Comprehensive E2E TTS
1.0.0
Ein nicht autoregressiver End-to-End- Text-zu-Sprache (generierende Wellenform gegebenen Text), das eine Familie von SOTA-Modellierungen für unbeaufsichtigte Dauer unterstützt. Dieses Projekt wächst mit der Forschungsgemeinschaft und zielt darauf ab, die ultimativen E2E-TTs zu erreichen . Alle Vorschläge für die besten End-to-End-TTs sind willkommen :)
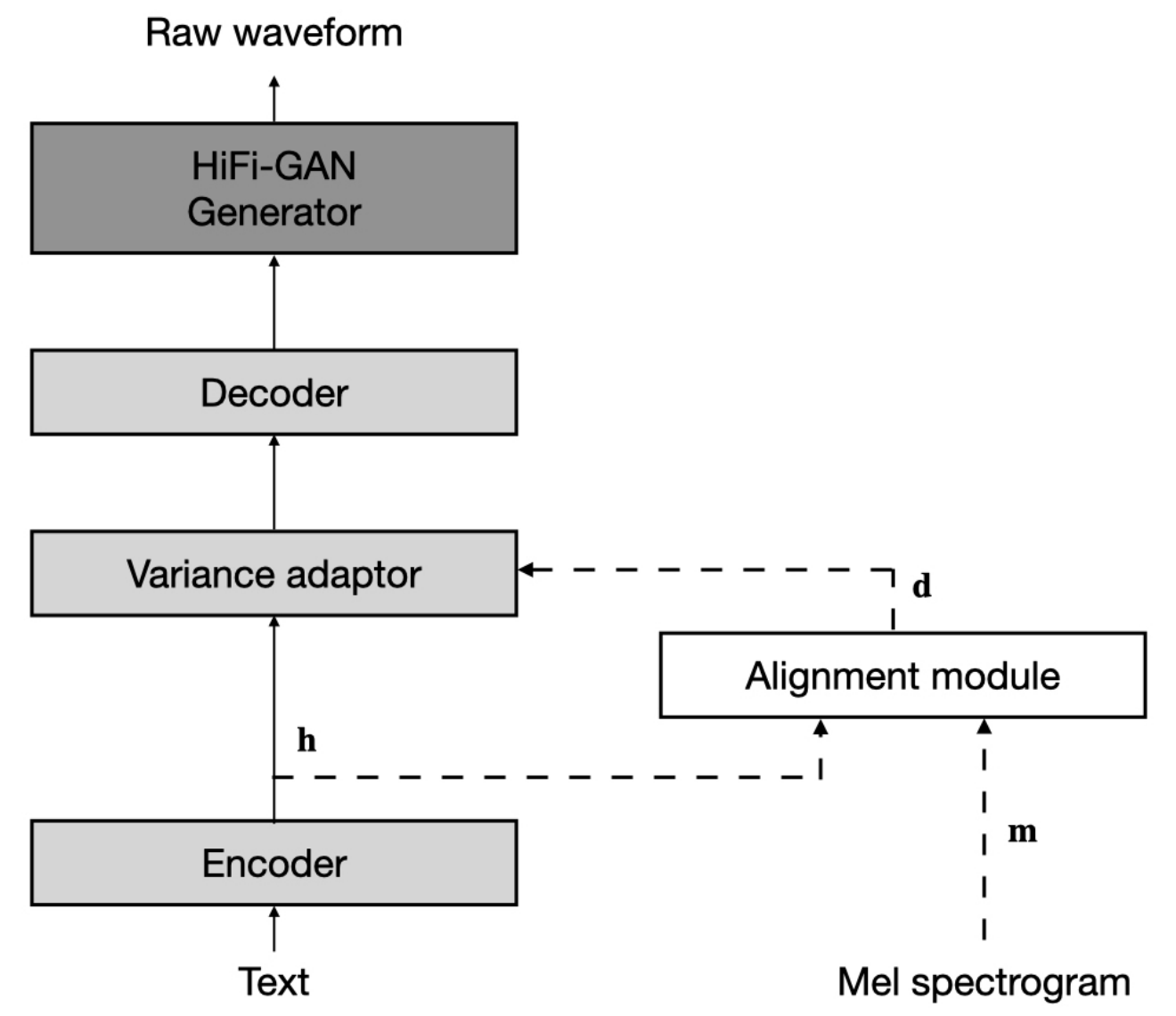
Datensatz bezieht sich auf die Namen von Datensätzen wie LJSpeech und VCTK in den folgenden Dokumenten.
Sie können die Python -Abhängigkeiten mit installieren
pip3 install -r requirements.txt
Außerdem wird Dockerfile für Docker -Benutzer bereitgestellt.
Sie müssen die vorbereiteten Modelle herunterladen (werden in Kürze freigegeben) und sie in output/ckpt/DATASET/ einsetzen.
