Comprehensive E2E TTS
1.0.0
Teks ke ujung ke ujung non-ke-end -end (menghasilkan bentuk gelombang yang diberikan teks), mendukung keluarga SOTA model durasi tanpa pengawasan. Proyek ini tumbuh dengan komunitas penelitian, yang bertujuan untuk mencapai E2E-TTS terbaik . Saran apa pun menuju TTS end-to-end terbaik diterima :)
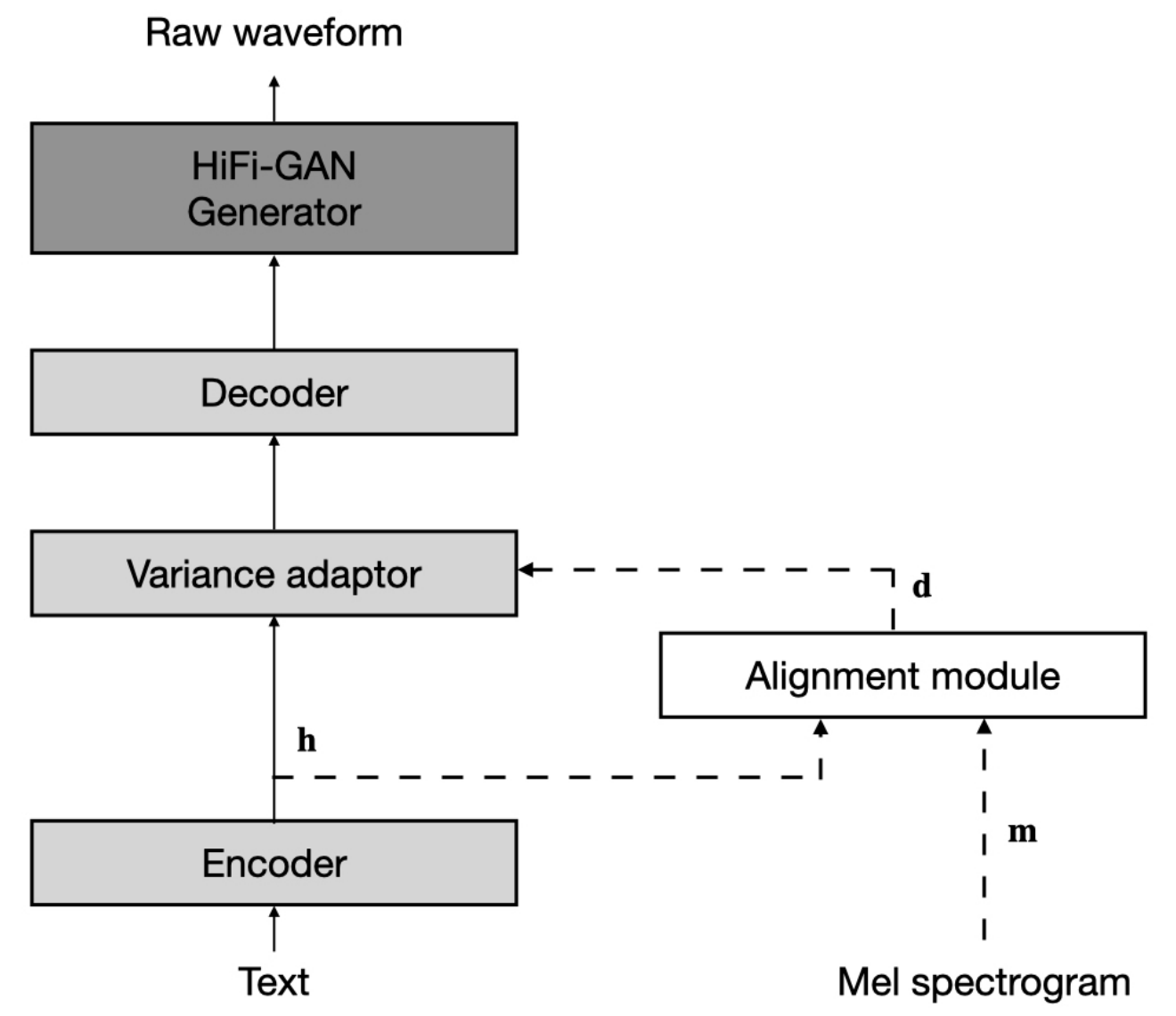
Dataset mengacu pada nama dataset seperti LJSpeech dan VCTK dalam dokumen berikut.
Anda dapat menginstal dependensi Python dengan
pip3 install -r requirements.txt
Juga, Dockerfile disediakan untuk pengguna Docker .
Anda harus mengunduh model pretrained (akan segera dibagikan) dan memasukkannya ke dalam output/ckpt/DATASET/ .
