SyntaSpeech
Pretrained Models for LJ, Biaobei, and LibriTTS.
| | | 中文文档
이 저장소는 IJCAI-2022 논문의 공식 Pytorch 구현으로 구문 인식이 아닌 텍스트 음성 연사에 대해 구문을 제안합니다.
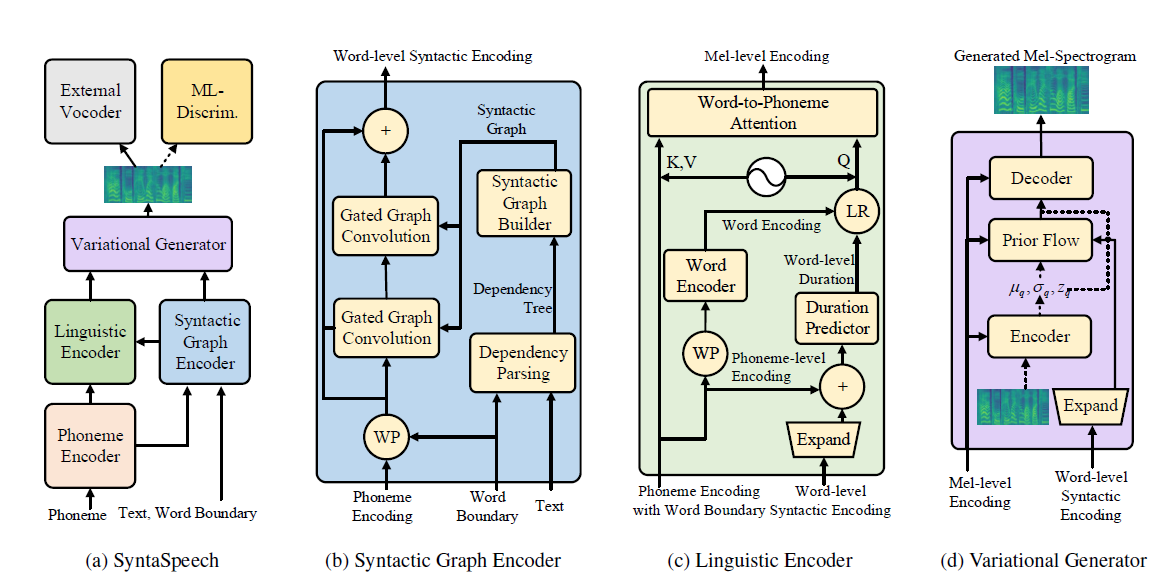
우리의 syntaspeech는 세 가지 새로운 기능을 갖춘 portaspeech (Neurips 2021)를 기반으로 구축되었습니다.
conda create -n synta python=3.7
condac activate synta
pip install -U pip
pip install Cython numpy==1.19.1
pip install torch==1.9.0
pip install -r requirements.txt
# install dgl for graph neural network, dgl-cu102 supports rtx2080, dgl-cu113 support rtx3090
pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html
sudo apt install -y sox libsox-fmt-mp3
bash mfa_usr/install_mfa.sh # install force alignment tools 다음 단계를 따르면이 저장소를 실행하십시오.
ljspeech 및 biaobei에 당사의 이항 데이터 세트를 직접 사용할 수 있습니다. 다운로드하여 data/binary/ 폴더에 압축을 풀어주십시오.
Libritts는 원시 데이터 세트를 다운로드하여 data_gen 모듈로 처리 할 수 있습니다. 자세한 지침은 DOSC/repary_data에서 찾을 수 있습니다.
우리는 3 개의 데이터 세트에 대해 미리 훈련 된 보코더 모델을 제공합니다. 구체적으로, ljspeech 및 biaobei, libritts의 병렬 Wavegan의 Hifi-gan. checkpoints/ 폴더로 다운로드하여 압축 해제하십시오.
그런 다음 세 데이터 세트에서 SyntAspeech를 훈련시킬 수 있습니다.
cd < the root_dir of your SyntaSpeech folder >
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset # training in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset # training in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset # training in LibriTTStensorboard --logdir=checkpoints/lj_synta
tensorboard --logdir=checkpoints/biaobei_synta
tensorboard --logdir=checkpoints/libritts_syntaCUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset --infer # inference in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset --infer # inference in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset ---infer # inference in LibriTTS 논문의 오디오 샘플은 데모 페이지에서 찾을 수 있습니다.
또한 LJSpeech 용 Huggingface 데모 페이지도 제공합니다. 거기에서 흥미로운 문장을 시도하십시오!
@article{ye2022syntaspeech,
title={SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech},
author={Ye, Zhenhui and Zhao, Zhou and Ren, Yi and Wu, Fei},
journal={arXiv preprint arXiv:2204.11792},
year={2022}
}
당사 코드는 다음 저장소를 기반으로합니다.


