Comprehensive E2E TTS
1.0.0
비 독창적 인 엔드 투 엔드 텍스트 음성 연설 (텍스트가 주어진 파형 생성)으로 SOTA 비 감독 기간 모델링 패밀리를 지원합니다. 이 프로젝트는 궁극적 인 E2E-TT를 달성하기 위해 연구 커뮤니티와 함께 성장합니다. 최고의 엔드 투 엔드 TT에 대한 제안을 환영합니다 :)
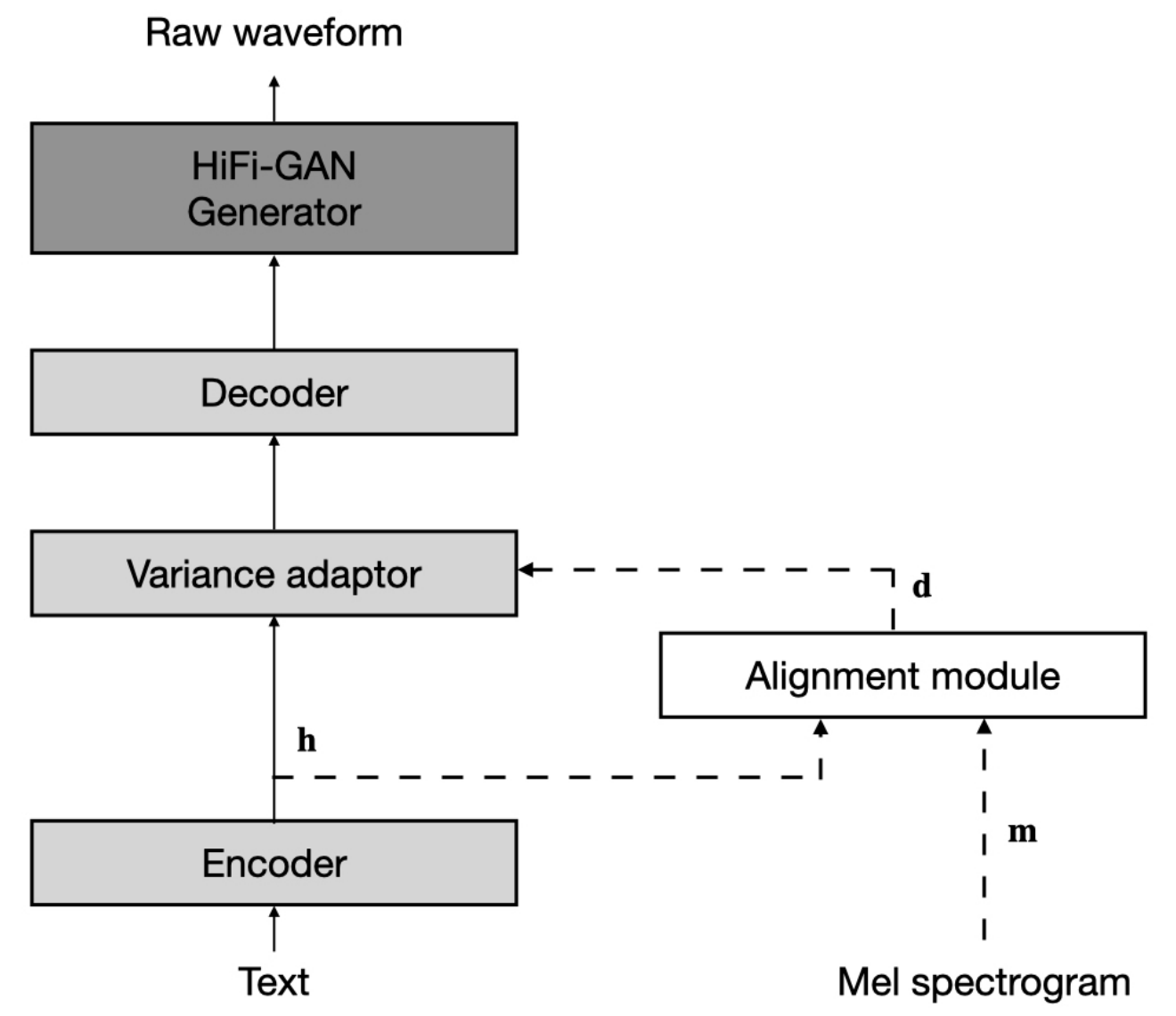
데이터 세트는 다음 문서에서 LJSpeech 및 VCTK 와 같은 데이터 세트의 이름을 나타냅니다.
파이썬 종속성을 설치할 수 있습니다
pip3 install -r requirements.txt
또한 Dockerfile Docker 사용자에게 제공됩니다.
사전 처리 된 모델 (곧 공유 될 예정)을 다운로드하고 output/ckpt/DATASET/ 에 넣어야합니다.