Untuk TTS penutur tunggal , jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Untuk TTS multi-speaker , jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Kamus speaker yang dipelajari dapat ditemukan di preprocessed_data/DATASET/speakers.json , dan ucapan yang dihasilkan akan dimasukkan ke dalam output/result/ .
Inferensi batch juga didukung, coba
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Untuk mensintesis semua ucapan di preprocessed_data/DATASET/val.txt .
Laju pitch/volume/berbicara dari ucapan yang disintesis dapat dikontrol dengan menentukan rasio pitch/energi/durasi yang diinginkan. Misalnya, seseorang dapat meningkatkan tingkat berbicara sebesar 20 % dan mengurangi volume sebesar 20 % dengan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Tambahkan -speaker_id speaker_id untuk TTS multi-speaker.
Dataset yang didukung adalah
Dataset TTS speaker tunggal (misalnya, Blizzard Challenge 2013) dan dataset TTS multi-speaker (misalnya, Libitts) dapat ditambahkan mengikuti LJSpeech dan VCTK, masing-masing. Selain itu, bahasa dan dataset Anda sendiri dapat diadaptasi di sini.
./deepspeaker/pretrained_models/ . python3 preprocess.py --dataset DATASET
Latih model Anda dengan
python3 train.py --dataset DATASET
Opsi yang berguna:
CUDA_VISIBLE_DEVICES=<GPU_IDs> di awal perintah di atas.Menggunakan
tensorboard --logdir output/log
untuk melayani Tensorboard di Localhost Anda.
'none' dan 'DeepSpeaker' ).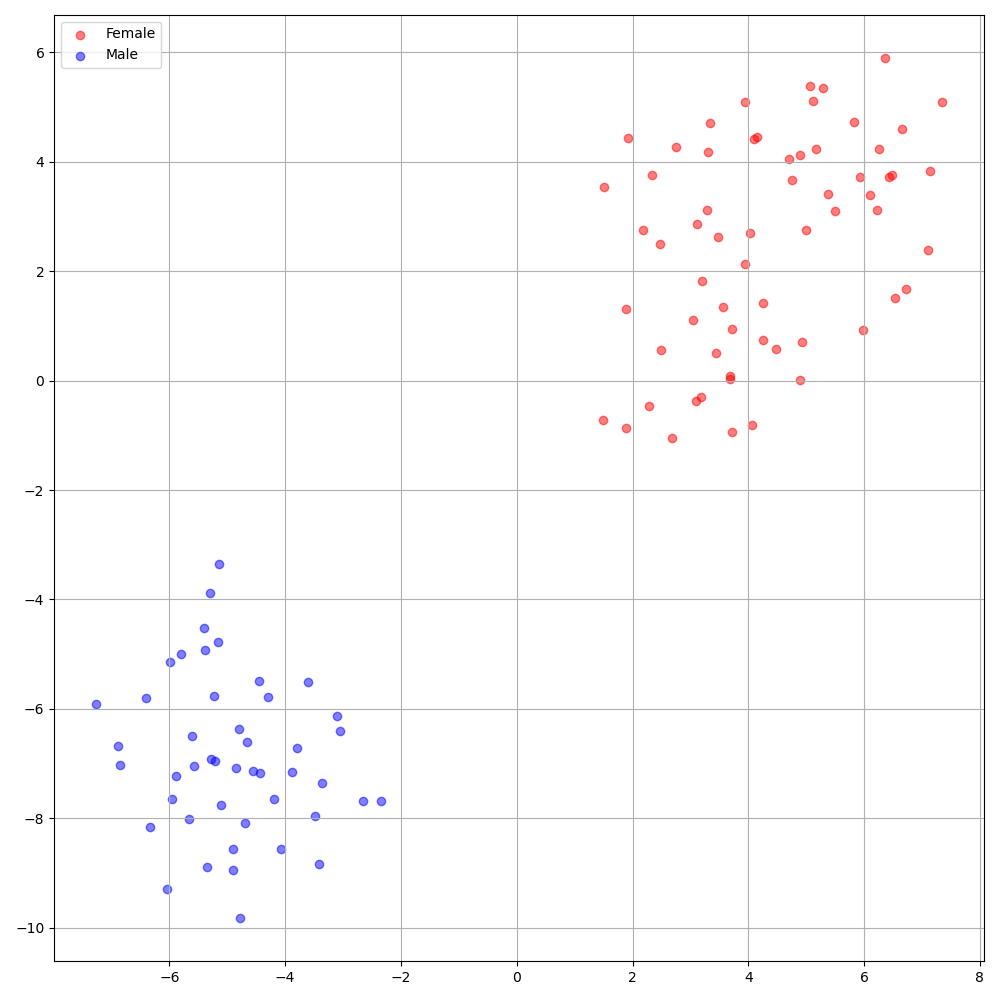
Harap kutip repositori ini dengan "CITE Repositori ini" dari bagian sekitar (kanan atas halaman utama).


