SyntaSpeech
Pretrained Models for LJ, Biaobei, and LibriTTS.
| | | 中文文档
Dieses Repository ist die offizielle Pytorch-Implementierung unseres IJCAI-2022-Papiers, in dem wir Syntaspeech für syntaxbewusste nicht autoregressive Text-zu-Sprache vorschlagen.
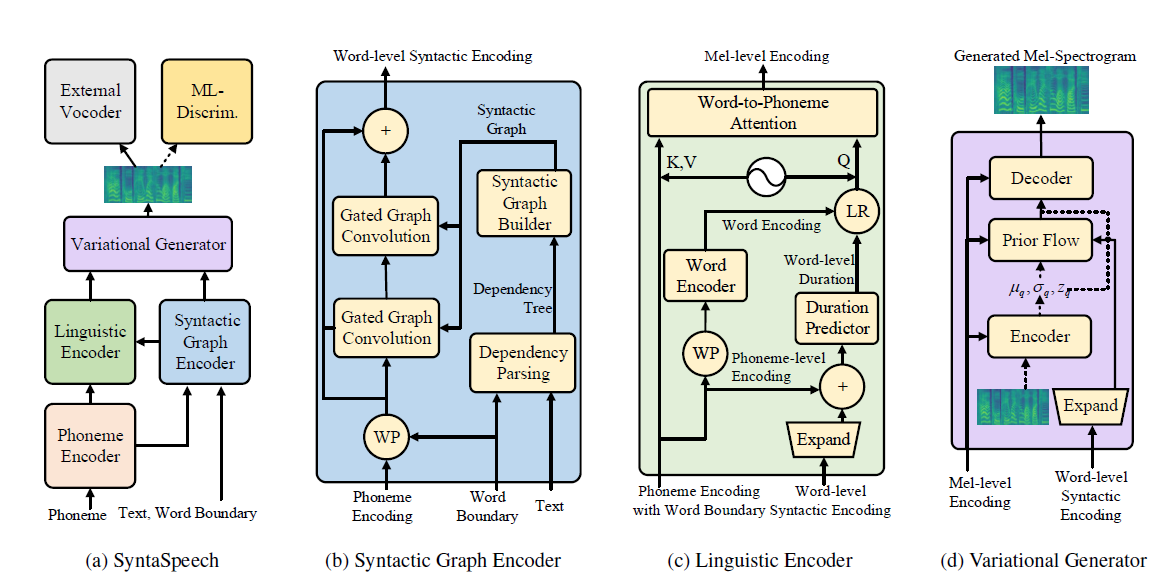
Unsere Syntaspeech basiert auf der Grundlage von Portaspeech (Neurips 2021) mit drei neuen Funktionen:
conda create -n synta python=3.7
condac activate synta
pip install -U pip
pip install Cython numpy==1.19.1
pip install torch==1.9.0
pip install -r requirements.txt
# install dgl for graph neural network, dgl-cu102 supports rtx2080, dgl-cu113 support rtx3090
pip install dgl-cu102 dglgo -f https://data.dgl.ai/wheels/repo.html
sudo apt install -y sox libsox-fmt-mp3
bash mfa_usr/install_mfa.sh # install force alignment tools Bitte befolgen Sie die folgenden Schritte, um dieses Repo auszuführen.
Sie können unsere binärisierten Datensätze für LJSpeech und Biaobei direkt verwenden. Laden Sie sie herunter und entpacken Sie sie in die data/binary/ Ordner.
Für Libritts können Sie die RAW -Datensätze herunterladen und mit unseren data_gen -Modulen verarbeiten. Detaillierte Anweisungen finden Sie in DOSC/PREAP_DATA.
Wir bieten das vorgebildete Modell von Vocoder für drei Datensätze. Insbesondere Hifigan für Ljspeech und Biaobei, Parallelwavegan für Libritts. Laden Sie sie in die checkpoints/ den Ordner herunter und entpacken Sie sie.
Dann können Sie Syntaspeech in den drei Datensätzen trainieren.
cd < the root_dir of your SyntaSpeech folder >
export PYTHONPATH=./
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset # training in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset # training in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset # training in LibriTTStensorboard --logdir=checkpoints/lj_synta
tensorboard --logdir=checkpoints/biaobei_synta
tensorboard --logdir=checkpoints/libritts_syntaCUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/lj/synta.yaml --exp_name lj_synta --reset --infer # inference in LJSpeech
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/biaobei/synta.yaml --exp_name biaobei_synta --reset --infer # inference in Biaobei
CUDA_VISIBLE_DEVICES=0 python tasks/run.py --config egs/tts/libritts/synta.yaml --exp_name libritts_synta --reset ---infer # inference in LibriTTS Audio -Beispiele im Papier finden Sie auf unserer Demo -Seite.
Wir bieten auch die Demo -Seite von Huggingface für LJSpeech. Probieren Sie dort Ihre interessanten Sätze!
@article{ye2022syntaspeech,
title={SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech},
author={Ye, Zhenhui and Zhao, Zhou and Ren, Yi and Wu, Fei},
journal={arXiv preprint arXiv:2204.11792},
year={2022}
}
Unsere Codes basieren auf den folgenden Repos:


