Comprehensive E2E TTS
1.0.0
Um texto a ponta não autorregressivo de ponta a ponta (geração de texto de onda dado), apoiando uma família de modelações de duração não supervisionadas SOTA. Este projeto cresce com a comunidade de pesquisa, com o objetivo de alcançar o melhor E2E-TTS . Quaisquer sugestões para os melhores TTs de ponta a ponta são bem-vindos :)
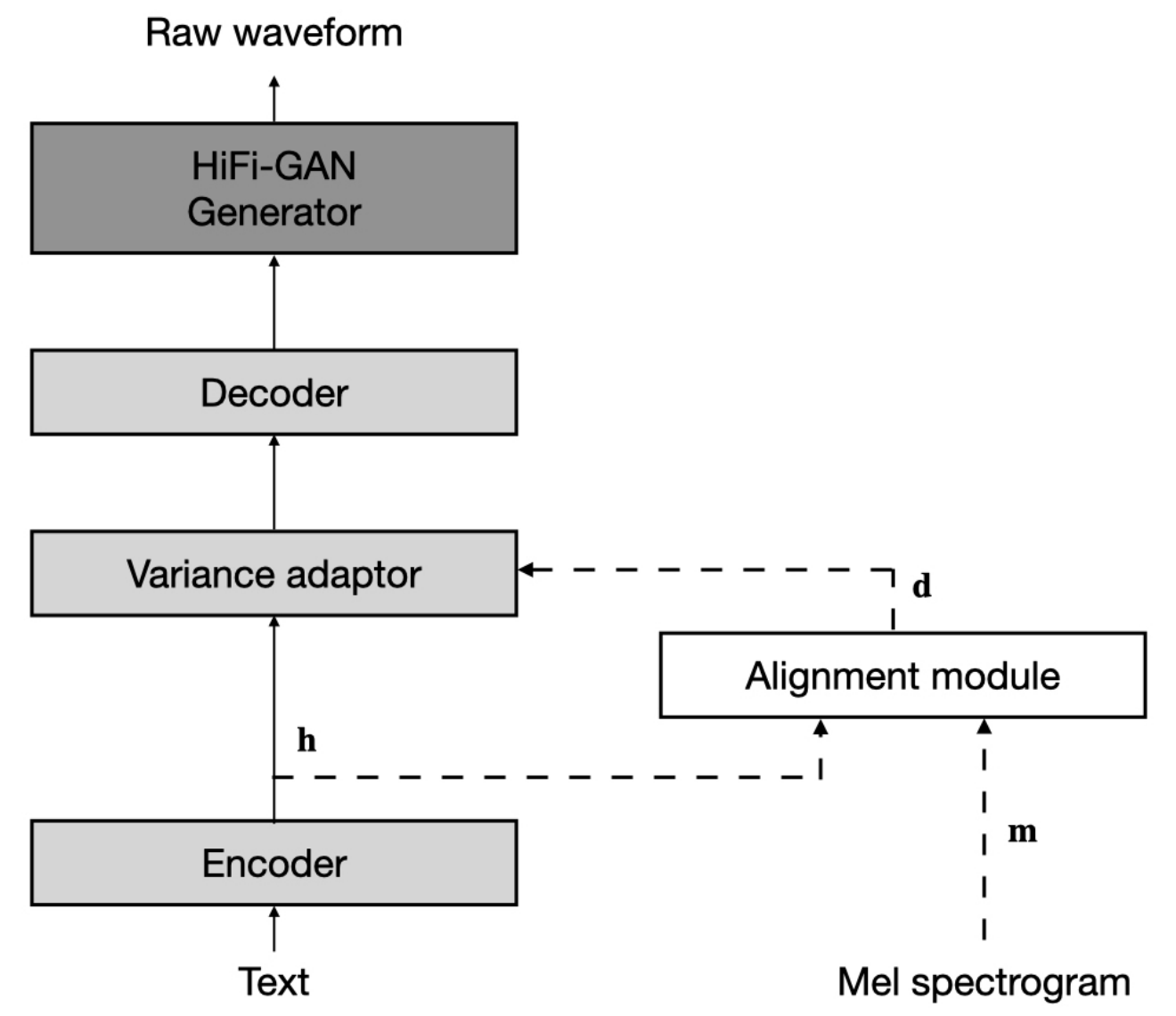
O conjunto de dados refere -se aos nomes de conjuntos de dados como LJSpeech e VCTK nos seguintes documentos.
Você pode instalar as dependências do Python com
pip3 install -r requirements.txt
Além disso, Dockerfile é fornecido para usuários Docker .
Você deve baixar os modelos pré -tenhados (será compartilhado em breve) e colocá -los em output/ckpt/DATASET/ .
Para um tts de alto-falante , execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET
Para um TTS de vários falantes , execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
O dicionário de alto -falantes instruídos pode ser encontrado em preprocessed_data/DATASET/speakers.json , e os enunciados gerados serão colocados em output/result/ .
A inferência em lote também é suportada, tente
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todos os enunciados em preprocessed_data/DATASET/val.txt .
A taxa de afinação/volume/fala dos enunciados sintetizados pode ser controlada especificando as taxas desejadas de afinação/energia/duração. Por exemplo, pode -se aumentar a taxa de fala em 20 % e diminuir o volume em 20 % em
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Adicionar -speaker_id speaker_id para um TTS multi-falante.
Os conjuntos de dados suportados são
Qualquer um dos conjuntos de dados TTS de alto-falante (por exemplo, Blizzard Challenge 2013) e o conjunto de dados TTS de vários falantes (por exemplo, Libritts) podem ser adicionados seguindo LJSpeech e VCTK, respectivamente. Além disso, seu próprio idioma e conjunto de dados podem ser adaptados a seguir aqui.
./deepspeaker/pretrained_models/ . python3 preprocess.py --dataset DATASET
Treine seu modelo com
python3 train.py --dataset DATASET
Opções úteis:
CUDA_VISIBLE_DEVICES=<GPU_IDs> no início do comando acima.Usar
tensorboard --logdir output/log
Para servir o Tensorboard em sua localhost.
'none' e 'DeepSpeaker' ).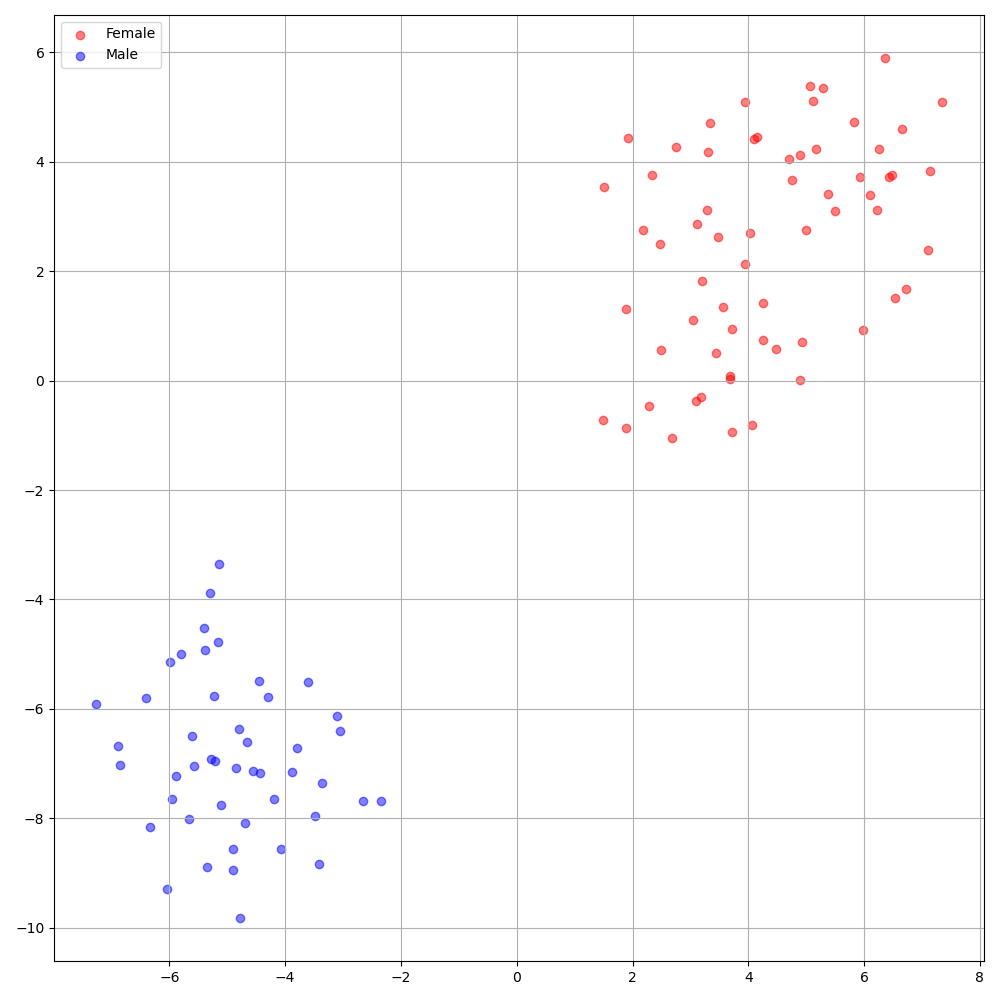
Cite este repositório pelo "citar este repositório" da seção Sobre (canto superior direito da página principal).


