Comprehensive E2E TTS
1.0.0
نص من طرف إلى طرف من طرف إلى طرف (توليد موجة موجة معطى) ، يدعم عائلة من نماذج المدة غير الخاضعة للإشراف. ينمو هذا المشروع مع مجتمع الأبحاث ، بهدف تحقيق E2E-TTS النهائي . أي اقتراحات تجاه أفضل TTs من طرف إلى طرف ترحيب :)
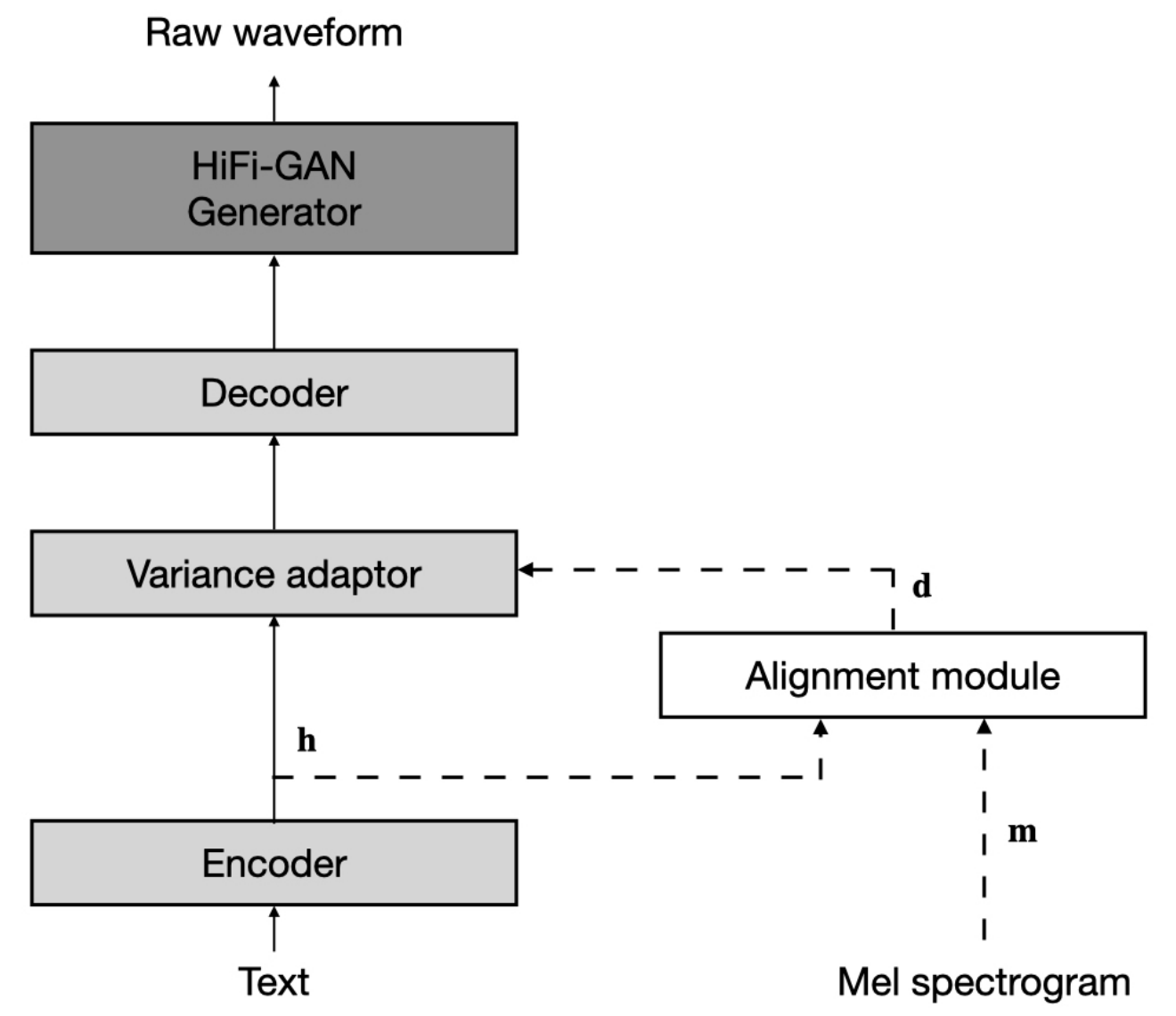
تشير مجموعة البيانات إلى أسماء مجموعات البيانات مثل LJSpeech و VCTK في المستندات التالية.
يمكنك تثبيت تبعيات Python مع
pip3 install -r requirements.txt
أيضا ، يتم توفير Dockerfile لمستخدمي Docker .
يجب عليك تنزيل النماذج المسبقة (سيتم مشاركتها قريبًا) ووضعها في output/ckpt/DATASET/ .
للحصول على TTS واحد ، قم بتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
للحصول على TTS متعددة المتحدثين ، قم بتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
يمكن العثور على قاموس مكبرات الصوت المستفادة في preprocessed_data/DATASET/speakers.json output/result/
يتم دعم استنتاج الدُفعات أيضًا ، حاول
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
لتوليف جميع الكلمات في preprocessed_data/DATASET/val.txt .
يمكن السيطرة على معدل الملعب/الحجم/التحدث للكلمات التوليف عن طريق تحديد نسب الملعب/الطاقة/المدة المطلوبة. على سبيل المثال ، يمكن للمرء زيادة معدل التحدث بنسبة 20 ٪ وتقليل الحجم بنسبة 20 ٪ بنسبة 20 ٪
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
إضافة- speaker_id speaker_id للحصول على TTS متعددة الكلام.
مجموعات البيانات المدعومة
يمكن إضافة أي من مجموعة بيانات TTS الفردية (على سبيل المثال ، Blizzard Challenge 2013) ومجموعة بيانات TTS متعددة المتحدثين (على سبيل المثال ، Libritts) بعد LJSPEED و VCTK ، على التوالي. علاوة على ذلك ، يمكن تكييف لغتك ومجموعة البيانات الخاصة بك هنا.
./deepspeaker/pretrained_models/ python3 preprocess.py --dataset DATASET
تدريب النموذج الخاص بك مع
python3 train.py --dataset DATASET
خيارات مفيدة:
CUDA_VISIBLE_DEVICES=<GPU_IDs> في بداية الأمر أعلاه.يستخدم
tensorboard --logdir output/log
لخدمة Tensorboard على مضيفك المحلي.
'none' و 'DeepSpeaker' ).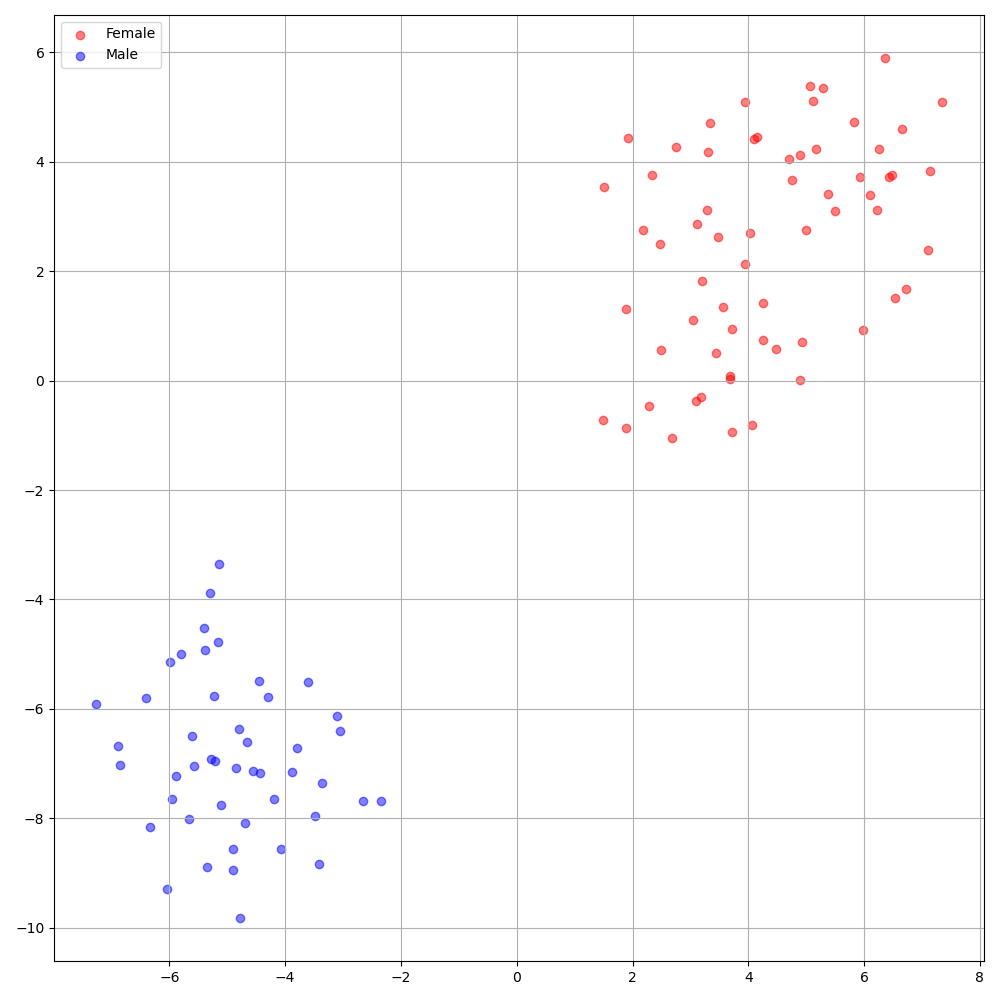
يرجى الاستشهاد بهذا المستودع من خلال "استشهد بهذا المستودع" من القسم (أعلى يمين الصفحة الرئيسية).


