Comprehensive E2E TTS
1.0.0
非自動節約的なエンドツーエンドのテキストからスピーチ(指定されたテキストを生成する波形生成)。ソタの監視なしの持続時間モデリングのファミリーをサポートします。このプロジェクトは、究極のE2E-TTSを達成することを目指して、研究コミュニティとともに成長します。最高のエンドツーエンドのTTに対する提案は大歓迎です:)
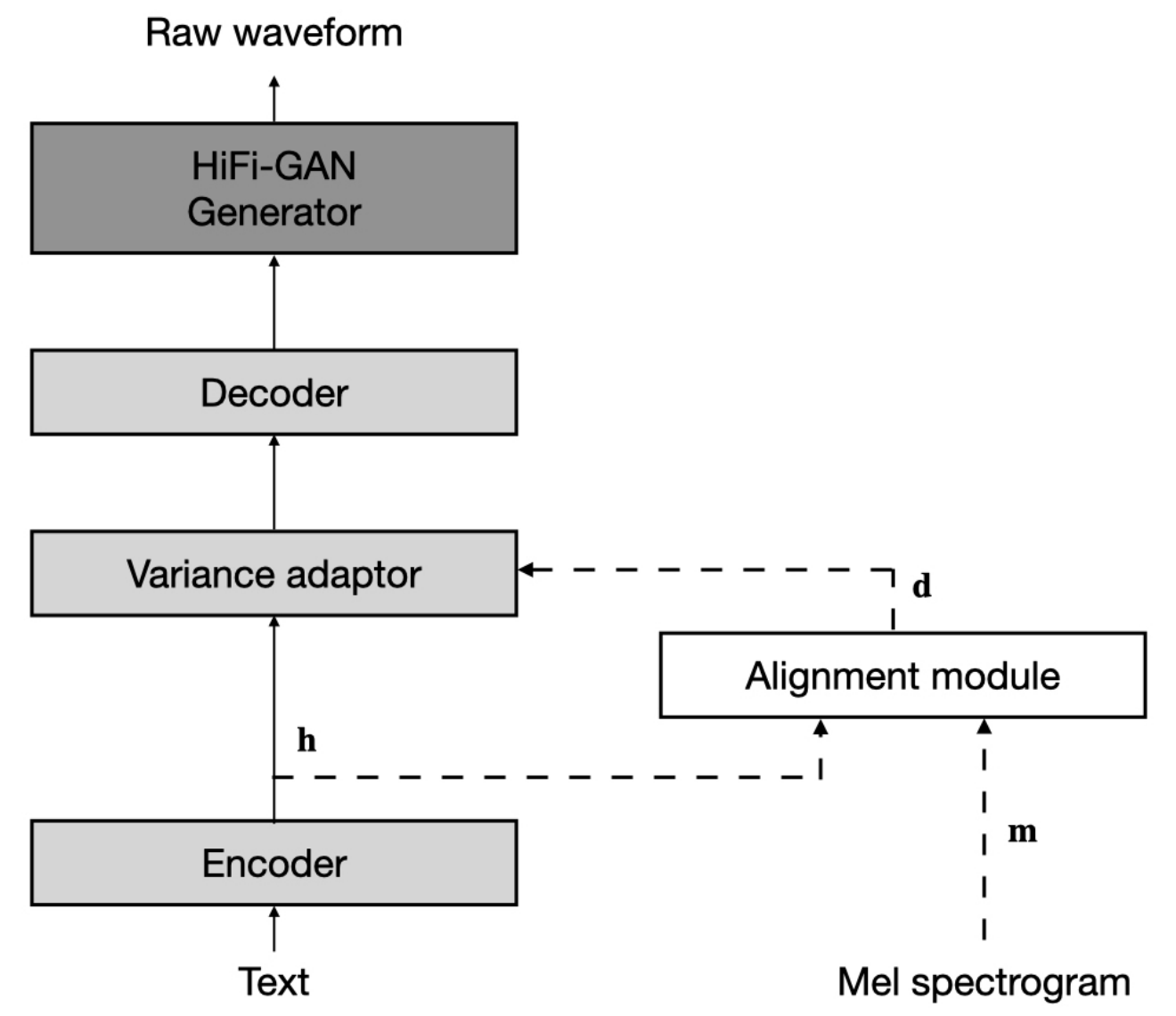
データセットとは、次のドキュメントでLJSpeechやVCTKなどのデータセットの名前を指します。
Python依存関係をインストールできます
pip3 install -r requirements.txt
また、 DockerfileはDockerユーザーに提供されています。
事前に保護されたモデルをダウンロードし(間もなく共有されます)、それらをoutput/ckpt/DATASET/に配置する必要があります。
単一スピーカーのTTSの場合、実行します
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
マルチスピーカーのTTSの場合、実行します
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
学習スピーカーの辞書はpreprocessed_data/DATASET/speakers.jsonで見つけることができ、生成された発話はoutput/result/に配置されます。
バッチ推論もサポートされています
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