Für einen TTS mit einem Lautsprecher laufen Sie
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Für einen Multi-Sprecher-TTS laufen
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Das Wörterbuch der gelehrten Sprecher finden Sie unter preprocessed_data/DATASET/speakers.json , und die generierten Äußerungen werden in output/result/ .
Batch -Inferenz wird ebenfalls unterstützt, versuchen Sie es
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
So synthetisieren Sie alle Äußerungen in preprocessed_data/DATASET/val.txt .
Die Tonhöhe/Volumen-/Sprechrate der synthetisierten Äußerungen kann durch Angabe der gewünschten Pitch/Energy/Dauer -Verhältnisse gesteuert werden. Zum Beispiel kann man die Sprechrate um 20 % erhöhen und das Volumen um 20 % verringern
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Fügen Sie -Speaker_id Speaker_id für ein Multi-Sprecher-TTS.
Die unterstützten Datensätze sind
Jedes der TTS-Datensatz für einsprachige TTS (z. B. Blizzard Challenge 2013) und Multi-Speaker-TTS- Datensatz (z. B. LIBLITTS) kann nach LJSpeech bzw. VCTK hinzugefügt werden. Darüber hinaus kann hier Ihre eigene Sprache und Ihr eigener Datensatz angepasst werden.
./deepspeaker/pretrained_models/ . python3 preprocess.py --dataset DATASET
Trainieren Sie Ihr Modell mit
python3 train.py --dataset DATASET
Nützliche Optionen:
CUDA_VISIBLE_DEVICES=<GPU_IDs> an.Verwenden
tensorboard --logdir output/log
Tensorboard auf Ihrem örtlichen Haus servieren.
'none' und 'DeepSpeaker' ) einstellen.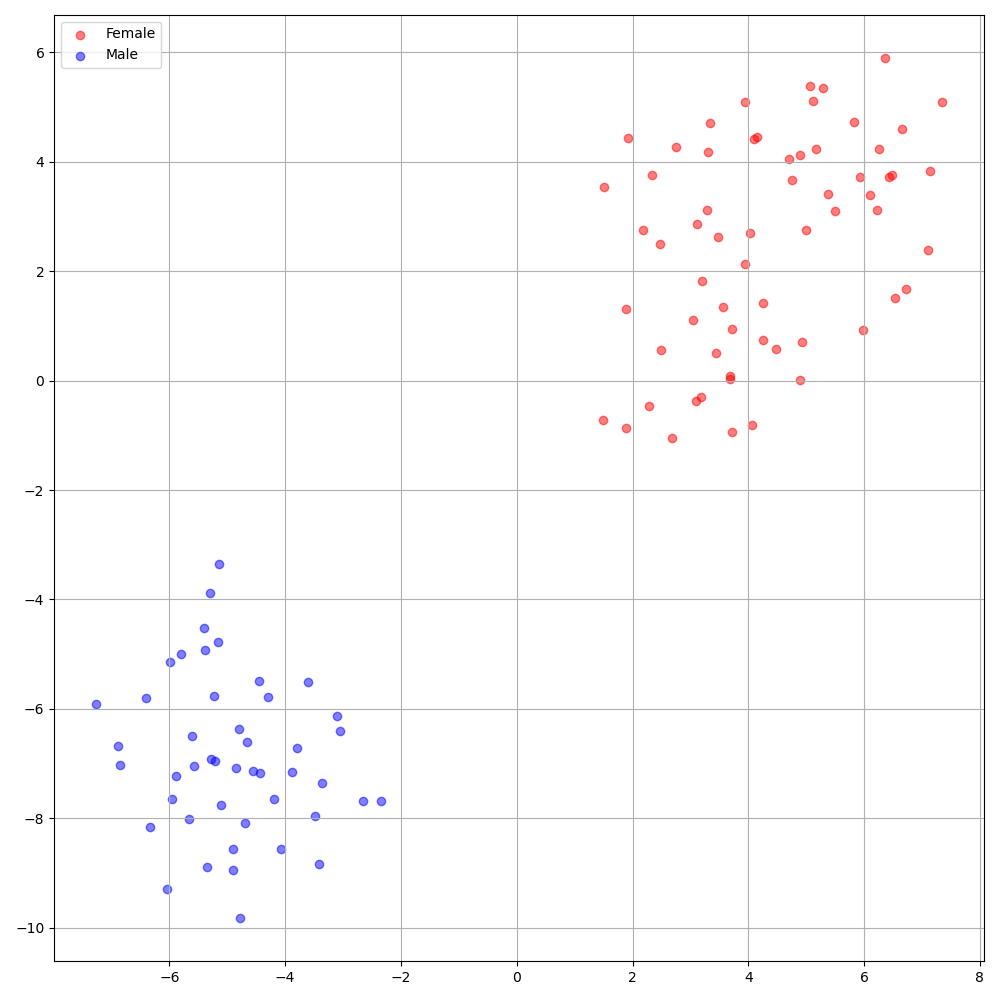
Bitte zitieren Sie dieses Repository durch das "Zitieren Sie dieses Repository" des Abschnitts (oben rechts auf der Hauptseite).


