Comprehensive E2E TTS
1.0.0
Un texte à la recherche de bout en bout non autorégressif (génération de forme d'onde donnée par le texte), soutenant une famille de modélines de durée non supervisées SOTA. Ce projet se développe avec la communauté de la recherche, visant à réaliser l'ultime E2E-TTS . Toutes les suggestions vers les meilleures TT de bout en bout sont les bienvenues :)
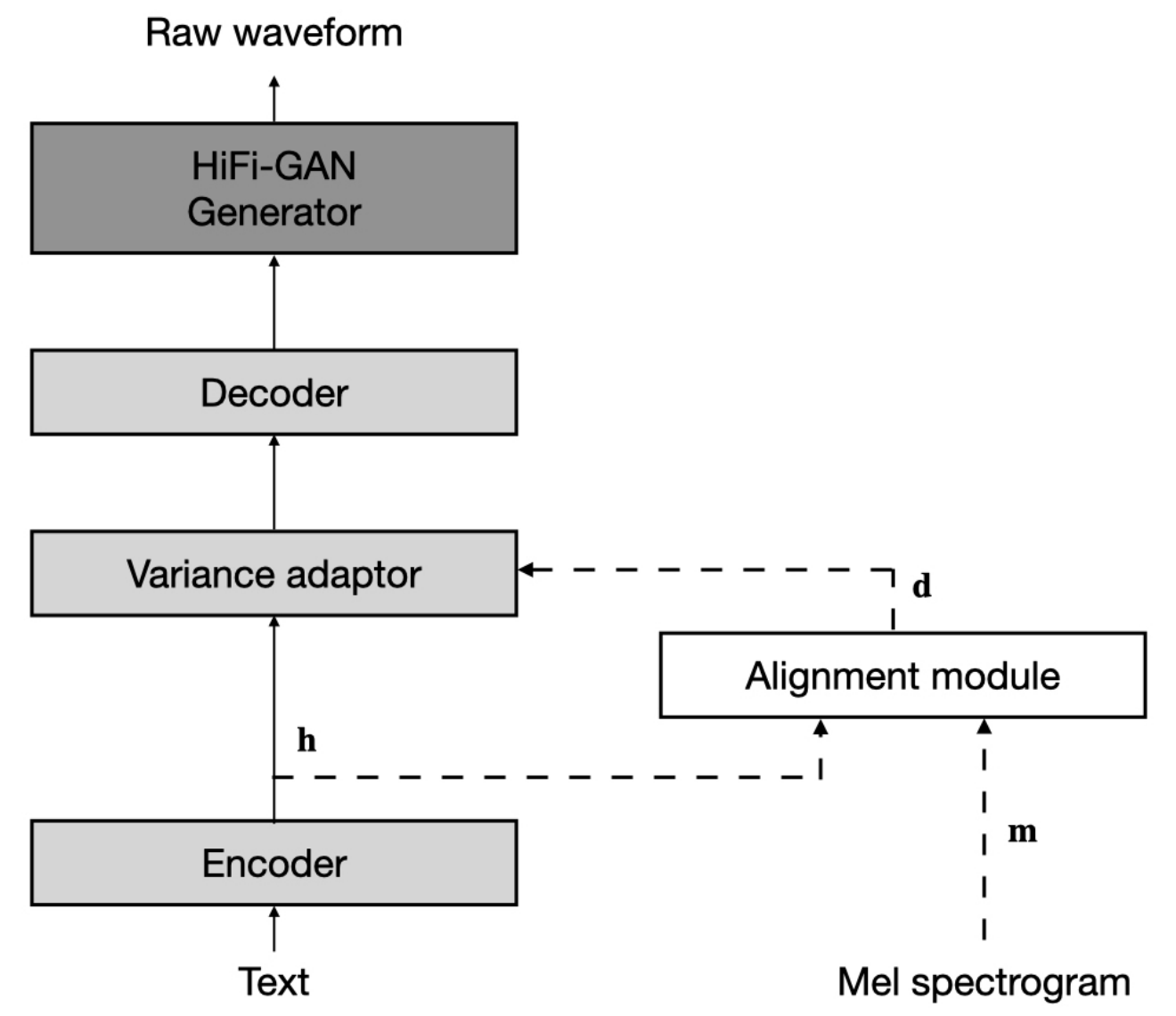
L'ensemble de données fait référence aux noms des ensembles de données tels que LJSpeech et VCTK dans les documents suivants.
Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt
De plus, Dockerfile est fourni pour les utilisateurs Docker .
Vous devez télécharger les modèles pré-entraînés (sera partagé bientôt) et les mettre dans output/ckpt/DATASET/ .
Pour un TTS à un seul haut-parleur , courez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Pour un TTS multi-haut-parleurs , exécutez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Le dictionnaire des enceintes savants peut être trouvé sur preprocessed_data/DATASET/speakers.json , et les énoncés générés seront placés en output/result/ .
L'inférence par lots est également prise en charge, essayez
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Pour synthétiser toutes les énoncés dans preprocessed_data/DATASET/val.txt .
La hauteur / volume / le taux de parole des énoncés synthétisés peut être contrôlé en spécifiant les rapports de pitch / énergie / durée souhaités. Par exemple, on peut augmenter le taux de parole de 20% et diminuer le volume de 20% par
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Ajouter - Speaker_id Speaker_ID pour un TTS multi-haut-parleurs.
Les ensembles de données pris en charge sont
L'ensemble de données TTS mono-identifiant (par exemple, Blizzard Challenge 2013) et l'ensemble de données TTS multi-ordres (par exemple, Libritts) peuvent être ajoutés après LJSpeech et VCTK, respectivement. De plus, votre propre langue et ensemble de données peuvent être adaptés à la suite ici.
./deepspeaker/pretrained_models/ . python3 preprocess.py --dataset DATASET
Former votre modèle avec
python3 train.py --dataset DATASET
Options utiles:
CUDA_VISIBLE_DEVICES=<GPU_IDs> au début de la commande ci-dessus.Utiliser
tensorboard --logdir output/log
pour servir Tensorboard sur votre hôte local.
'none' et 'DeepSpeaker' ).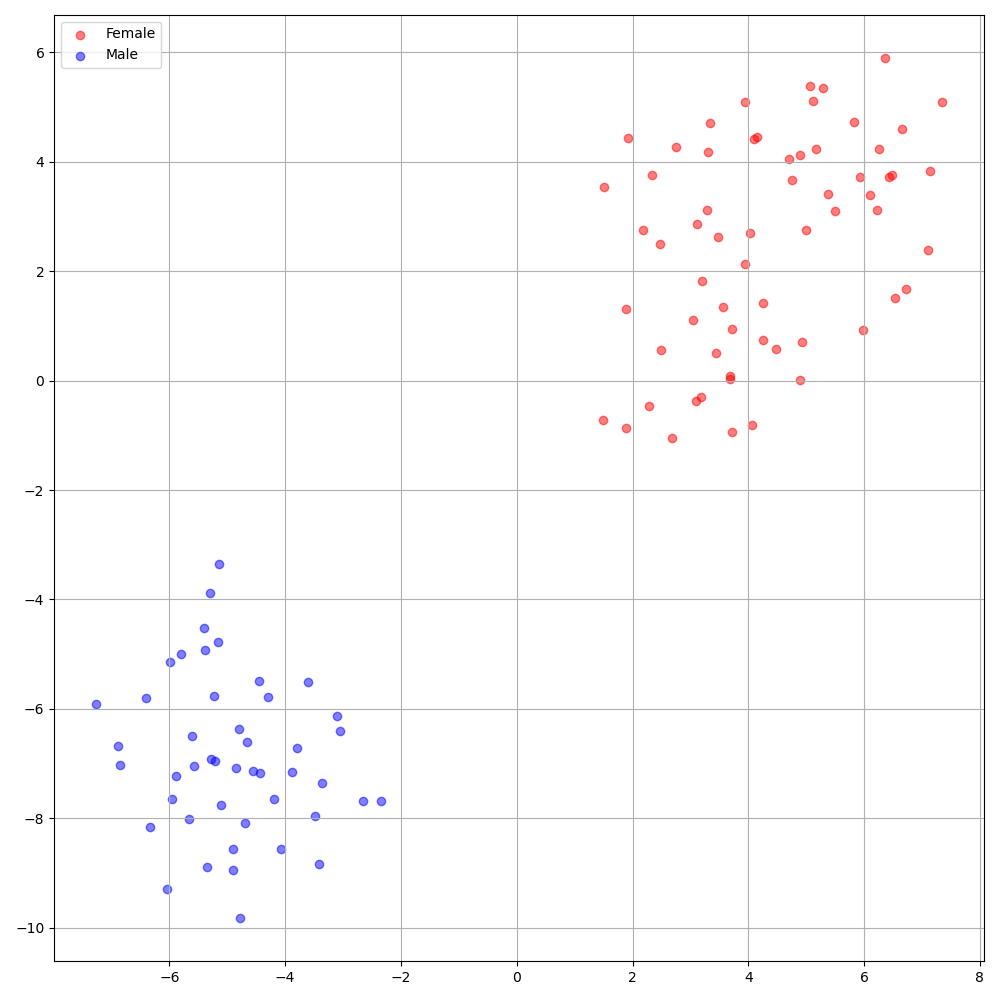
Veuillez citer ce référentiel par le "Citez ce référentiel" de la section environ (en haut à droite de la page principale).