preprocessed_data/DATASET/val.txtのすべての発話を合成します。
合成された発話のピッチ/ボリューム/発話レートは、目的のピッチ/エネルギー/持続時間比を指定することで制御できます。たとえば、発言率を20%上げて、体積を20%減らすことができます
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Multi-Speaker TTSに-peaker_id speaker_idを追加します。
サポートされているデータセットは次のとおりです
シングルスピーカーTTSデータセット(Blizzard Challenge 2013など)とマルチスピーカーTTSデータセット(Librittsなど)の両方を、それぞれLJSpeechとVCTKに従って追加できます。さらに、あなた自身の言語とデータセットをここに採用することができます。
./deepspeaker/pretrained_models/に見つけます。 python3 preprocess.py --dataset DATASET
モデルを訓練します
python3 train.py --dataset DATASET
有用なオプション:
CUDA_VISIBLE_DEVICES=<GPU_IDs>を指定します。使用
tensorboard --logdir output/log
LocalHostでTensorboardを提供します。
'none'と'DeepSpeaker'の間)を設定して切り替えることができます。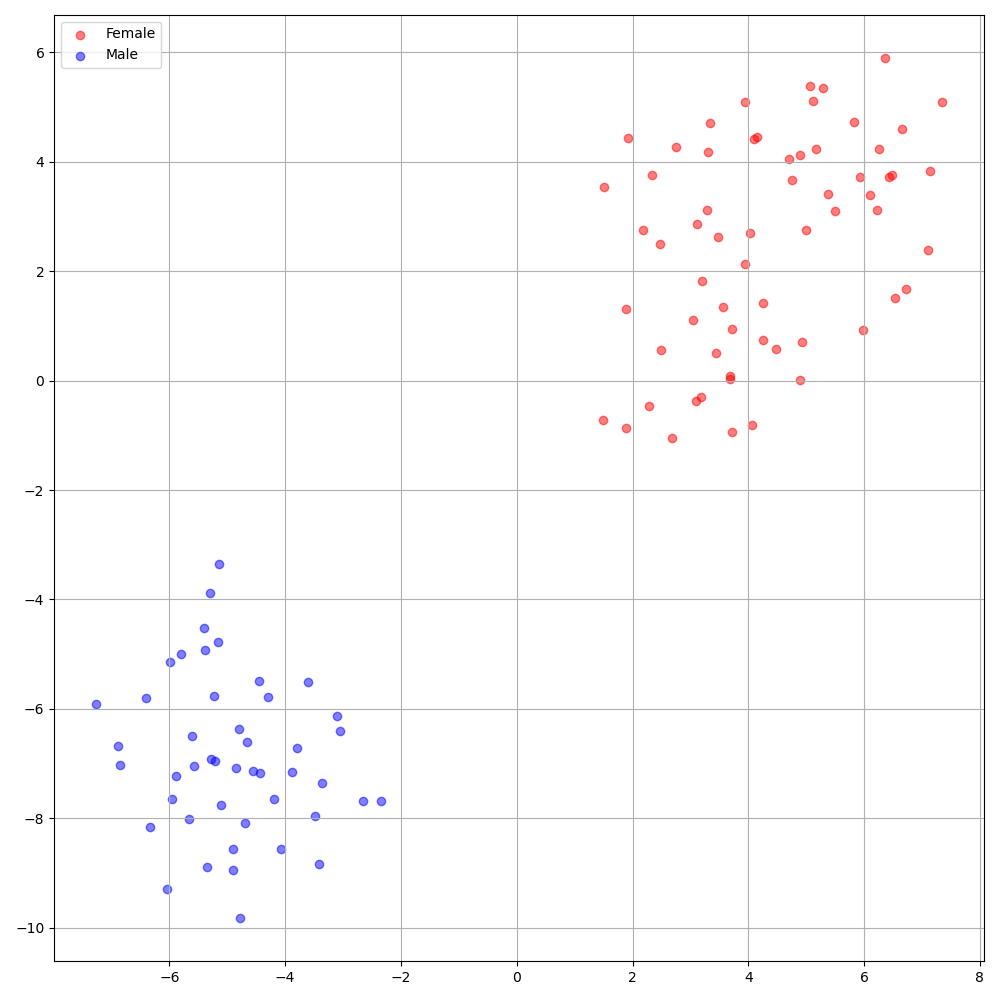
このリポジトリは、セクションについての「このリポジトリを引用」して引用してください(メインページの右上)。


