Comprehensive E2E TTS
1.0.0
Неавторегрессивный сквозной сквозной текст в речь (генерируя текст волновой формы), поддерживающая семейство моделей продолжительности SOTA, не контролируемой продолжительностью. Этот проект растет с исследовательским сообществом, стремясь достичь конечных E2E-TTS . Любые предложения по отношению к лучшим сквозным TTS приветствуются :)
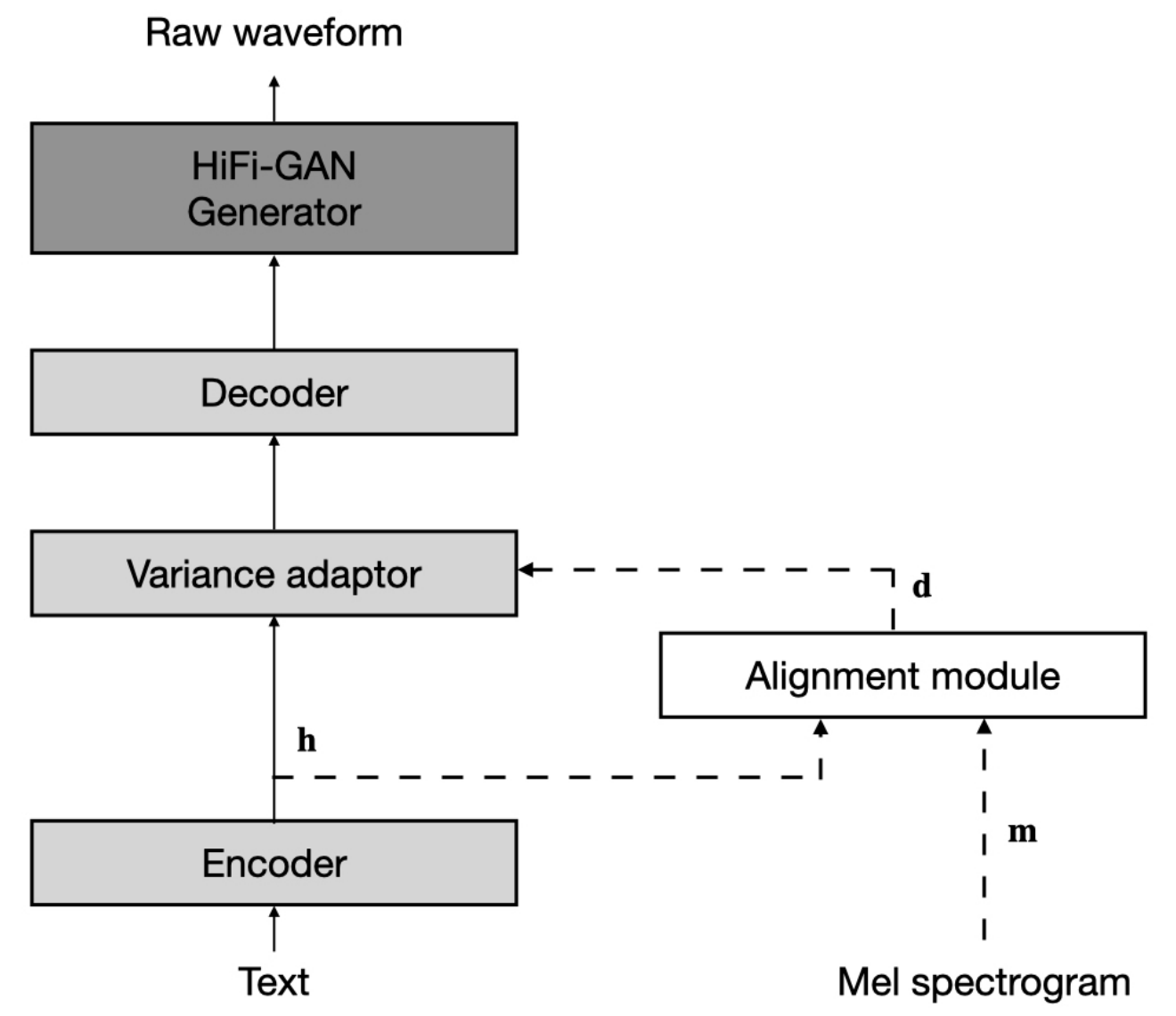
Набор данных относится к именам наборов данных, таких как LJSpeech и VCTK в следующих документах.
Вы можете установить зависимости Python с
pip3 install -r requirements.txt
Кроме того, Dockerfile предоставлен для пользователей Docker .
Вы должны скачать предварительно проведенные модели (скоро будут переданы) и поместить их в output/ckpt/DATASET/ .
Для одноразовых TTS , бегите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Для многопрофильных TTS , запустите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Словарь ученых докладчиков можно найти на preprocessed_data/DATASET/speakers.json output/result/
Пакетный вывод также поддерживается, попробуйте
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Чтобы синтезировать все высказывания в preprocessed_data/DATASET/val.txt .
Скорость шага/объема/разговора синтезированных высказываний можно контролировать, указав желаемый коэффициент высоты/энергии/продолжительности. Например, можно увеличить скорость разговора на 20 % и уменьшить объем на 20 % на
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Добавить -speaker_id speaker_id для многопрофильного TTS.
Поддерживаемые наборы данных
Любой из набора данных TTS с одной динамикой (например, Blizzard Challenge 2013), так и набор данных Multi-Speaker TTS (например, Libritts) можно добавить после LJSPEECH и VCTK, соответственно. Более того, ваш собственный язык и набор данных могут быть адаптированы здесь.
./deepspeaker/pretrained_models/ . python3 preprocess.py --dataset DATASET
Тренировать свою модель с
python3 train.py --dataset DATASET
Полезные варианты:
CUDA_VISIBLE_DEVICES=<GPU_IDs> в начале вышеуказанной команды.Использовать
tensorboard --logdir output/log
Подавать в Tensorboard на вашем местном хосте.
'none' и 'DeepSpeaker' ).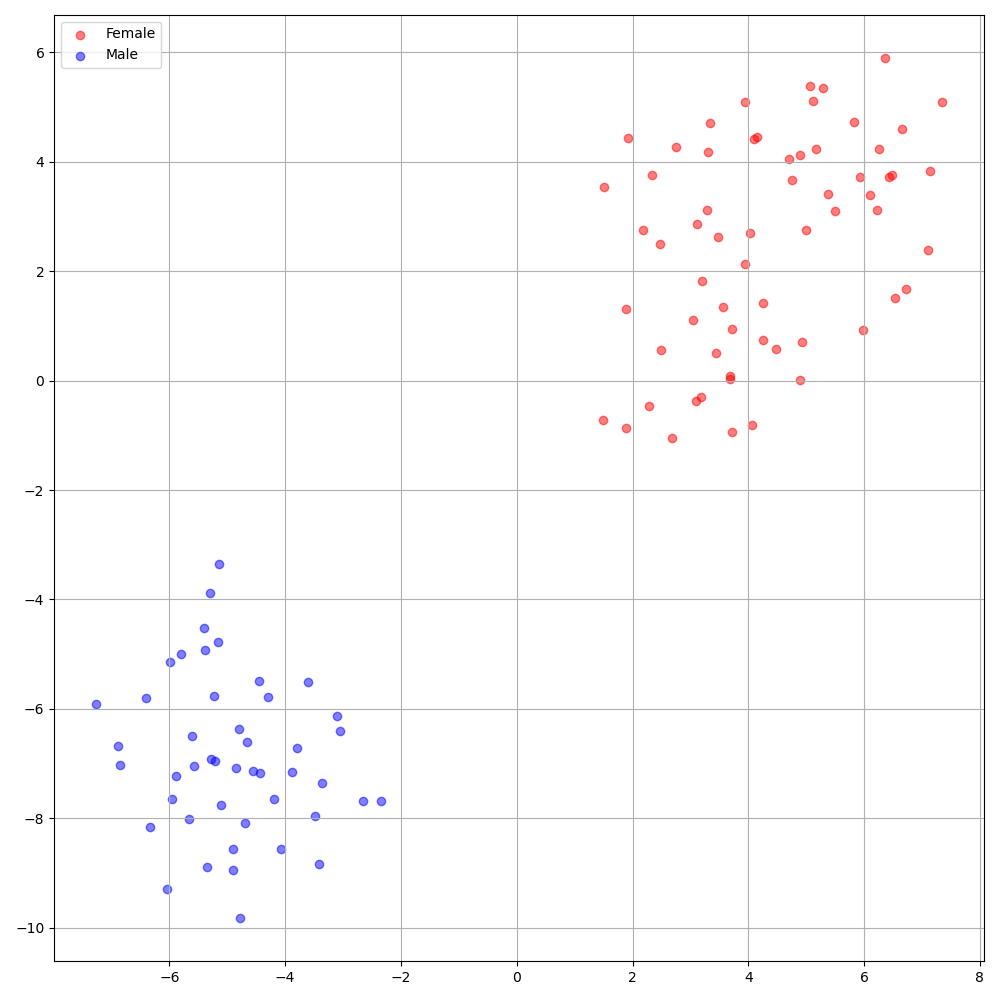
Пожалуйста, цитируйте этот репозиторий с помощью «цитируйте этот репозиторий» о разделе (верхняя правая на главной странице).


