SyntaSpeech
Pretrained Models for LJ, Biaobei, and LibriTTS.
| | | 中文文檔
該存儲庫是我們IJCAI-2022論文的官方Pytorch實施,在其中我們建議語法為語法 - 意識到非自動性退休文本到語音。
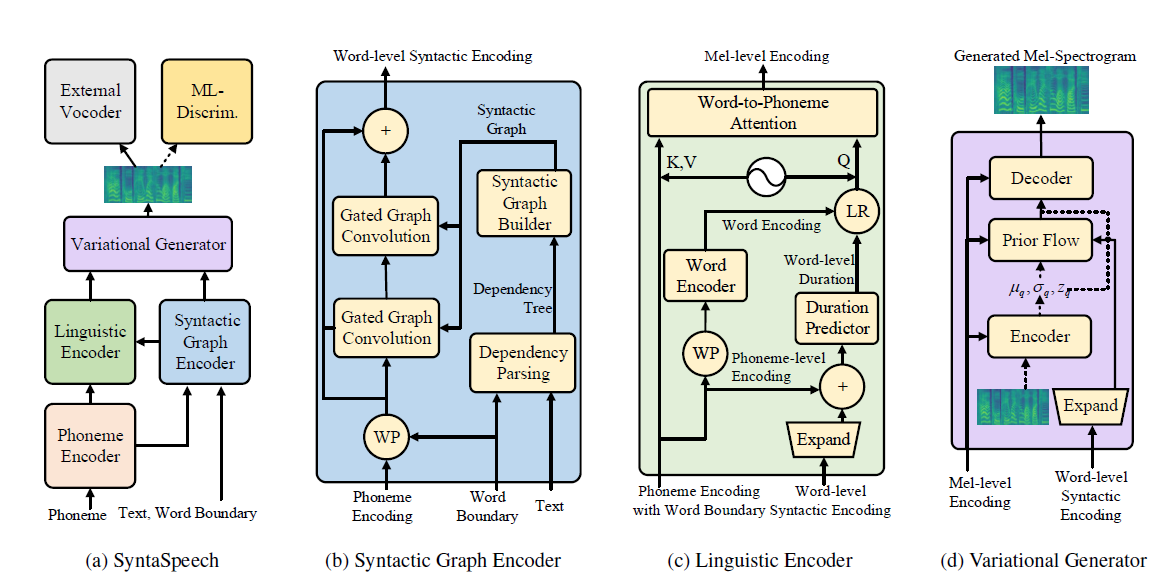
我們的語法是基於Portaspeech(Neurips 2021)建立的,具有三個新功能:
conda create -n synta python=3.7
condac activate synta
pip install -U pip
pip install Cython numpy==1.19.1
pip install torch==1.9.0
pip install -r requirements.txt
# install dgl for graph neural network, dgl-cu102 supports rtx2080, dgl-cu113 support rtx3090
pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html
sudo apt install -y sox libsox-fmt-mp3
bash mfa_usr/install_mfa.sh # install force alignment tools 請按照以下步驟運行此存儲庫。
您可以直接將我們的二進制數據集用於LJSpeech和Biaobei。下載它們,然後將它們解壓縮到data/binary/文件夾中。
至於Libritts,您可以下載RAW數據集並使用我們的data_gen模塊對其進行處理。詳細說明可以在DOSC/prepar_data中找到。
我們為三個數據集提供了培訓的輔助訓練模型。具體而言,Hifi-gan用於ljspeech和biaobei,for libritts的平行波。下載並將其解壓縮到checkpoints/文件夾中。
然後,您可以在三個數據集中訓練Syntaspeech。
cd < the root_dir of your SyntaSpeech folder >
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset # training in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset # training in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset # training in LibriTTStensorboard --logdir=checkpoints/lj_synta
tensorboard --logdir=checkpoints/biaobei_synta
tensorboard --logdir=checkpoints/libritts_syntaCUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset --infer # inference in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset --infer # inference in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset ---infer # inference in LibriTTS 紙上的音頻樣本可以在我們的演示頁面中找到。
我們還為LJSpeech提供了擁抱表演頁面。在那裡嘗試您有趣的句子!
@article{ye2022syntaspeech,
title={SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech},
author={Ye, Zhenhui and Zhao, Zhou and Ren, Yi and Wu, Fei},
journal={arXiv preprint arXiv:2204.11792},
year={2022}
}
我們的代碼基於以下存儲庫:


