Comprehensive E2E TTS
1.0.0
ข้อความแบบ end-to-end-end-to-end ที่ไม่ใช่ คำพูด (สร้างข้อความที่ได้รับจากรูปแบบของคลื่น) ซึ่งสนับสนุนครอบครัวของแบบจำลองระยะเวลาที่ไม่ได้รับการดูแลของ SOTA โครงการนี้เติบโตขึ้นพร้อมกับชุมชนการวิจัย โดยมีวัตถุประสงค์เพื่อให้บรรลุ E2E-TTS ที่ดีที่สุด คำแนะนำใด ๆ ที่มีต่อ TTS แบบ end-to-end ที่ดีที่สุดยินดีต้อนรับ :)
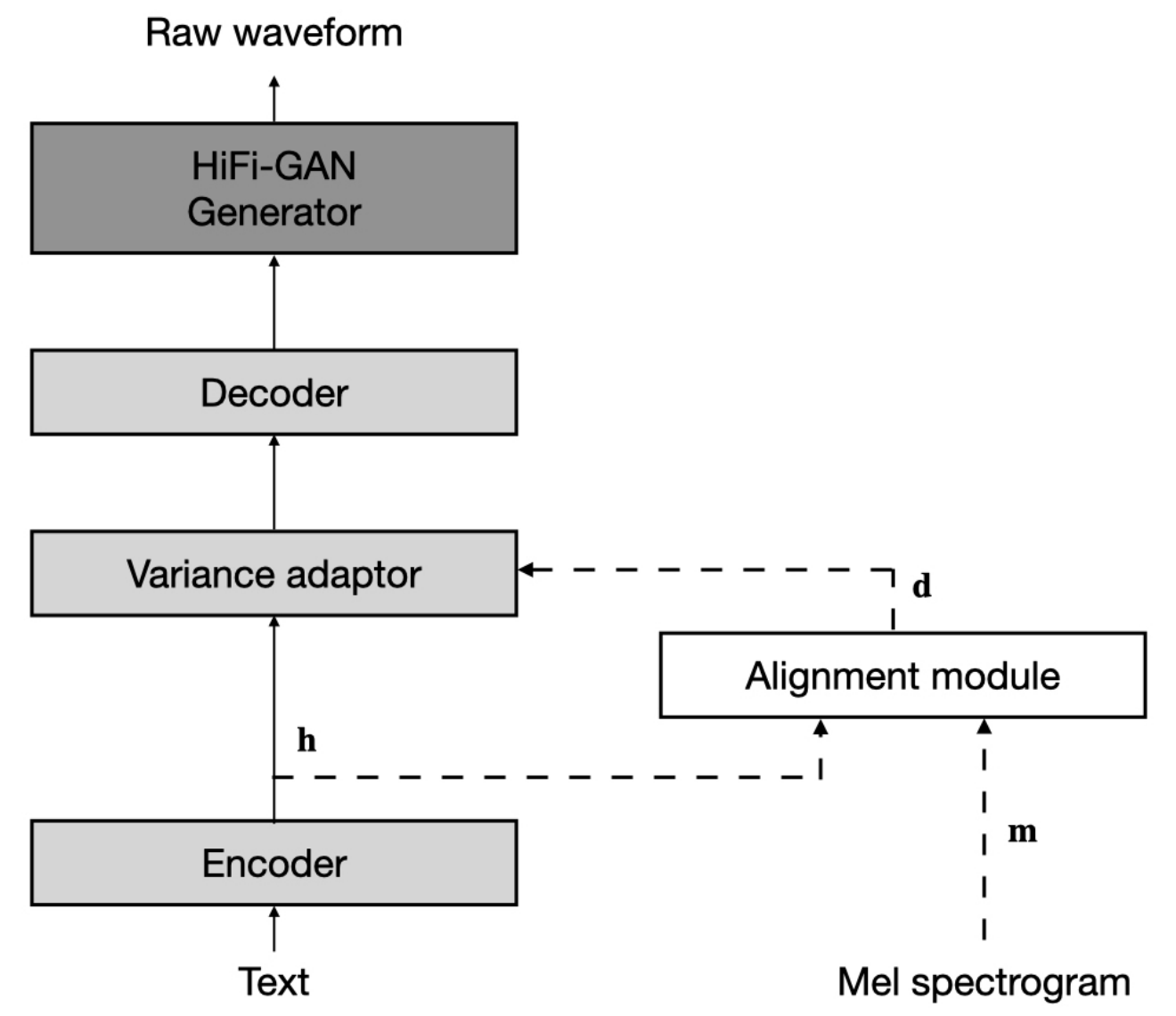
ชุดข้อมูล หมายถึงชื่อของชุดข้อมูลเช่น LJSpeech และ VCTK ในเอกสารต่อไปนี้
คุณสามารถติดตั้งการพึ่งพา Python ด้วย
pip3 install -r requirements.txt
นอกจากนี้ Dockerfile ยังมีไว้สำหรับผู้ใช้ Docker
คุณต้องดาวน์โหลดโมเดลที่ผ่านการฝึกอบรม (จะแชร์เร็ว ๆ นี้) และวางไว้ใน output/ckpt/DATASET/
สำหรับ TTS ลำโพงเดียว Run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
สำหรับ TTs หลายลำโพง
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
พจนานุกรมของลำโพงที่เรียนรู้สามารถพบได้ที่ preprocessed_data/DATASET/speakers.json และคำพูดที่สร้างขึ้นจะถูกนำไปใช้ใน output/result/
รองรับการอนุมานแบบแบทช์ด้วยลอง
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
เพื่อสังเคราะห์คำพูดทั้งหมดใน preprocessed_data/DATASET/val.txt
ระดับเสียง/ปริมาตร/การพูดของคำพูดสังเคราะห์สามารถควบคุมได้โดยการระบุอัตราส่วนระดับเสียง/พลังงาน/ระยะเวลาที่ต้องการ ตัวอย่างเช่นหนึ่งสามารถเพิ่มอัตราการพูดได้ 20 % และลดปริมาณลง 20 % โดย
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
เพิ่ม -Speaker_id Speaker_id สำหรับ TTS หลายลำโพง
ชุดข้อมูลที่รองรับคือ
ชุดข้อมูล TTS สองลำกล้องเดียว (เช่น Blizzard Challenge 2013) และชุดข้อมูล TTS หลายลำโพง (เช่น Libritts) สามารถเพิ่มได้ตาม LJSpeech และ VCTK ตามลำดับ ยิ่งไปกว่านั้น ภาษาและชุดข้อมูลของคุณเอง สามารถปรับได้ตามที่นี่
./deepspeaker/pretrained_models/ deepspeaker/pretrained_models/ python3 preprocess.py --dataset DATASET
ฝึกอบรมแบบจำลองของคุณด้วย
python3 train.py --dataset DATASET
ตัวเลือกที่มีประโยชน์:
CUDA_VISIBLE_DEVICES=<GPU_IDs> ที่จุดเริ่มต้นของคำสั่งด้านบนใช้
tensorboard --logdir output/log
เพื่อให้บริการ Tensorboard บนบ้านของคุณ
'none' และ 'DeepSpeaker' )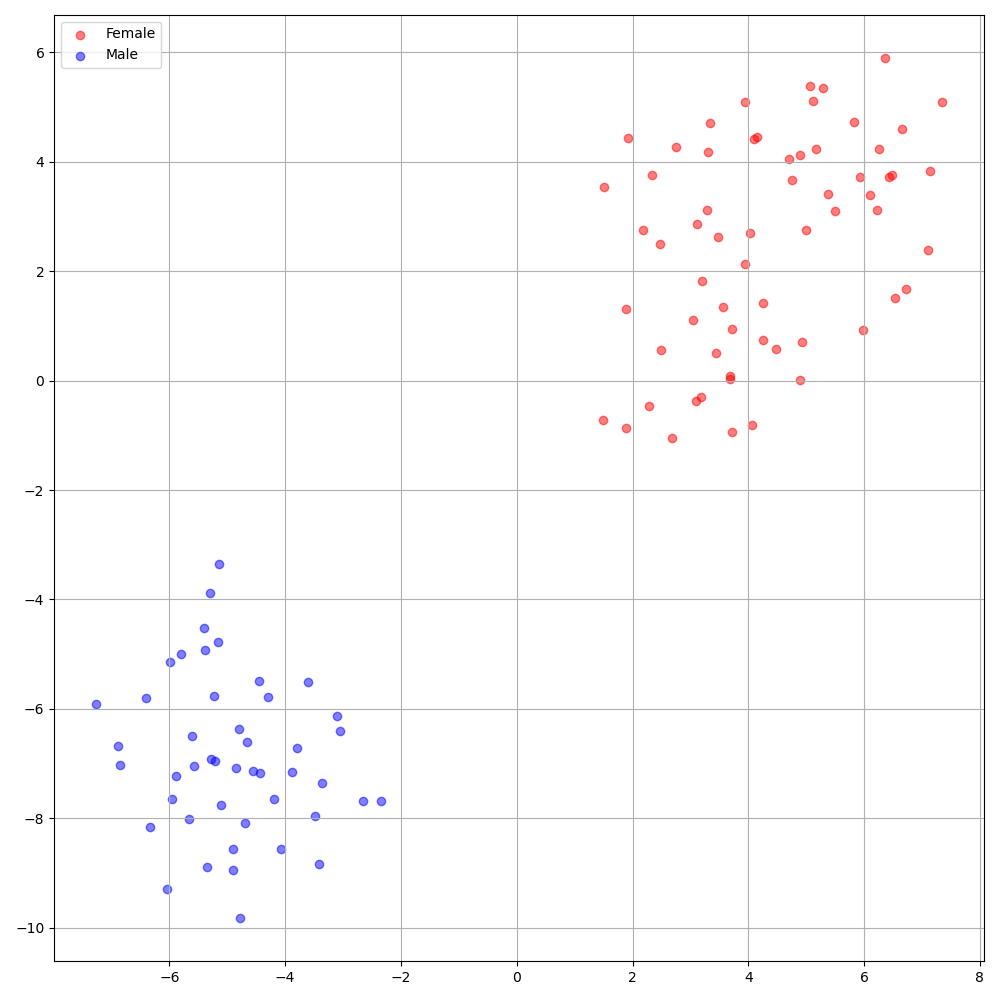
โปรดอ้างอิงพื้นที่เก็บข้อมูลนี้โดย "อ้างอิงที่เก็บนี้" ของส่วน เกี่ยวกับ (ขวาบนของหน้าหลัก)


