SyntaSpeech
Pretrained Models for LJ, Biaobei, and LibriTTS.
| | | 中文文档
Este repositorio es la implementación oficial de Pytorch de nuestro documento IJCAI-2022, en el que proponemos SynTespeech para el texto a voz no autorregresivo sintaxis.
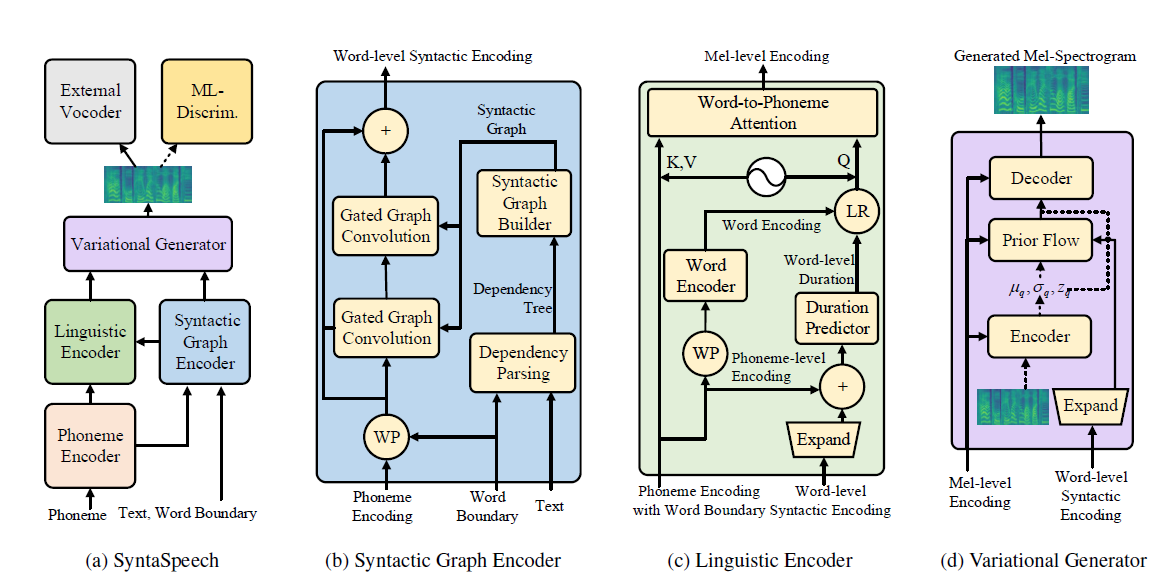
Nuestro SynTespeech está construido sobre la base de Portaspech (Neurips 2021) con tres nuevas características:
conda create -n synta python=3.7
condac activate synta
pip install -U pip
pip install Cython numpy==1.19.1
pip install torch==1.9.0
pip install -r requirements.txt
# install dgl for graph neural network, dgl-cu102 supports rtx2080, dgl-cu113 support rtx3090
pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html
sudo apt install -y sox libsox-fmt-mp3
bash mfa_usr/install_mfa.sh # install force alignment tools Siga los siguientes pasos para ejecutar este repositorio.
Puede usar directamente nuestros conjuntos de datos binarizados para LJSpeech y Biaobei. Descárgalos y descompondalos en los data/binary/ carpeta.
En cuanto a Libritts, puede descargar los conjuntos de datos sin procesar y procesarlos con nuestros módulos data_gen . Las instrucciones detalladas se pueden encontrar en DOSC/Prepare_Data.
Proporcionamos el modelo previamente capacitado de vocoders para tres conjuntos de datos. Específicamente, Hifi-Gan para LJSpeech y Biaobei, Parallelwavegan para Libritts. Descargue y descomponga en los checkpoints/ carpeta.
Luego puede entrenar sintaspech en los tres conjuntos de datos.
cd < the root_dir of your SyntaSpeech folder >
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset # training in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset # training in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset # training in LibriTTStensorboard --logdir=checkpoints/lj_synta
tensorboard --logdir=checkpoints/biaobei_synta
tensorboard --logdir=checkpoints/libritts_syntaCUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset --infer # inference in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset --infer # inference in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset ---infer # inference in LibriTTS Las muestras de audio en el papel se pueden encontrar en nuestra página de demostración.
También proporcionamos una página de demostración de Huggingface para LJSpeech. ¡Prueba tus frases interesantes allí!
@article{ye2022syntaspeech,
title={SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech},
author={Ye, Zhenhui and Zhao, Zhou and Ren, Yi and Wu, Fei},
journal={arXiv preprint arXiv:2204.11792},
year={2022}
}
Nuestros códigos se basan en los siguientes Repos:


