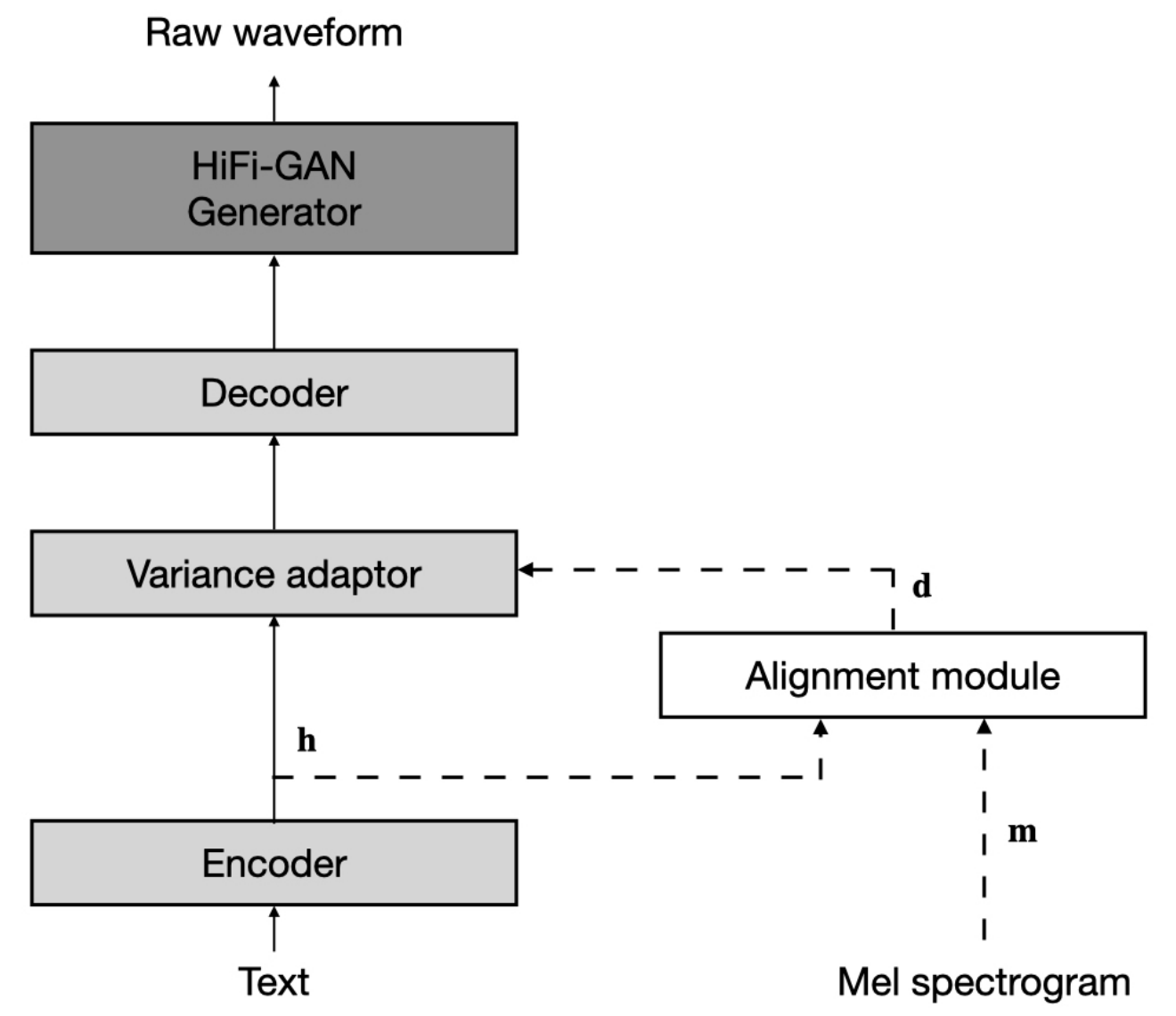
El conjunto de datos se refiere a los nombres de conjuntos de datos como LJSpeech y VCTK en los siguientes documentos.
Puede instalar las dependencias de Python con
pip3 install -r requirements.txt
Además, Dockerfile se proporciona para los usuarios Docker .
Debe descargar los modelos previos a la aparición (se compartirá pronto) y colocarlos en output/ckpt/DATASET/ .
Para un TTS de un solo hablante , ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Para un TTS de múltiples altavoces , ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
El diccionario de los altavoces aprendidos se puede encontrar en preprocessed_data/DATASET/speakers.json , y las expresiones generadas se colocarán en output/result/ .
También es compatible con la inferencia por lotes, intente
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todas las expresiones en preprocessed_data/DATASET/val.txt .
La tasa de tono/volumen/habla de las expresiones sintetizadas se puede controlar especificando las relaciones de tono/energía/duración deseadas. Por ejemplo, uno puede aumentar la tasa de habla en un 20 % y disminuir el volumen en un 20 % en
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Agregue -speaker_id stavephising_id para un TTS de múltiples altavoces.
Los conjuntos de datos compatibles son
Cualquiera de los dos conjuntos de datos TTS de un solo plato (por ejemplo, Blizzard Challenge 2013) y el conjunto de datos TTS de múltiples altavoces (por ejemplo, Libritts) se pueden agregar después de LJSpeech y VCTK, respectivamente. Además, su propio idioma y conjunto de datos se pueden adaptar siguiendo aquí.
./deepspeaker/pretrained_models/ python3 preprocess.py --dataset DATASET
Entrena tu modelo con
python3 train.py --dataset DATASET
Opciones útiles:
CUDA_VISIBLE_DEVICES=<GPU_IDs> al comienzo del comando anterior.Usar
tensorboard --logdir output/log
para servir tensorboard en su localhost.
'none' y 'DeepSpeaker' ).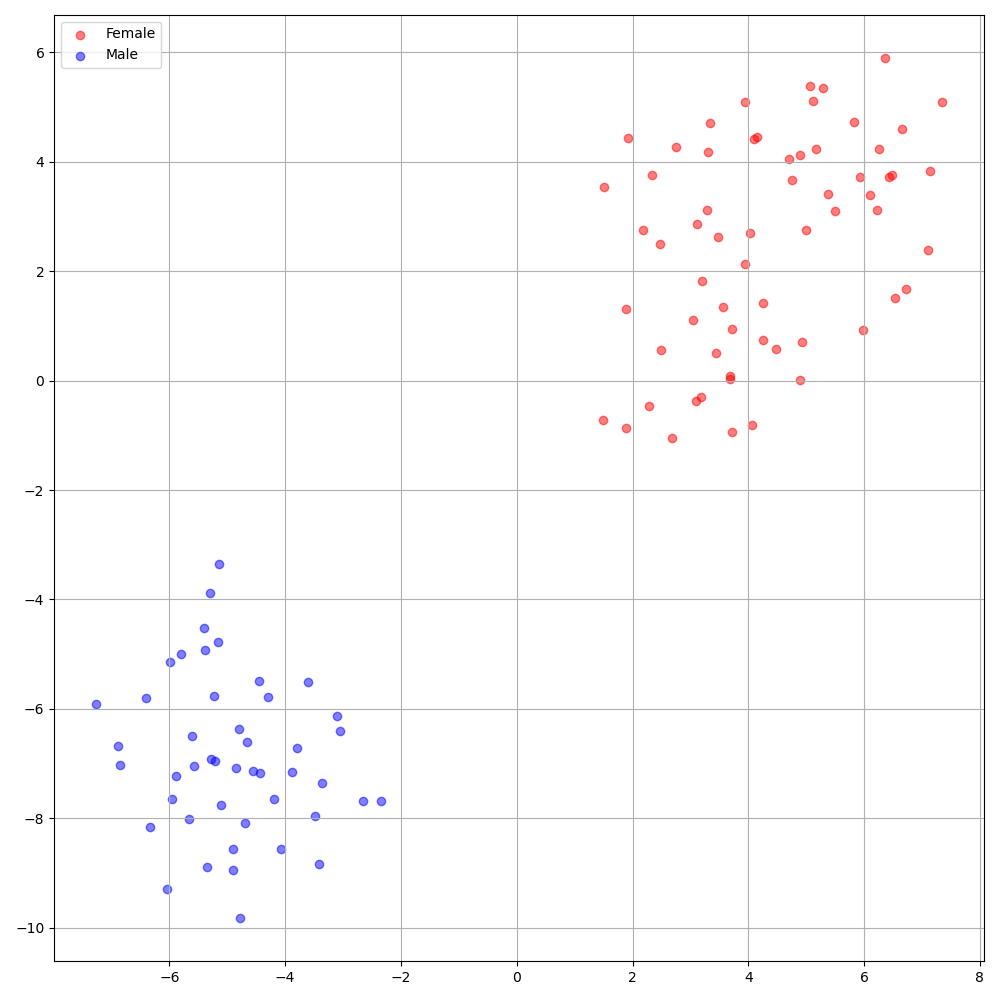
Cite este repositorio por el "cita este repositorio" de la sección Acerca de (arriba a la derecha de la página principal).