단일 스피커 TTS 의 경우 실행하십시오
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
멀티 스피커 TTS 의 경우 실행하십시오
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
학습 된 스피커 사전은 preprocessed_data/DATASET/speakers.json 에서 찾을 수 있으며 생성 된 발화는 output/result/ 에 넣습니다.
배치 추론도 지원됩니다
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
preprocessed_data/DATASET/val.txt 의 모든 발화를 종합합니다.
합성 된 발화의 피치/볼륨/말하기 속도는 원하는 피치/에너지/지속 시간 비율을 지정하여 제어 할 수 있습니다. 예를 들어, 말하기 속도를 20 % 증가시키고 양을 20 % 감소시킬 수 있습니다.
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
멀티 스피커 TTS에 대해 -speaker_id speaker_id를 추가하십시오.
지원되는 데이터 세트는입니다
단일 스피커 TTS 데이터 세트 (예 : Blizzard Challenge 2013) 및 Multi-Speaker TTS 데이터 세트 (예 : Libritts)는 각각 LJSpeech 및 VCTK에 따라 추가 될 수 있습니다. 또한, 자신의 언어와 데이터 세트는 여기에 다음을 수행 할 수 있습니다.
./deepspeaker/pretrained_models/ 에서 찾으십시오. python3 preprocess.py --dataset DATASET
모델을 훈련하십시오
python3 train.py --dataset DATASET
유용한 옵션 :
CUDA_VISIBLE_DEVICES=<GPU_IDs> 지정하십시오.사용
tensorboard --logdir output/log
지역 호스트에서 텐서 보드를 제공합니다.
'none' 과 'DeepSpeaker' 사이)를 설정하여 전환 할 수 있습니다.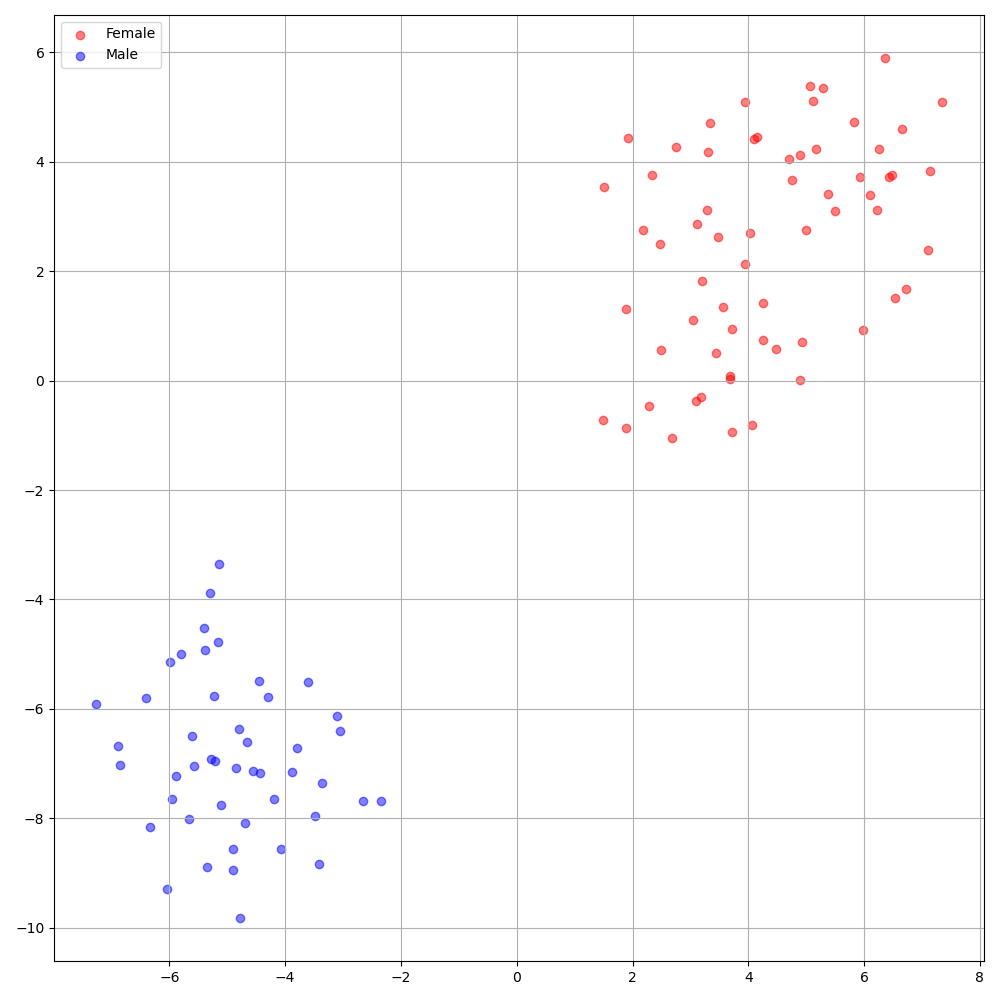
About Section (메인 페이지의 오른쪽 상단)의 "이 저장소 인용"으로이 저장소를 인용하십시오.


